
检索增强型语言模型可以更好地适应世界状态的变化,并整合长尾知识。 然而,大多数现有方法只从检索语料库中检索较短的连续块,限制了对整体文档上下文的整体理解。 我们引入了一种新颖的方法,即递归地对文本块进行嵌入、聚类和摘要,自下而上构建一个具有不同摘要级别的树。 在推理时,我们的 RAPTOR 模型从这棵树中检索,整合不同抽象级别的长文档中的信息。对照实验表明,使用递归摘要的检索在多项任务上比传统的检索增强型 LLM 有显著的改进。 在涉及复杂、多步推理的问答任务中,我们展示了最先进的结果;例如,通过将 RAPTOR 检索与 GPT-4 的使用相结合,我们可以将 QuALITY 基准的准确率提高 20%。
论文地址:https://arxiv.org/abs/2401.18059
代码地址:https://github.com/parthsarthi03/raptor
Raptor是一种新的信息检索的方法,它的本质是检索树。主要是为了应对整合型问题相关的信息检索。目前现有的检索方式大部分只能检索零碎的连续文本,实际上NaiveRAG也确实在总结型、整合型的问题上表现堪忧,核心原因是因为这类问题一般需要主题理解类的知识,而在原始的chunk中一般是不存在这类知识的。
Raptor希望通过递归的经历嵌入、聚义、总结这三个阶段,对原始的chunks进行处理,实现一个包含不同粒度,不同语义跨度的信息树。它既包含原始切分的chunks,即零散的连续段落,也存在新增的总结性段落。通过这种方式,在检索阶段应对零散片段无法满足深语义查询的问题。
构建阶段
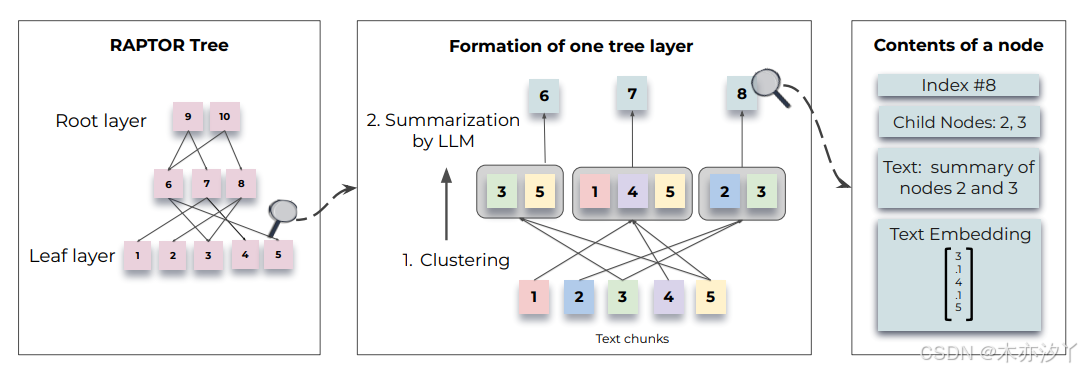
构建树的过程,RAPTOR 根据其语义Embedding递归地对文本块chunk进行聚类,并生成这些聚类的文本摘要。
RAPTOR 根据向量递归地对文本块进行聚类,并生成这些聚类的文本摘要,从而自下而上构建一棵树。 聚集在一起的节点是兄弟节点; 父节点包含该集群的文本摘要。这种结构使 RAPTOR 能够将代表不同级别文本的上下文块加载到 LLM 的上下文中,以便它能够有效且高效地回答不同层面的问题。
RAPTOR中使用的聚类算法是基于高斯混合模型(Gaussian Mixture Models, GMMs)。聚类后,每个聚类中的节点被发送到LLM进行概括。在实验中,作者使用 gpt-3.5-turbo 来生成摘要。摘要步骤将可能大量的检索信息压缩(summarization)到一个可控的大小。
检索阶段
查询有两种方法,基于树遍历(tree traversal)和折叠树(collapsed tree)。
-
树遍历:遍历是从 RAPTOR 树的根层开始,然后逐层查询。
- 从根节点出发,选取跟query向量余弦相似度相似的top-k个节点,记为S1;
- 再对S1的子节点进行相似度计算,一样选top-k个节点,记为S2;
- 持续这个过程,对S2也进行一样的操作,执行到叶子结点为止,构成S1、S2、S3...
- 将S1、S2、S3...合并,组装为上下文用于LLM回答。
-
折叠树:折叠树就是全部平铺,用ANN库查询。
折叠树更好理解了,其实就是把检索树“拍扁”了,将根节点和叶子结点都存在一个集合里,然后走NaiveRAG一样的检索方法,直接对这个集合里的所有元素进行余弦相似度计算,选出topk。
- 将整个 RAPTOR 树折叠成一个图层。这组新的节点(表示为 C)包含来自原始树的每一层的节点。
- 计算查询嵌入与折叠集合 C 中存在的所有节点的嵌入之间的余弦相似性。
- 选择与查询具有最高余弦相似度分数的前 k 个节点。继续向结果集添加节点,直到达到预定义的最大token数,确保不超过模型的输入限制。
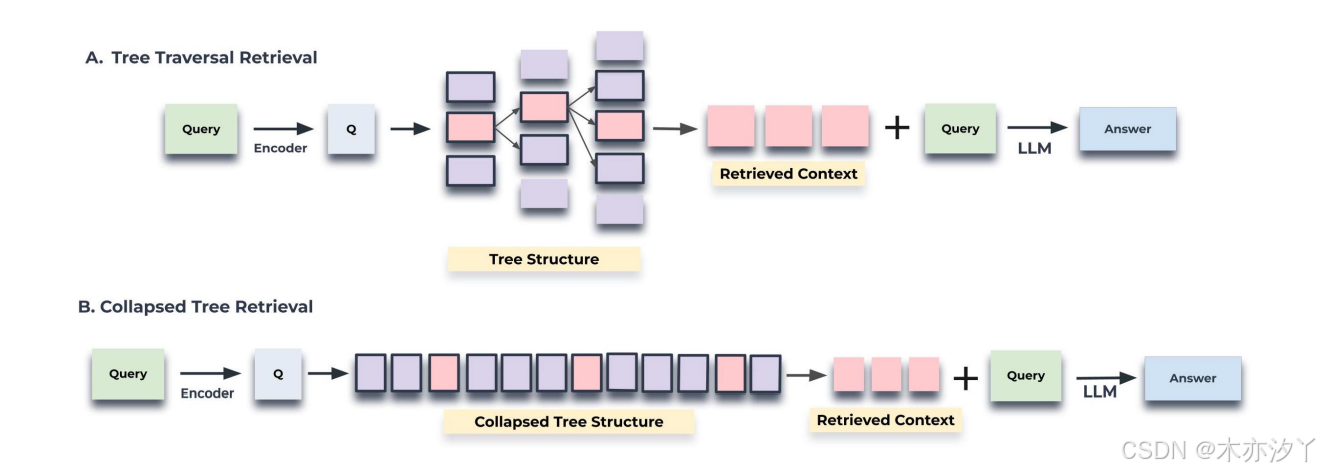
这两种检索方式,实现难度上,压缩树要简单的多,因为不需要实现树结构,实际上只需要一直给chunks里加后来的新生成的chunk即可。检索时间上,按照直觉来看应该是树遍历的时间复杂度比较低,因为是树结构,但实际上压缩树本身可以通过一些存储性的手段优化,比如Faiss等,也是向量存储常用的索引优化手段了,因此整体来看,压缩树效果更优秀。
RAGFlow-Raptor实现
RAGFlow中的实现其实是Raptor中的扁平检索(collapsed tree)的实现,所以不涉及树结构的建立,在实现和搜索上也较为简单,通过简单的条件循环即可做到。
代码路径:rag/raptor.py
import logging
import re
import umap
import numpy as np
from sklearn.mixture import GaussianMixture
import triofrom graphrag.utils import (get_llm_cache,get_embed_cache,set_embed_cache,set_llm_cache,chat_limiter,
)
from rag.utils import truncateclass RecursiveAbstractiveProcessing4TreeOrganizedRetrieval:def __init__(self, max_cluster, llm_model, embd_model, prompt, max_token=512, threshold=0.1):self._max_cluster = max_cluster #最大簇聚类数量,再选取最优簇类树时使用self._llm_model = llm_model #用于总结的大模型self._embd_model = embd_model #向量化模型self._threshold = threshold #高斯聚类阈值,高于这个阈值将被判为属于该类self._prompt = prompt #总结用的prompt,这里要求必须有cluster_contentself._max_token = max_token #最大token,这个会影响总结的效果和切分的段落数量,进而影响上下文async def _chat(self, system, history, gen_conf):response = get_llm_cache(self._llm_model.llm_name, system, history, gen_conf)if response:return responseresponse = await trio.to_thread.run_sync(lambda: self._llm_model.chat(system, history, gen_conf))response = re.sub(r"^.*</think>", "", response, flags=re.DOTALL)if response.find("**ERROR**") >= 0:raise Exception(response)set_llm_cache(self._llm_model.llm_name, system, response, history, gen_conf)return responseasync def _embedding_encode(self, txt):response = get_embed_cache(self._embd_model.llm_name, txt)if response is not None:return responseembds, _ = await trio.to_thread.run_sync(lambda: self._embd_model.encode([txt]))if len(embds) < 1 or len(embds[0]) < 1:raise Exception("Embedding error: ")embds = embds[0]set_embed_cache(self._embd_model.llm_name, txt, embds)return embdsdef _get_optimal_clusters(self, embeddings: np.ndarray, random_state: int):"""贝叶斯信息准则(BIC,Bayesian Information Criterion)来确定数据集 embeddings 中的最佳聚类数量方法通过对不同数量的聚类数进行高斯混合模型(GMM,Gaussian Mixture Model)拟合,选择使 BIC 最小的聚类数作为最佳聚类数params:embeddings: np.ndarray - 输入的嵌入向量数组。random_state: int - 确保模型训练结果的随机性控制变量。returns:optimal_clusters: int - 计算得出的最佳聚类数。"""max_clusters = min(self._max_cluster, len(embeddings))#从1到最大聚类数生成备选的n值n_clusters = np.arange(1, max_clusters)bics = []for n in n_clusters:#遴选n值,初始化高斯混合聚类,并进行聚类gm = GaussianMixture(n_components=n, random_state=random_state)gm.fit(embeddings)#计算bic值,添加到bicsbics.append(gm.bic(embeddings))#取bic值最小的索引,获得对应的n值optimal_clusters = n_clusters[np.argmin(bics)]return optimal_clustersasync def __call__(self, chunks, random_state, callback=None):#若chunk段数本身就小于1,直接跳过,不进行处理if len(chunks) <= 1:return []#剔除空的chunkchunks = [(s, a) for s, a in chunks if s and len(a) > 0]#分层层数,存储每层的chunk范围,比如[(0,3)(3,5)(5,6)]代表三层layers = [(0, len(chunks))]start, end = 0, len(chunks)async def summarize(ck_idx: list[int]):"""总结文本,生成一个摘要块。根据提供的索引 `ck_idx` 选择文本块,必要时进行截断,使用语言模型生成摘要。生成的摘要随后通过嵌入模型进行嵌入,并将摘要及其嵌入追加到 `chunks` 列表中。parms:- ck_idx (list): 要汇总的文本块的索引列表。- lock (threading.Lock): 用于确保对共享资源访问线程安全的锁对象。"""nonlocal chunkstexts = [chunks[i][0] for i in ck_idx]#计算每个文本的长度,保证能够均匀切分len_per_chunk = int((self._llm_model.max_length - self._max_token) / len(texts))cluster_content = "\n".join([truncate(t, max(1, len_per_chunk)) for t in texts])async with chat_limiter:cnt = await self._chat("You're a helpful assistant.",[{"role": "user","content": self._prompt.format(cluster_content=cluster_content),}],{"temperature": 0.3, "max_tokens": self._max_token},)cnt = re.sub("(······\n由于长度的原因,回答被截断了,要继续吗?|For the content length reason, it stopped, continue?)","",cnt,)logging.debug(f"SUM: {cnt}")embds = await self._embedding_encode(cnt)chunks.append((cnt, embds))labels = []#循环条件,指针距离大于1,也就是有超过1个的chunk没被聚类总结while end - start > 1:embeddings = [embd for _, embd in chunks[start:end]]#如果当前只剩两个,则不进行聚类算法(没必要),直接进行总结if len(embeddings) == 2:await summarize([start, start + 1])if callback:callback(msg="Cluster one layer: {} -> {}".format(end - start, len(chunks) - end))labels.extend([0, 0])layers.append((end, len(chunks)))start = endend = len(chunks)continue#UMAP的超参,局部连接的邻居数n_neighbors = int((len(embeddings) - 1) ** 0.8)#通过UMAP降维,减少后续计算量,避免维度灾难reduced_embeddings = umap.UMAP(n_neighbors=max(2, n_neighbors),n_components=min(12, len(embeddings) - 2),metric="cosine",).fit_transform(embeddings)#BIC选最优nn_clusters = self._get_optimal_clusters(reduced_embeddings, random_state)if n_clusters == 1:lbls = [0 for _ in range(len(reduced_embeddings))]else:#高斯聚类gm = GaussianMixture(n_components=n_clusters, random_state=random_state)gm.fit(reduced_embeddings)probs = gm.predict_proba(reduced_embeddings)#阈值判断,高于阈值则置1,说明归属此类lbls = [np.where(prob > self._threshold)[0] for prob in probs]#若有多个聚类,则以第一个为准lbls = [lbl[0] if isinstance(lbl, np.ndarray) else lbl for lbl in lbls]async with trio.open_nursery() as nursery:for c in range(n_clusters):#遍历标签,若归属于聚类中的某一类,则存入ck_idx,索引为i(标记位置)+start(偏移量)ck_idx = [i + start for i in range(len(lbls)) if lbls[i] == c]assert len(ck_idx) > 0#执行summaizenursery.start_soon(summarize, ck_idx)#断言扩充后的结果chunks长度-原始长度是否等于选定的n数,是否聚类了n类并总结assert len(chunks) - end == n_clusters, "{} vs. {}".format(len(chunks) - end, n_clusters)#层数扩充labels.extend(lbls)layers.append((end, len(chunks)))#回调处理状态if callback:callback(msg="Cluster one layer: {} -> {}".format(end - start, len(chunks) - end))#首尾指针重置,进入下一轮start = endend = len(chunks)return chunks值得一提的是,这里的label只取了第一个,也就是默认一个chunk只分类到一个簇里,这个实际跟论文的描述不太符合,论文描述中,一个chunk是可以隶属于多个簇的,属于简化版的实现了。
总结
- 有效提升
论文中的结论,在不同的数据集上测试,对比BM25和DPR,也就是稀疏向量和稠密向量检索,都是有提升的,具体数值来看分别提升5%和2%,实际上感觉和BM25混合使用应该会更好。
- 成本方面
粗略估计下额外成本,主要从时间和token两个角度。
时间上,主要还是构建索引阶段除了常规的切分chunk多了一个递归操作,还有可能的降维(一般是UMAP)、GM聚类和BIC。GM和BIC查了一下都不是耗时的算法(常数级别、主要看超参),主要还是在降维这块,UMAP已经算是比较不错的降维算法了,复杂度是NlogN,N是样本数量,也就是len(chunks),随着层数深入这个N应该会越来越小。
token成本方面,每层的构建都需要embedding和chat模型,但每层的聚类n都应该小于上一层的n(d-1),所以最差的情况下就是等差数列,count = (n*(1+n)) /2,但实际上应该收敛的比这个快的多,层数不会特别深,所以embedding的token成本应该在原来的1~2倍之间,另外总结部分的chat额外再加上一些len(chunks)左右的token成本。
这块可能还需要具体测试一下,收集一下数据看看,光靠计算比较难统计。
-
实现难度
树遍历实现起来比较复杂,折叠树性能好,实现起来简单,存储和检索都方便,首选折叠树。
-
适用场景
长一点的文本还是值得用一下Raptor的,主要是太长的话走成本会太高了,Raptor算是一个中间解,虽然效果肯定没有GraphRAG提升那么多,但成本要低得多,而且会有效提升。短文本就没必要Raptor了,有些浪费。


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

