本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
一、分析式AI基础与深度学习核心概念
1.1 深度学习三要素
数学基础:
f(x;W,b)=σ(Wx+b)(单层感知机)
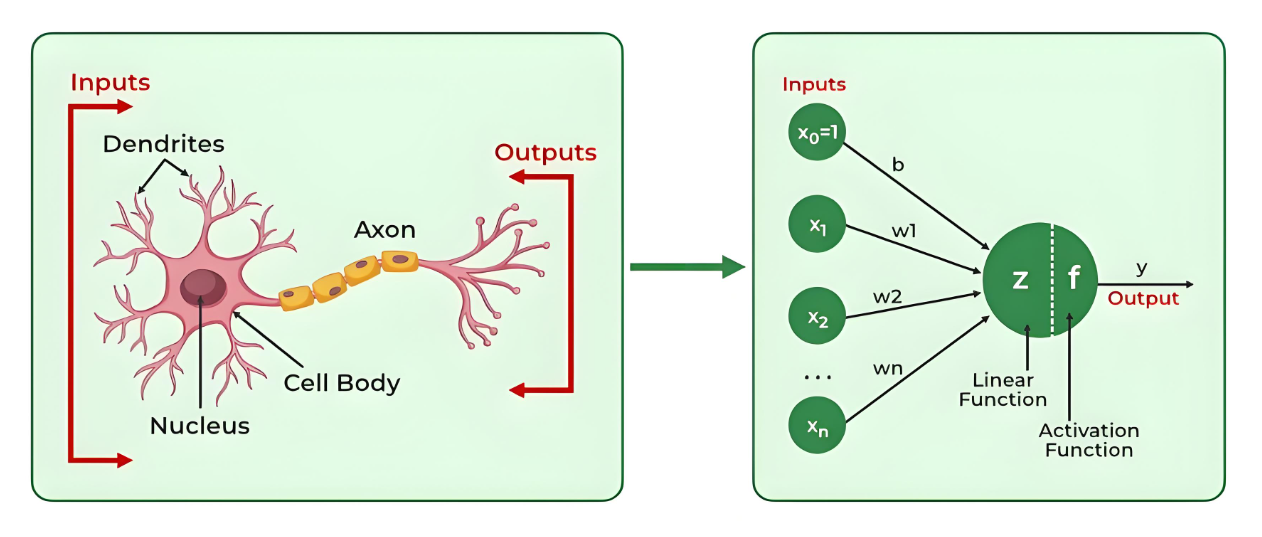
1.2 PyTorch核心组件
张量操作示例:
import torch
# 自动微分演示
x = torch.tensor(3.0, requires_grad=True)
y = x**2 + 2*x
y.backward()
print(x.grad) # 输出:8.0模型构建模板:
class MLP(nn.Module):def __init__(self, input_size, hidden_size, output_size):super().__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, output_size)def forward(self, x):return self.fc2(self.relu(self.fc1(x)))二、深度网络关键问题解析
2.1 参数量计算方法
全连接层计算:
Params=(input_dim+1)×output_dim
卷积层计算:
Params=(kernel_w×kernel_h×in_channels+1)×out_channels
代码验证:
model = nn.Sequential(nn.Conv2d(3, 16, 3), # (3*3*3+1)*16=448nn.Linear(256, 10) # (256+1)*10=2570
)
print(sum(p.numel() for p in model.parameters())) # 输出:30182.2 学习率影响分析
不同学习率对比:
学习率搜索代码:
lr_range = [1e-5, 1e-4, 1e-3, 1e-2]
for lr in lr_range:optimizer = torch.optim.SGD(model.parameters(), lr=lr)# 训练并记录损失曲线...2.3 梯度下降数学原理
泰勒展开视角:
f(x+Δx)≈f(x)+∇f(x)TΔx
当取$\Delta x = -\eta \nabla f(x)$时:
f(x+Δx)≈f(x)−η∥∇f(x)∥2
优化可视化:
# 二维函数优化轨迹绘制
def f(x,y): return x**2 + 10*y**2
x_vals = np.linspace(-5,5,100)
y_vals = np.linspace(-5,5,100)
X, Y = np.meshgrid(x_vals, y_vals)
Z = f(X,Y)
plt.contour(X,Y,Z, levels=20)
# 叠加梯度下降路径...三、典型问题深度解析
3.1 梯度下降变体对比

代码实现对比:
# 不同优化器训练曲线对比
optimizers = {"SGD": torch.optim.SGD(params, lr=0.1),"Momentum": torch.optim.SGD(params, lr=0.1, momentum=0.9),"Adam": torch.optim.Adam(params, lr=0.001)
}3.2 训练停滞解决方案
问题诊断清单:
检查数据流(数据增强是否合理)
监控梯度范数(torch.nn.utils.clip_grad_norm_)
学习率动态调整(ReduceLROnPlateau)
学习率调度示例:
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5
)
for epoch in range(100):train(...)val_loss = validate(...)scheduler.step(val_loss)3.3 网络容量与泛化
VC维度理论:
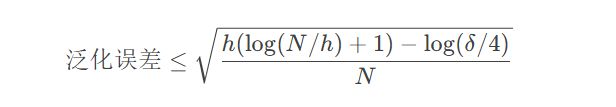
其中$h$为模型复杂度,$N$为样本数
实验验证:
# 不同深度网络对比实验
depths = [3, 5, 10]
for depth in depths:model = DeepNet(depth=depth)train_acc, test_acc = evaluate(model)print(f"Depth {depth}: Train {train_acc:.2f}% Test {test_acc:.2f}%")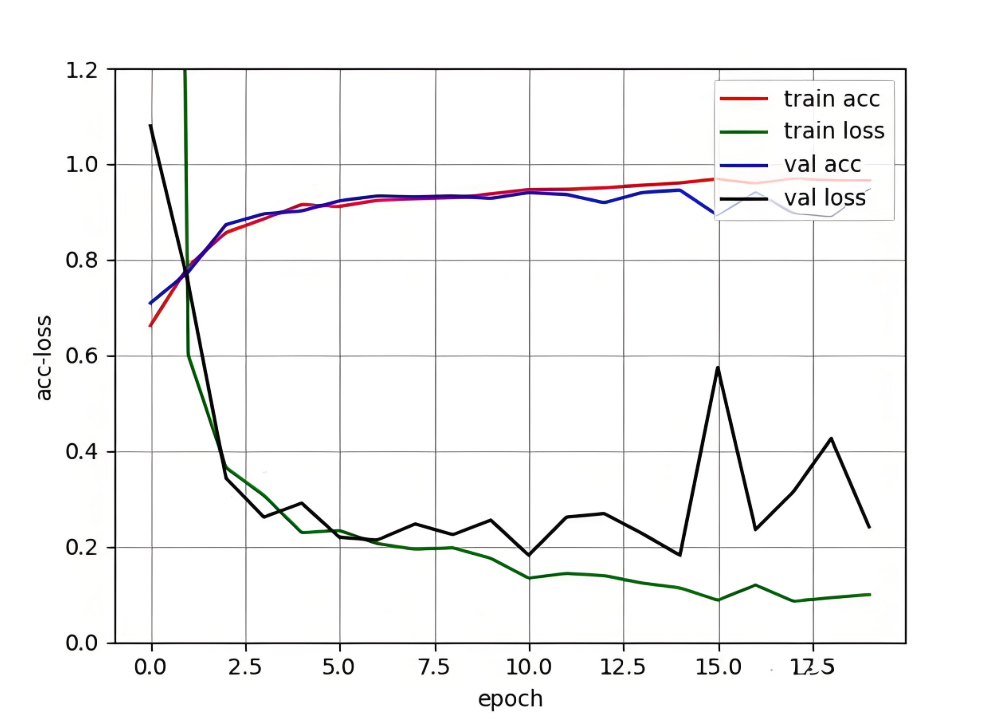
四、工业级最佳实践
4.1 分布式训练加速
DataParallel示例:
model = nn.DataParallel(model.cuda(), device_ids=[0,1,2])
for data in dataloader:inputs, labels = dataoutputs = model(inputs.cuda())loss = criterion(outputs, labels.cuda())loss.backward()optimizer.step()4.2 混合精度训练
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for inputs, labels in dataloader:with autocast():outputs = model(inputs)loss = criterion(outputs, labels)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()4.3 模型量化部署
# 动态量化
model = torch.quantization.quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8
)
# 保存量化模型
torch.jit.save(torch.jit.script(model), "quantized_model.pt")更多大模型应用开发学习视频和资料,尽在聚客AI学院。


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

