25年5月来自上海智元机器人的论文“Genie Centurion: Accelerating Scalable Real-World Robot Training with Human Rewind-and-Refine Guidance”。
虽然视觉-语言-动作 (VLA) 模型在各种任务中展现出强大的泛化能力,但在现实世界中部署机器人策略仍然需要大规模、高质量的人类专家演示。然而,通过人类遥操作进行被动数据收集成本高昂、难以扩展,并且往往偏向于多样性有限的被动演示。为了解决这个问题,提出 Genie Centurion (GCENT),这是一种基于人类-回放-和-细化引导的规模化通用数据收集范例。当机器人执行失败时,GCENT 会通过回放机制使系统恢复到先前状态,之后远程操作员会提供纠正演示以细化策略。该框架支持一对多机器人的监督方案,并带有任务哨兵模块,该模块可以自主预测任务成功率并在必要时请求人工干预,从而实现可扩展的监督。实证结果表明,与最先进的数据收集方法相比,GCENT 的任务成功率最高可提高 40%,并且仅使用不到一半的数据即可达到相当的性能。还量化多机器人场景下的数据产出与努力比,证明 GCENT 在现实环境中进行可扩展且经济高效机器人策略训练的潜力。
数据集聚合 (DAgger) 算法 [46] 通过在策略自主执行过程中访问的状态下查询专家修正来提高数据效率。
其他方法包括模拟-到-现实迁移和离线强化学习 [26, 37, 39, 30]。然而,模拟-到-现实方法常常受到现实差距的影响,尤其是在接触丰富且精度较高的操作任务中,这些任务无法保证可靠的迁移。另一方面,离线强化学习方法受到分布偏移的限制,通常无法覆盖故障和恢复状态等关键区域。
GCENT,是一个受 DAgger 启发的数据收集框架,专为高效的现实世界机器人策略学习而设计。在这个范式中,人类操作员主要充当监护人的角色,仅在策略失败或即将失败时进行干预。GCENT 引入一种倒回机制,允许操作员将机器人重置到最近的有效状态,从而增强关键状态空间的多样性和覆盖率。GCENT如图所示:
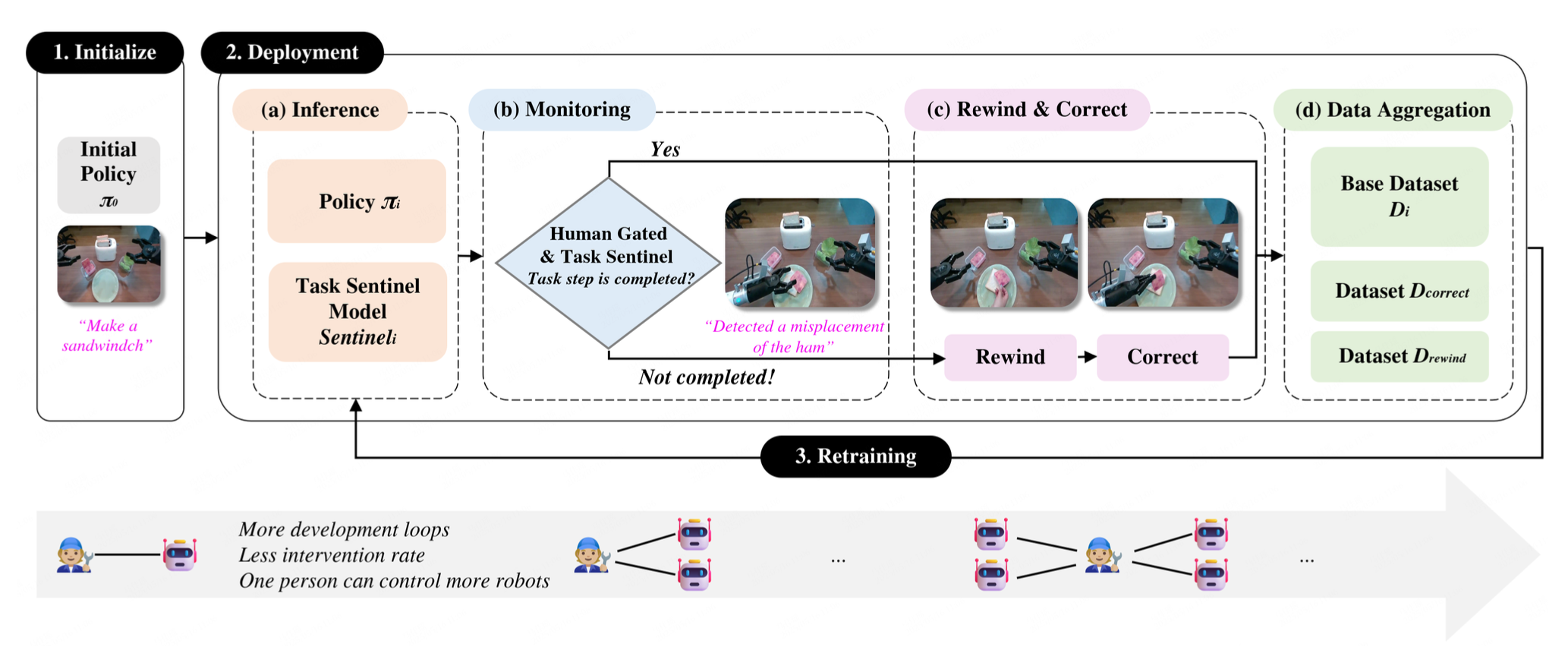
此外,GCENT 还集成任务哨兵模块,这是一个基于视觉-语言的模型,旨在自主检测任务完成状态并在必要时请求人工干预。这逐步减少了对持续人工监督的依赖。我们假设,与传统的持续远程操作方法相比,结构化的、由故障触发的人工干预能够显著提高数据效率,并加速机器人策略的优化。
本文设计并部署一个有效的数据采集系统,以支持 GCENT 学习范式。
硬件设置和遥操作
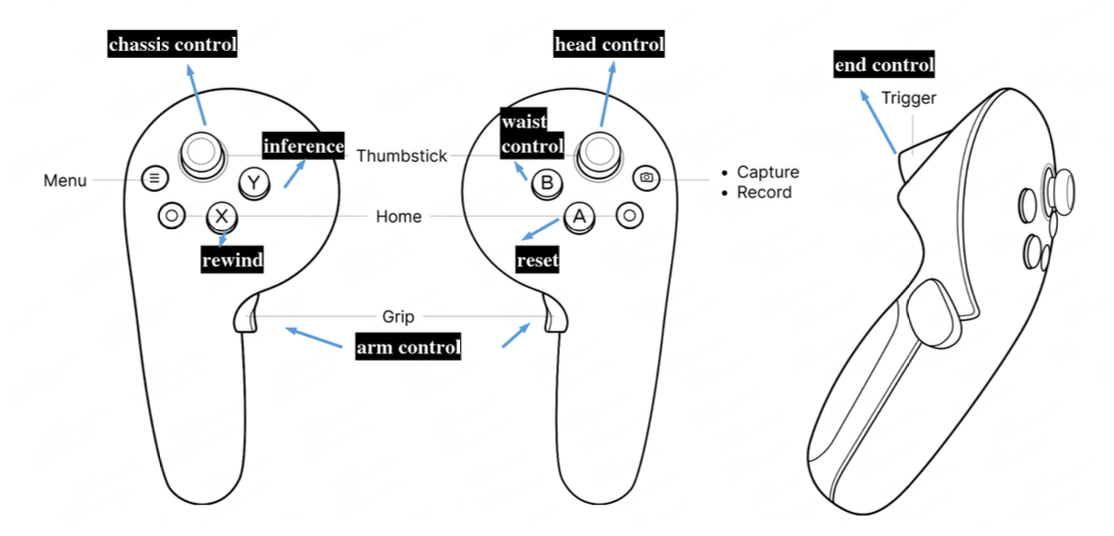
GCENT 数据采集系统基于 AgiBot G01[1] 机器人平台构建。操作员站采用 VR 系统,其中两个 6 自由度 VR 控制器分别用于控制机器人的双臂末端执行器,并执行干预和回放等操作。这种直观而精确的硬件界面使操作员能够在策略部署期间进行有效的监控和干预。
如图所示,系统为每个按键分配不同的操作。Y 按钮启动推理模式,在机器人上启动默认策略执行。X 按钮触发回放模式,将系统恢复到先前的时间点。侧爪启动接管模式,允许手动控制,以便进行人工演示或校正。 A 按钮用于重置系统,使机器人恢复初始姿态并结束当前数据采集。其他按钮用于控制机器人身体的其他部件。
GCENT 数据收集系统在一个持续迭代的数据循环中运行。它旨在通过在线交互逐步完善策略模型,目标是逐步降低干预率并提高成功率。
- 初始化:通过人工遥操作收集一小组种子数据 D_0,用于训练初始策略 π_0。
- 部署:此阶段包含四个关键步骤:
(a) 推理:机器人使用当前策略 π_i 和任务哨兵模型 Sentinel_i 自主执行任务。
(b) 监控:系统根据人工监督和来自任务哨兵模型的信号判断当前任务步骤是否完成。如果完成,则进入下一步;否则,请求倒回或干预。
© 回放和细化:这是 GCENT 的一项核心交互功能。它能够实现状态恢复和纠正演示。
(d) 数据聚合:任务完成或纠正后,有效轨迹数据,尤其是步骤 (2c) 中成功的纠正轨迹 D_correct,将聚合到数据集 D_i+1 中。 - 再训练:更新后的数据集 D_i+1 用于微调策略模型和任务哨兵模型,从而生成新版 π_i+1 和 Sentinel_i+1。这些更新后的模型随后被部署到机器人上,并重复部署周期(步骤 2)。此迭代过程持续进行,直到机器人能够自主完成任务并可靠地监控任务状态。
数据流水线记录机器人的实时数据,包括多视图观测值 (o_t)、关节状态 (joints_t)、策略操作、指令和其他模式标签。这些数据首先以 HDF5 格式保存在本地,然后进行验证,并上传到云端。在模型训练开始之前,云服务会对数据进行进一步处理,包括帧对齐、步骤标记、存储管理等。
GCENT 数据收集系统会自动将精确的模式标签记录到数据流中。共有四种模式:“干预”、“回放”、“推理”和“等待干预”。标记为“干预”的轨迹段(表示为 {(o_τ, ahuman_τ)})会被自动识别为用于训练 π_i 的高质量监督样本。“等待干预”模式由 Sentinel 自主确定。这种细粒度的标记使 GCENT 能够高效地捕获现实世界的交互数据,这些数据对于解决模型的弱点至关重要。
任务哨兵:基于多模态大语言模型的机器人步骤检测模型
除了人为干预外,还设计一种自主机制——任务哨兵,用于帮助机器人判断何时需要干预。该模型受[6]中奖励模型架构的启发,在时间 t 处以当前图像观测值 o_t 和任务指令 l_task 作为输入。该模型输出一个布尔值z_t,表示当前步骤的完成状态。
如果未在预定义时间 T_max(即 z_t = 0 且 ∆t > T_max)内完成,GCENT 将转换到“等待干预”模式,直到人工操作员进行干预。
与 DAgger [46] 等方法不同,不明确检测具体的失败时刻。这一决定源于准确识别失败实例的巨大挑战,尤其是在数据有限的情况下。错误的类型和频率在模型训练的不同阶段可能有所不同。相比之下,成功完成任务(或子任务)的定义仍然清晰稳定,这使得它更适合在 GCENT 范式下训练稳健的模型。
任务哨兵模型持续监控任务执行情况。任务被分解为原子操作步骤(例如,抓取、放置、推动、按压),人工注释者识别每个步骤的起始和结束帧。将成功执行步骤最后一秒内的帧标记为完成,而所有其他帧标记为未完成。这将任务哨兵模型的训练转换为二分类任务。
在部署过程中,将任务哨兵模型与人工监督(人机门控模式)相结合,以增强 GCENT 的数据收集效率。在人控模式下,操作员持续监控机器人的动作,并在发生任何错误时立即进行干预。在 GCENT 迭代的早期阶段,由于模型成功率较低,数据收集器主要在单个机器人上使用人控方法。随着迭代的进行和模型性能的提升,任务哨兵机制使单个操作员能够同时监控多个机器人,仅在必要时请求干预。任务哨兵是将 GCENT 方法扩展到单操作员多机器人系统的关键因素,可显著提高操作效率和系统安全性。
倒放和细化机制
如图所示,当任务哨兵请求干预,或者操作员决定干预时,操作员可以按下 X 按钮触发倒放操作。系统会在机器人自身上维护过去 3 秒的实时状态缓冲区。启动倒放模式后,系统会将机器人恢复到选定的历史状态 s_t-k。状态回溯后,操作员可以施加物理扰动,并提供细化演示。倒放和细化机制是 GCENT 的核心交互功能,可实现高效的恢复和精准的细化。

实验设置
基于 GO-1 具身基础模型 [1] 对策略 π 进行微调,并使用数千小时的机器人操作数据进行预训练。所有数据收集和评估均在 AgiBot G01 平台上进行。任务哨兵模型基于 InternVL 2.5 2B 主干网络 [7] 构建,并额外添加一个基于多层感知器 (MLP) 的二分类器头。
策略 π 仅使用来自 GCENT 数据的人为干预片段进行训练,而任务哨兵模型则使用完整的 GCENT 数据集进行训练。每次迭代使用 1 个 A800 节点对模型进行 100 个迭代 (epoch) 的微调,大约耗时 16 小时。为了确保实际相关性和任务多样性,根据实际应用设计四个任务。
• 三明治组装:八个连续的双手取放动作,将食材堆叠成三明治。
• 连接器插入:抓取元件并将其插入紧密的端子,需要精细且接触丰富的控制。
• 微波加热:完成微波加热任务需要五种不同的原子操作,包括拉、拾、放、推和按。
• 打字:使用小键盘输入文本,包括用于指令跟踪评估的退格键处理。
采用分批 DAgger 式迭代 [55]。每个任务首先通过被动数据收集获得 20 条轨迹,然后进行 4 次 GCENT 迭代,其中一次迭代包含 20 次演示,直到平均得分超过 0.9。在相同数据量下比较三种策略:(1)被动数据收集 (PDC),(2)对抗性数据收集 (ADC),以及(3)GCENT。任务完成 10 次试验,并以平均得分作为性能指标。1.0 分表示完全成功,而部分完成则获得相应分数。这种方法比二进制成功率提供更详细的衡量标准。
硬件设置
在所有实验中均使用 Genie-1 通用人形机器人。该机器人拥有 20 个自由度,包括 7 个自由度臂,每个臂可承载高达 5 公斤的重量,并配有腰部关节,用于俯仰和垂直运动。这些臂提供高精度控制,重复精度可达 ±0.1 毫米,能够可靠地执行长距离双手操作任务。
每个末端执行器配备一个 RGB-D 摄像头或一个鱼眼摄像头,以及一个六轴力传感器。头部包含一个额外的 RGB-D 和鱼眼摄像头阵列,可提供全场景感知。
训练细节
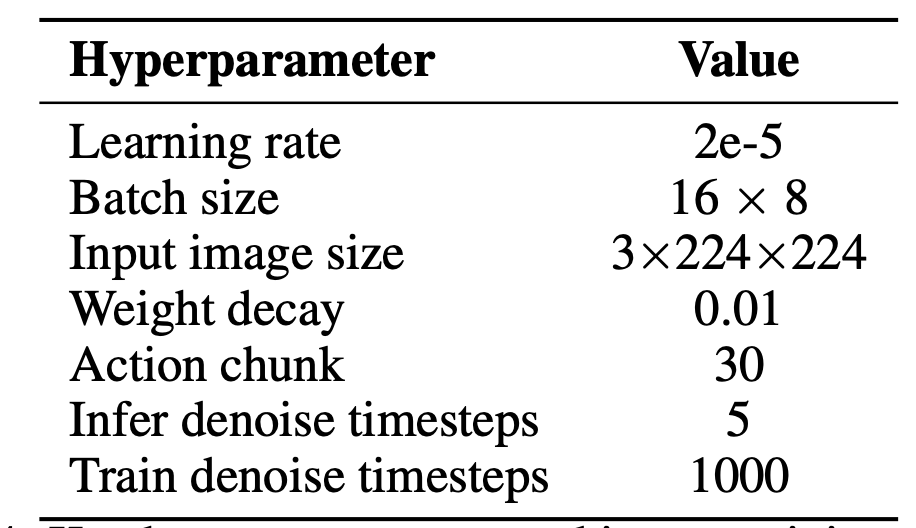
如下表为训练的超参数:
微调
为了优化计算效率并加速收敛,对训练流程进行三项方法学改进。首先,计算帧间关节角度差,并设定最小运动阈值(π/180/30 弧度)。表现出亚阈值角位移的帧,被归类为静态,随后从训练数据中排除。
其次,我们将原始关节角度测量值转换为末端执行器姿态表示。具体而言,基于正向运动学推导出连续帧之间的差姿态。这种基于相对姿态的表征为机器人操作任务提供更精确的动作参数化。
最后,对所有动作组件实施维度上的最小-最大归一化,将值限制在 [-1, 1] 区间内。这种标准化减轻不同动作维度之间异质缩放带来的不利影响,提高反向传播过程中梯度的稳定性,并促进了整个训练过程中更高效的优化动态。




