上一篇![]() https://blog.csdn.net/Small_entreprene/article/details/147992808?fromshare=blogdetail&sharetype=blogdetail&sharerId=147992808&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link
https://blog.csdn.net/Small_entreprene/article/details/147992808?fromshare=blogdetail&sharetype=blogdetail&sharerId=147992808&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link

我们之前的socket网络编程中,我们只知道我们打开一个文件就可以访问了,我们只停留在了socket编程层面上,那么其底层实什么?我们接下来就需要来学习网络原理!!!
传输层
我们之前的文章其实是按照自顶向下的,所以我们之前的所有工作都是在应用层的!那么应用层我们搞定之后,我们就往下走,也就是下一层 --- 传输层!
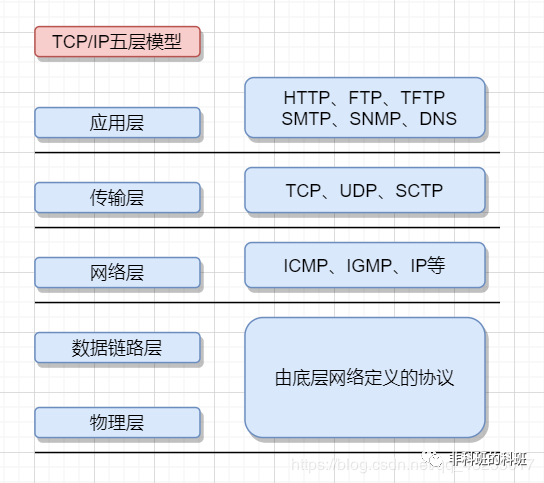
传输层就有代表性协议两个 --- UDP和TCP!
传输层的作用就是负责将数据由发送端发送到接收端,之前谈TCP说过,我们认识的read/write接口根本不是直接发送到网络中,然后直接从网络当中读取的,而只是将自己对应的用户缓冲区数据拷贝到TCP的操作缓冲区当中 ,也就是写个操作系统,至于这些数据什么时候发,发多少,由操作系统自己决定。
其实UDP也一样!其实当我们上层提供UDP接口时,使用sendto发送时,只是将要发送的报文数据(应用层HTTP报头+有效载荷),交付给下一层,交给对应的UDP层,所以由UDP将数据发送给对端。
在谈端口号
端口号(Port)表示了一个主机上进行通信的不同的应用程序;现在我们应该知道了,应用层有协议 --- HTTP,绑定端口80!有协议 -- FTP,绑定端口21......:
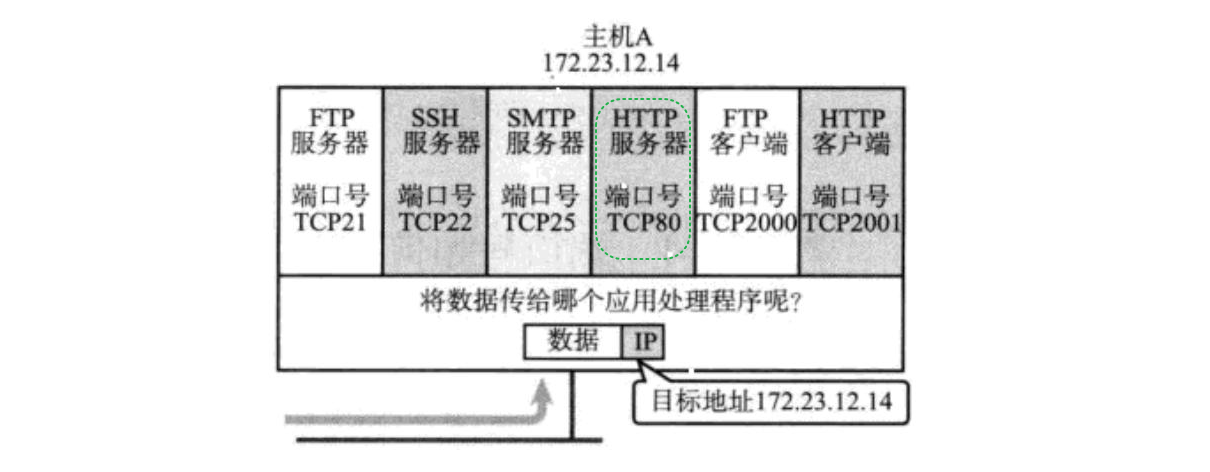
上图中,IP地址用来表明我当前需要将报文发送的目标主机,端口号用来将报文交给上层的哪一个目标应用!
所以在TCP/IP协议中,用 "源IP","源端口号","目的IP","目的端口号","协议号" 这样一个五元组来表示一个通信(可以通过netstat -n来查看);(我们之前的实验是可以拿到访问服务端的客户端的对应的IP和对应的端口的)
我们之前就说过网络通信本质就是进程间通信(源IP端口<--->目标IP端口)
网络通信确实可以看作是进程间通信(IPC),其中端口号在识别通信会话中起着关键作用。端口号与传输层协议(如TCP或UDP)结合使用,以唯一标识主机上的特定进程或服务。端口号是一个16位的数字,其取值范围是0到65535。端口号的分配有明确的规则:
-
公认端口(Well-Known Ports):从0到1023,通常为系统服务和广泛使用的应用程序保留,例如HTTP服务的80端口,HTTPS服务的443端口等。
-
注册端口(Registered Ports):从1024到49151,这些端口号被IANA注册,用于特定的服务。
-
动态端口(Dynamic Ports):从49152到65535,通常不由IANA控制,可以用于自定义服务或应用程序。
对于这些知名端口号,我们在服务器当中有配置文件,我们可以通过下列命令查看:
cat /etc/services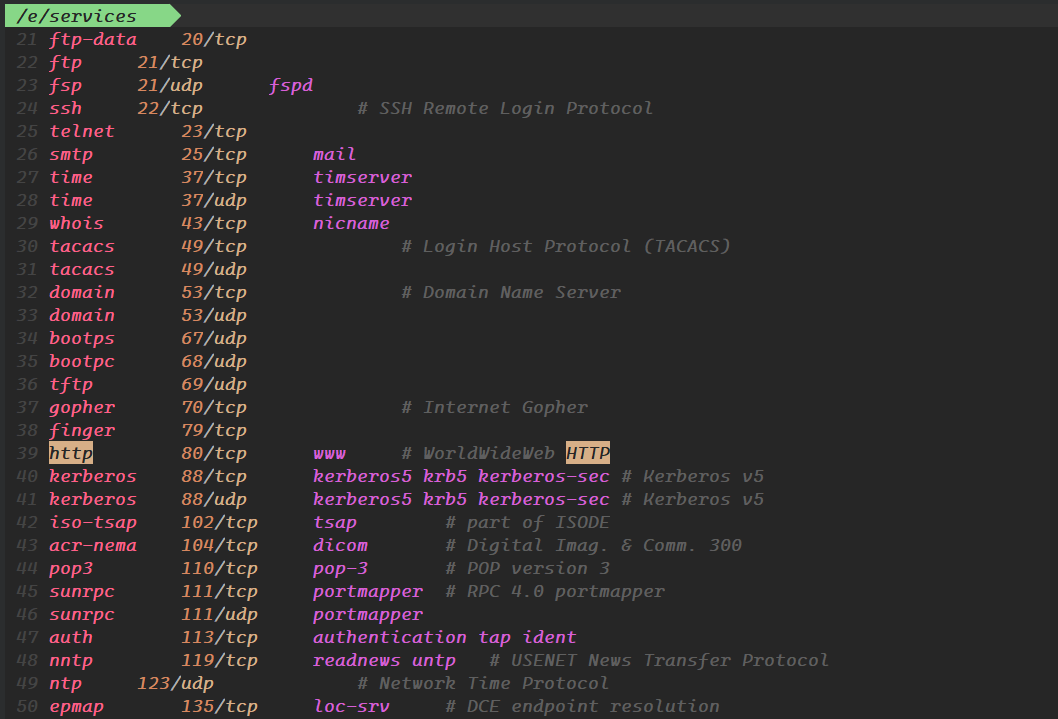
端口号与传输层协议(如TCP或UDP)是相互独立的,这意味着TCP和UDP可以各自使用相同的端口号而不会产生冲突。例如,TCP的80端口可以用于HTTP服务,而UDP的80端口可以用于其他服务。端口号的这种设计允许网络中的不同服务和应用程序通过相同的端口号在不同协议下运行,从而提高了端口的利用率并避免了冲突。
一个进程可以绑定多个端口号,一个端口号不能被多个进程绑定!!!
在网络通信中,数据包通过源IP地址、目标IP地址、协议类型、源端口号和目标端口号这五个数字来识别一个通信会话。这种设计确保了数据能够准确地从发送方传输到接收方的特定进程。
现在,让我们结合您提供的图来进一步说明这一点。图中展示了一个典型的网络通信场景,其中包括一个服务器和多个客户端。服务器的IP地址是172.20.100.32,它监听80端口(HTTP服务的标准端口)。客户端B和客户端A分别通过不同的端口(2001和2002)与服务器通信。
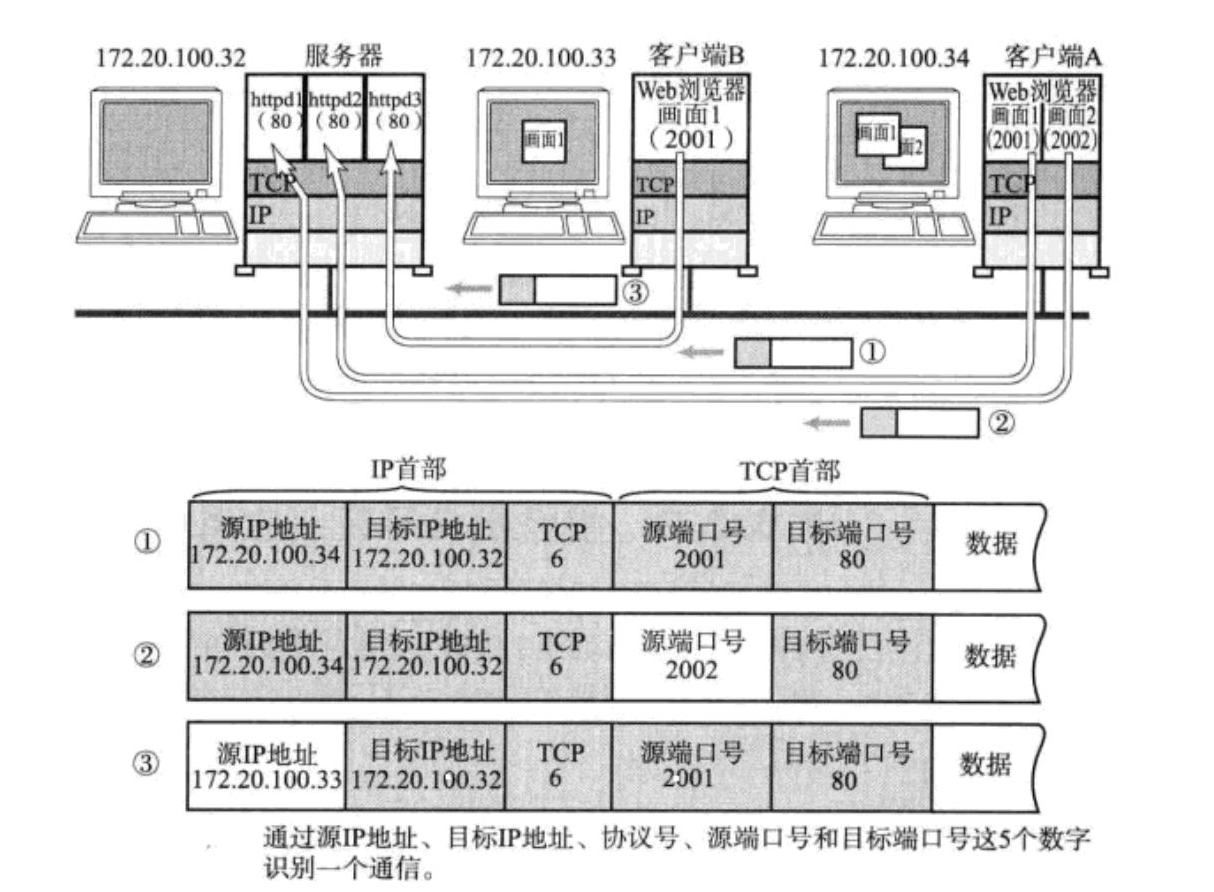
图中展示了三个TCP数据包的示例:
-
第一个数据包是从客户端B(IP地址172.20.100.34,端口2001)发送到服务器(IP地址172.20.100.32,端口80)的。
-
第二个数据包是从服务器(IP地址172.20.100.32,端口80)发送回客户端B(IP地址172.20.100.34,端口2001)的。
-
第三个数据包是从客户端A(IP地址172.20.100.33,端口2901)发送到服务器(IP地址172.20.100.32,端口80)的。
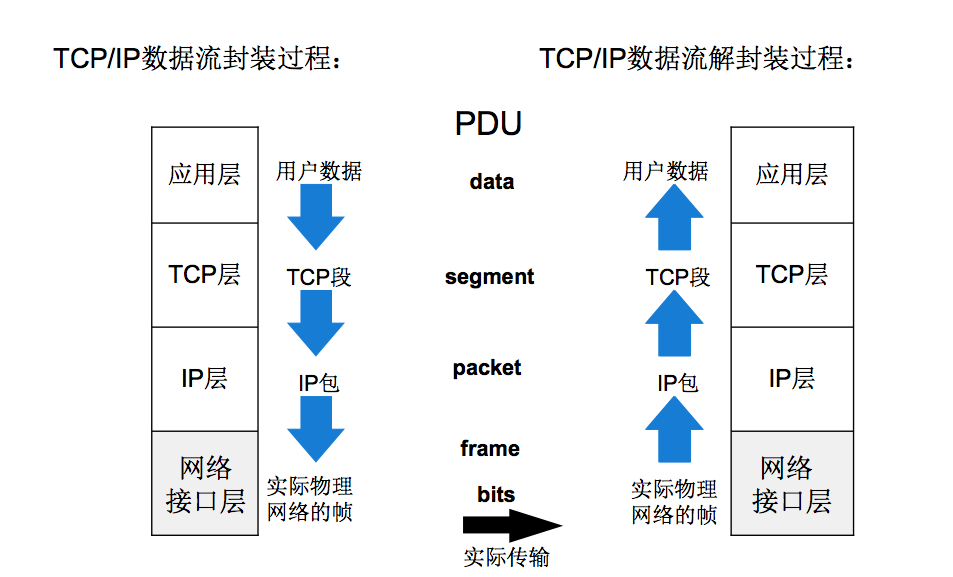
此时的数据是使用应用层协议,就比如说是HTTP的报头再加上其正文部分,也就是有效载荷,然后再向下添加对应的TCP报头和有效载荷,TCP/UDP的报头属性当中就会包含源端口和目标端口,所以我们之前看到的端口号,其实是在传输层当中的概念,后面还需要继续向下封装,在网络层添加IP的报头,其报头属性中就包含了源IP地址和目标IP地址了,还有协议号,该协议号是为了将来对端发送过来的报文中,自底向上分用的时候,可以根据协议号知道是要传给TCP还是UDP......
这些数据包的源IP地址、目标IP地址、协议号、源端口号和目标端口号这样的五元组共同标识了网络通信中的特定会话。通过这种方式,即使在网络中有多个客户端同时与服务器通信,每个通信会话也能够被正确地识别和管理。
UDP
UDP协议格式
不管是我们之前在应用层上实现的网络版本计算器,还是我们自己实现的服务端的HTTP,最终都是需要序列化称为字节流,应用层序列化成字节流后,就是形成了相关的报文,需要将报文交给下一层 --- 传输层,交付给下一层就需要添加报头 --- UDP报头,UDP的报头是一种传输层协议!
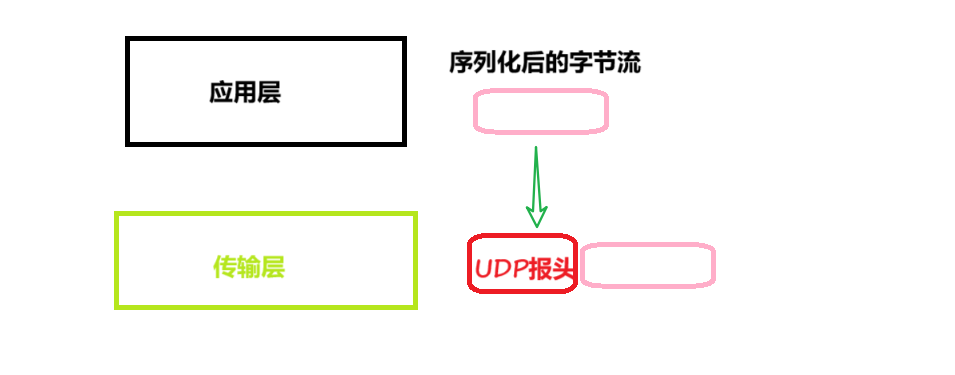
我们接下来来看看UDP协议端的格式:
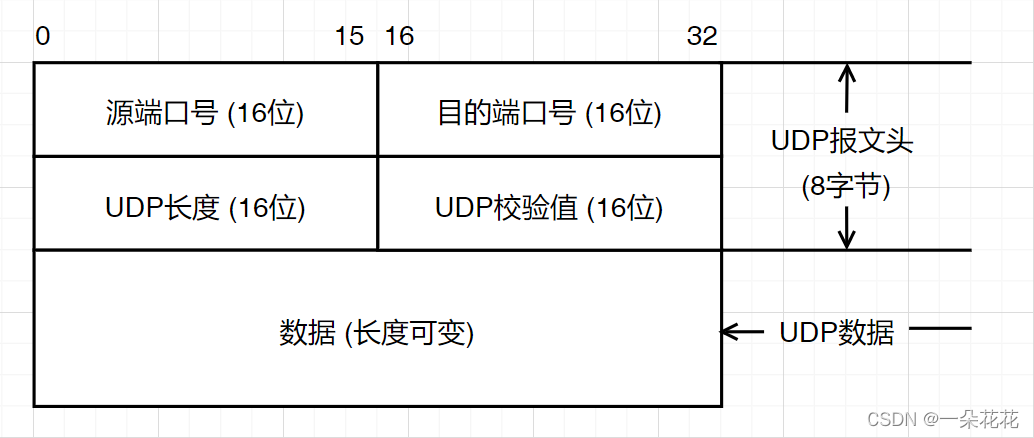
每个 UDP 报文分为 UDP 报头和 UDP 数据区两部分;
报头由 4 个 16 位长(2 字节) 字段组成,分别说明该报文的源端口、目的端口、报文长度和校验值;
UDP 报文中每个字段的含义:
- 源端口: 操作系统自动分配的,这个字段占据 UDP 报文头的前 16 位,通常包含发送数据报的应用程序所使用的 UDP 端口。接收端的应用程序利用这个字段的值作为发送响应的目的地址。这个字段是可选的,所以发送端的应用程序不一定会把自己的端口号写入该字段中。如果不写入端口号,则把这个字段设置为 0;这样,接收端的应用程序就不能发送响应了;
- 目的端口: 服务器提前准备好的端口,接收端计算机上 UDP 软件使用的端口,占据 16 位;
- 长度: 该字段占据 16 位(2字节),表示 UDP 数据报长度,包含 UDP 报文头和 UDP 数据长度,因为 UDP 报文头长度是 8 个字节,所以这个值最小为 8;
- 校验和: 该字段占据 16 位,可以检验数据在传输过程中是否被损坏;
UDP的特点
| 特点 | 描述 |
|---|---|
| 无连接 | UDP是无连接的协议,发送数据前不需要建立连接,知道对端的IP和端口号就可以直接传输。(和TCP不一样。TCP是在通信时需要先发起Connect,UDP并没有这个工作,服务器一起来就直接像UDP发送消息,直接sendto) |
| 不可靠 | UDP没有确认机制和重传机制。如果数据包在传输过程中丢失,UDP协议层不会给应用层返回错误信息。(我们目前还没有谈论可靠是怎么保证的)(不可靠是UDP的特点,不是缺点) |
| 面向数据报 | UDP是面向数据报的协议,每个UDP数据包都是一个独立的信息单元,协议不保证数据包的顺序和完整性。 |
| 传输效率高 | 由于UDP的简单性,它在传输数据时的开销较小,因此传输效率较高。 |
| 支持广播和组播 | UDP支持广播和组播,可以同时向多个接收者发送数据,适用于需要一对多通信的场景。 |
| 头部开销小 | UDP头部只有8字节,相比于TCP的20字节(不包括选项字段)要小,减少了传输的额外开销。 |
| 应用场景 | 适用于对传输速度要求高,但可以容忍一定丢包率的应用,如视频流、在线游戏、DNS查询等。 |
UDP的这些特点使得它在某些应用场景下非常适用,尤其是在需要快速传输且对丢包不敏感的情况下。然而,由于其不可靠性,UDP通常需要应用层来实现额外的确认和重传机制,以确保数据的可靠传输。
任何层协议都必须解决两种问题:
如何分离?
因为UDP采用的是8字节定长报头,后面对端传输层收到UDP报文之后,直接从整个报文的头部当中直接获取8字节,就是其UDP的报头,那么剩下的就是UDP的有效载荷!所以,我们就很简单的实现了UDP的报头和有效载荷的分离!!!反向的,我们就可以实现封装了!!!
如何分用?
UDP作为传输层协议,上一层就是应用层了,那么我们收到对端发送过来的UDP报文,该怎么知道将有效载荷传递给上一层的具体的哪一个协议呢?就是根据目的端口号!!!这就使我们之前使用sendto的时候,需要传参:server_socket和server_ip和server_port的原因!
面向数据报
在 UDP 协议中,数据是以数据报的形式传输的,每个 sendto 发送的数据对应一个完整的数据报。接收端必须一次 recvfrom 接收整个数据报,不能像 TCP 那样分多次接收。
具体来说:
-
发送端调用
sendto发送 100 字节,这 100 字节会作为一个完整的 UDP 数据报发送 -
接收端必须用足够大的缓冲区一次调用
recvfrom接收这 100 字节 -
不能分 10 次、每次 10 字节来接收,因为 UDP 是基于消息边界的协议
如果接收方的缓冲区小于 100 字节:
-
在大多数实现中,多余的数据会被丢弃
-
有些系统可能会返回错误(如 EMSGSIZE)
所以正确的做法是接收方的缓冲区至少要和发送的数据报一样大,并且准备一次接收整个数据报。
内核根据 UDP 协议的特性,在底层维护了消息边界,并通过 recvfrom 系统调用提供给应用程序。
所以端口号为什么是16位的?这不就是因为UDP的协议就是规定的16位嘛!
UDP凭什么叫做用户数据报?今天对端发送一个UDP,我这个接受方一定能够读到一个完整的UDP报文,因为UDP协议中有标识的16位UDP总长度,还有8字节的UDP报头长度,这样有效载荷是多少也就是很明了的了!也就是说:有效载荷的长度,在被读取的时候就是确定的了,这也就是报文和报文之间都是有边界的!!!
不像我们写TCP的这种面向字节流,其报文和报文的边界,我们在应用层的时候自己实现,而UDP不需要我们用户自己实现,因为在内核当中就可以分开了,所以UDP叫做面向数据报!!!
协议本质就是结构体呀!我们来看看什么是UDP协议!!!
UDP协议头在内核中的表示方式是通过udphdr结构体来定义的,该结构体包含四个字段:源端口、目标端口、数据包长度和校验和。这些字段与UDP头部的字段一一对应,用于在内核中处理UDP数据包时识别和解析数据包的各个部分。
struct udphdr {__u16 source; // 源端口__u16 dest; // 目标端口__u16 len; // 数据包长度__u16 check; // 校验和
};这个结构体的字段与UDP头部的字段一一对应。在内核中处理UDP数据包时,这些字段被用来识别和解析数据包的各个部分。
注意:操作系统之间,是直接传递结构体对象的!Windows和Linux都是C语言写的,双方定义的结构,结构体对齐和大小端问题全部都是处理好的了,操作系统不想做序列和反序列化,因为慢!!!
因为数据通常以字节流的形式在网络接口和内存之间传输。在C语言中,这些数据通常存储在缓冲区中,而缓冲区的地址由指针表示。操作系统和网络协议栈会使用这些指针来直接访问和操作数据。
UDP的缓冲区
我们之前看过TCP的发送缓冲区还有接收缓冲区:
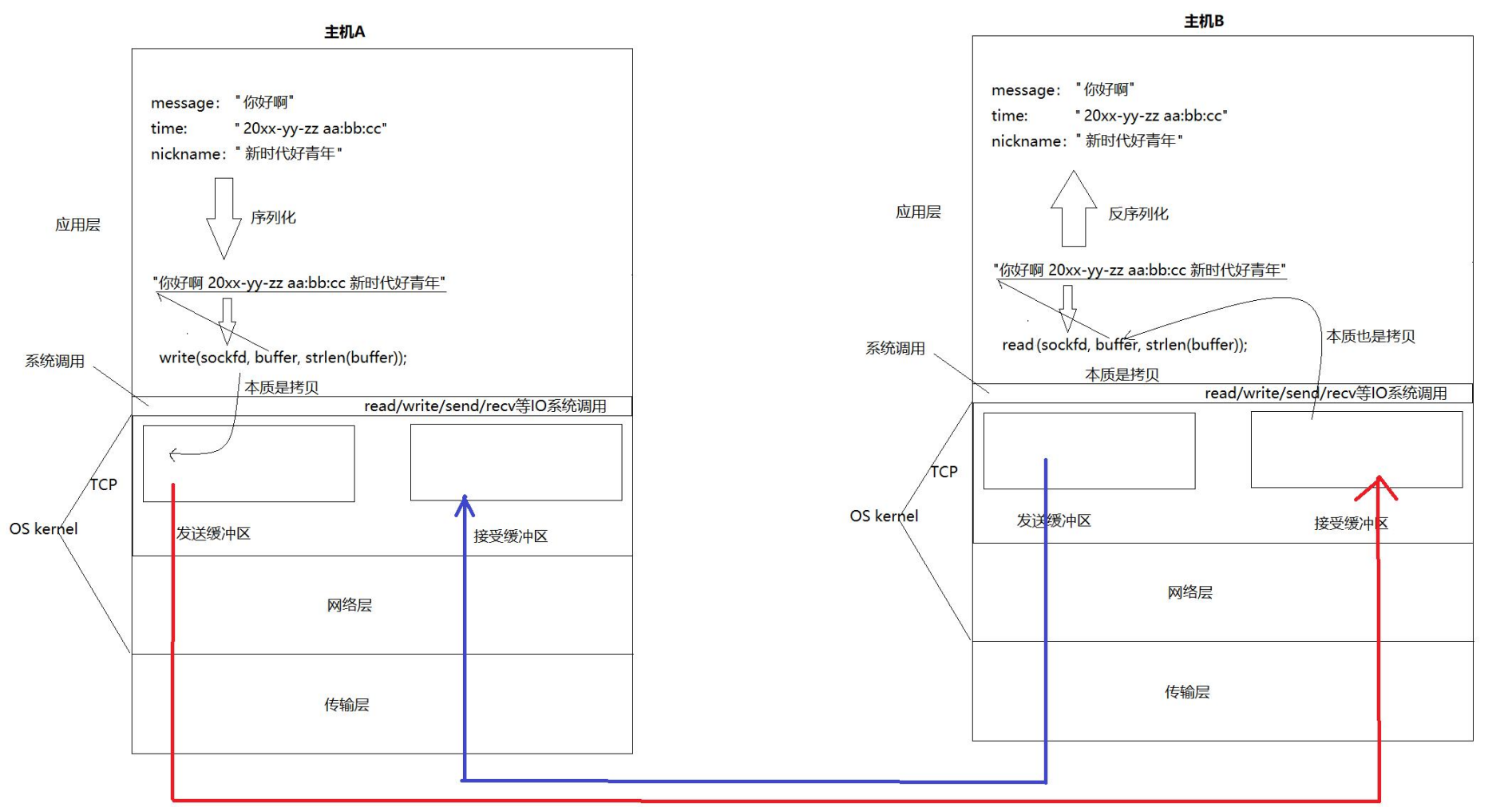
其实UDP没有真正意义上的发送缓冲区的,因为没有必要,当然也可以有,但是一般都不用:
- UDP 没有真正意义上的发送缓冲区。调用 `sendto` 会直接交给内核,由内核将数据传给网络层协议进行后续的传输动作。因为将UDP的数据缓存起来并没有任何意义,因为UDP不保证可靠性
举个例子就是,如果是TCP的,是由发送缓冲区的,如果发送的报文在网络中丢失的话,其实就是需要重传了,那么TCP在发送报文到网络的时候是不知道这个报文是否会丢包的,所以在TCP发送缓冲区在发送报文之后,该缓冲区的数据内容是不能被清楚的,不然拿什么去重传,反正丢了就丢了,我们可以重传呀,该缓冲区的相关数据内容是暂时需要保存起来的,在对端收到之后,发现报文完整,就将暂时缓存起来的数据内容清楚!
- UDP 具有接收缓冲区。但是这个接收缓冲区不能保证收到的 UDP 报的顺序和发送 UDP 报的顺序一致;如果缓冲区满了,再到达的 UDP 数据就会被丢弃。
因为在网络间通信的时候,上层,也就是应用层还需要对收到的报文进行序列化和反序列化,还有继续向上的路由,函数回调等等一大堆工作,说明上层也是很忙的!当读一个报文,上层在处理期间,我们就需要让我们的操作系用具备收取UDP报文的能力,所以操作系统提供一个接收缓冲区并不过分,也就是说上层在忙的时候,UDP的接收缓冲区也是可以缓存一些报文信息的,也是出于效率的考量,不过UDP接收缓冲区满了的话,再来一个报文也就将其丢掉了,这也就是为什么说UDP是一种不可靠协议!!!
- UDP 的 socket 既能读,也能写,这个概念叫做全双工。
UDP使用注意事项
我们注意到,UDP 协议首部中有一个 16 位的最大长度。也就是说一个 UDP 能传输的数据最大长度是 64K(包含 UDP 首部)。然而 64K 在当今的互联网环境下,是一个非常小的数字。如果我们需要传输的数据超过 64K,就需要在应用层手动的分包,多次发送,并在接收端手动拼装。
基于 UDP 的应用层协议:
-
NFS(网络文件系统):用于通过网络访问和管理远程文件系统,允许用户像访问本地文件系统一样访问远程文件。它通常用于局域网中的文件共享,支持多种操作系统。
-
TFTP(简单文件传输协议):一种轻量级的文件传输协议,主要用于在小型设备(如路由器或交换机)之间传输文件。它简单易用,但功能有限,不支持复杂的文件操作。
-
DHCP(动态主机配置协议):用于自动分配 IP 地址和其他网络配置参数给网络设备。它大大简化了网络管理,尤其是在大型网络环境中,能够动态地为设备分配 IP 地址,避免手动配置的繁琐。
-
BOOTP(启动协议,用于无盘设备启动):主要用于无盘设备(如无盘工作站)的启动过程,允许设备从网络上获取启动信息和操作系统映像,从而实现无盘启动。
-
DNS(域名解析协议):用于将域名(如
www.example.com)解析为 IP 地址(如192.0.2.1),是互联网中不可或缺的基础服务,使得用户可以通过易于记忆的域名访问网站和服务。
当然,也包括我们自己写的 UDP 程序时自定义的应用层协议。这些自定义协议可以根据特定需求设计,用于实现特定功能,如实时通信、游戏数据传输等。
报文的理解
如果应用层正在进行报文的解析,处理等,占用CPU的时候,会不会影响OS从网络中读取报文?为什么?
不会影响的!!!
- 其实网卡里面一旦有数据,网卡会向操作系统特定的CPU针脚触发硬件中断,这个硬件中断属于外设的硬件中断,操作系统就需要转而去执行中断所对应的中断向量表当中的方法,去读取外设当中的数据,这是操作系统的工作!
- 外设也在不断的向CPU触发时钟中断,来触发对应进程能够调度起来!
所以整个系统就是不断的由大量的外设来驱动对应的CPU,要么在执行调度,要么在执行操作系统的代码,其实当应用层正在进行报文的解析,处理等,占用CPU的时候,是操作系统在不停的响应时钟中断,在做进程的调度与运行,在不断响应时钟中断的同时,也在不断的响应着外设的外部中断,最终我们操作系统就可以既能把他做了,也能把你做了!!!
客户端 : 服务器 = n : 1!这不就意味着将来在OS内部,一定有可能会同时存在大量的报文,而这些报文就需要被管理起来 --- 先描述,再组织!!!
struct sk_buff 数据结构
struct sk_buff 是 Linux 内核中用于表示网络数据包的核心结构体,它不仅存储数据包的内容,还包含大量用于网络协议栈处理的元数据。以下是其主要字段的定义和说明:
struct sk_buff {union {struct {struct sk_buff *next; // 指向下一个 sk_buff 的指针,用于链表操作struct sk_buff *prev; // 指向前一个 sk_buff 的指针,用于链表操作union {ktime_t tstamp; // 时间戳,记录数据包的接收或发送时间struct skb_mstamp skb_mstamp; // 用于精确时间戳的结构体};};struct rb_node rbnode; // 红黑树节点,用于在某些情况下组织 sk_buff};struct sock *sk; // 指向关联的套接字结构体(如果有的话)struct net_device *dev; // 指向关联的网络设备结构体(如网卡)char cb[48] __aligned(8); // 控制块,用于存储协议栈内部的控制信息unsigned long _skb_refdst; // 用于路由目的的引用计数void (*destructor)(struct sk_buff *skb); // 当 sk_buff 被销毁时调用的回调函数
#ifdef CONFIG_XFRMstruct sec_path *sp; // 安全路径结构体,用于安全协议(如 IPsec)
#endifunsigned int len, data_len; // 数据包总长度和分片数据长度__u16 mac_len, hdr_len; // MAC 头长度和网络头长度kmemcheck_bitfield_begin(flags1); // 开始标志字段__u8 cloned:1, // 是否是克隆的 sk_buffnohdr:1, // 是否没有头部(用于某些特殊操作)fclone:2, // 克隆类型peeked:1, // 是否被偷窥(peeked)head_frag:1, // 是否头部是分片的xmit_more:1, // 是否还有更多数据要发送__unused:1; // 未使用的位kmemcheck_bitfield_end(flags1); // 结束标志字段__u8 pkt_type:3, // 数据包类型(如入站、出站等)pfmemalloc:1, // 是否由内存分配失败触发ignore_df:1, // 是否忽略 DF(Don't Fragment)标志nfctinfo:3; // 网络连接跟踪信息__u8 nf_trace:1, // 是否启用 Netfilter 跟踪ip_summed:2, // IP 校验和计算方式ooo_okay:1, // 是否允许乱序处理l4_hash:1, // 是否有四层哈希sw_hash:1, // 是否有软件哈希wifi_acked_valid:1, // WiFi ACK 是否有效wifi_acked:1; // WiFi 是否已确认__u8 no_fcs:1, // 是否禁用 FCS(Frame Check Sequence)encapsulation:1, // 是否有封装encap_hdr_csum:1, // 是否有封装头校验和csum_valid:1, // 校验和是否有效csum_complete_sw:1, // 是否有完整的软件校验和csum_level:2, // 校验和级别csum_bad:1; // 校验和是否错误__u8 ndisc_nodetype:2, // NDISC 节点类型ipvs_property:1, // 是否有 IPVS 属性inner_protocol_type:1, // 内部协议类型remcsum_offload:1; // 是否启用远程校验和卸载__u8 offload_fwd_mark:1; // 卸载转发标记__u16 queue_mapping; // 队列映射信息__wsum csum; // 校验和__u32 priority; // 数据包优先级int skb_iif; // 数据包进入的接口索引__u32 hash; // 数据包哈希值__be16 vlan_proto; // VLAN 协议类型__u16 vlan_tci; // VLAN 标签控制信息union {unsigned int napi_id; // NAPI ID,用于软中断处理unsigned int sender_cpu; // 发送 CPU 标识};__u32 secmark; // 安全标记union {__u32 mark; // 数据包标记__u32 reserved_tailroom; // 预留尾部空间};union {__be16 inner_protocol; // 内部协议__u8 inner_ipproto; // 内部 IP 协议};__u16 inner_transport_header; // 内部传输层头部偏移__u16 inner_network_header; // 内部网络层头部偏移__u16 inner_mac_header; // 内部 MAC 头部偏移__be16 protocol; // 数据包协议类型__u16 transport_header; // 传输层头部偏移__u16 network_header; // 网络层头部偏移__u16 mac_header; // MAC 头部偏移sk_buff_data_t tail; // 数据尾部指针sk_buff_data_t end; // 数据结束指针unsigned char *head, *data; // 数据头部和当前数据指针unsigned int truesize; // 数据包实际大小(包括头部和尾部)atomic_t users; // 引用计数,用于跟踪数据包的使用情况
};struct sk_buff 是 Linux 内核网络栈中用于表示网络数据包的核心结构体,它从数据链路层开始就存在,并贯穿整个网络协议栈的处理过程,直到数据被发送出去或被应用程序接收。
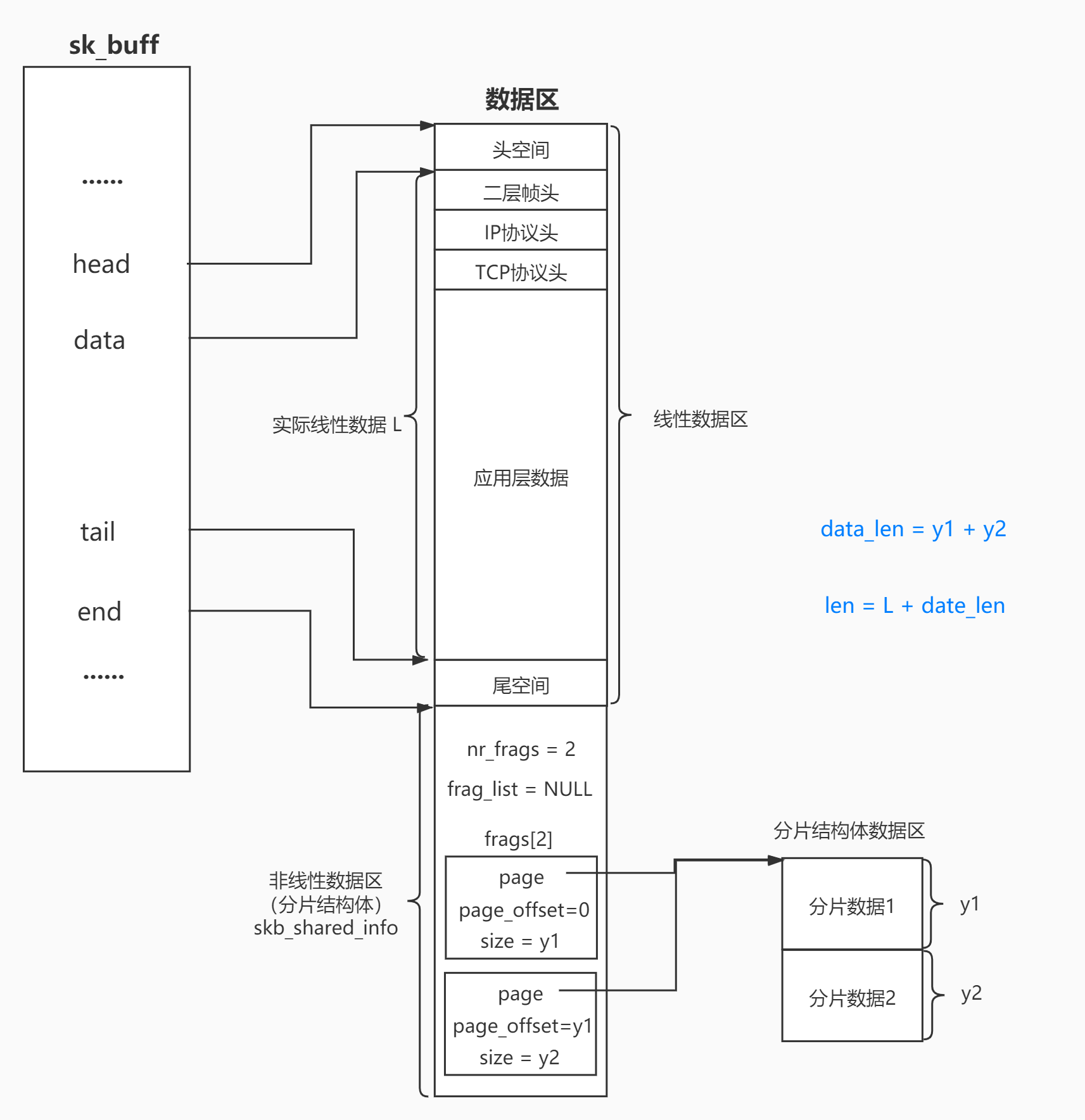
这不就是和我们的进程PCB很像了嘛😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭😭
所谓的封装和解包,本质就是移动data指针在缓冲区的位置,就是在加减对应层的协议长度(报头)!!!
比如:封装:
data -= sizeof(struct udphdr);
(struct udphdr*)data->......分用的时候也是类似,然后将对应的有效载荷放入到接收缓冲区当中!




