目录
一、数据可视化
1.1 单一图表
1.1.1 直方图
1.1.2 密度图
1.1.3 箱线图
1.2 多重图表
1.2.1 相关矩阵图
1.2.2 散点矩阵图
二、数据预处理
2.1 为什么需要数据预处理
2.2 数据清洗
2.2.1 错误值处理
2.2.2 缺失值处理
2.2.3 异常值处理
2.2.4 重复值处理
2.3 数据降维
2.3.1 数据降维的原理
2.3.2 常见的数据降维方法
2.3.2.1 主成分分析(PCA)
2.3.2.2 线性判别分析(LDA)
2.3.2.3 t-SNE
2.4 数据变换
2.4.1 数据整合
2.4.2 数据规范化
2.4.3 数据标准化
2.5 数据集成
在机器学习领域,算法的有效运行往往依赖于对数据分布的合理假设。通过将数据拟合到特定的概率分布,我们能够更好地组织和预处理数据,从而为后续的模型训练奠定基础。本文将重点介绍如何使用scikit-learn工具包进行数据预处理,这些处理后的数据可以直接应用于各类机器学习算法。我们将系统地讲解几种常用的数据整理技术和方法:
- 调整数据尺度(Rescale Data)
- 正态化数据(Standardize Data)
- 标准化数据(Normalize Data)
- 二值数据(Binarize Data)
一、数据可视化
现在介绍如何通过Matplotlib来可视化数据,让我们加强对数据的理解,便于对数据进行预处理。
Matplotlib是一个用于绘制图形的Python库,它可以用于创建各种类型的图表,包括折线图、散点图、柱状图、饼图等。通过可视化数据,我们可以更直观地掌握数据的特征和规律,有助于分析数据、发现数据间的关系,并进一步进行数据预处理和分析。
1.1 单一图表
在Matplotlib中,最基本的图表是单一图表,也称为坐标系。每个单一图表都包含一个或多个数据系列,可以通过添加数据点、设置样式和添加标签来定制图表的外观。
创建一个简单的Matplotlib单一图表通常包括以下步骤:
- 导入Matplotlib库
- 创建数据
- 绘制图表添加标题、坐标轴标签和图例
- 显示图表
1.1.1 直方图
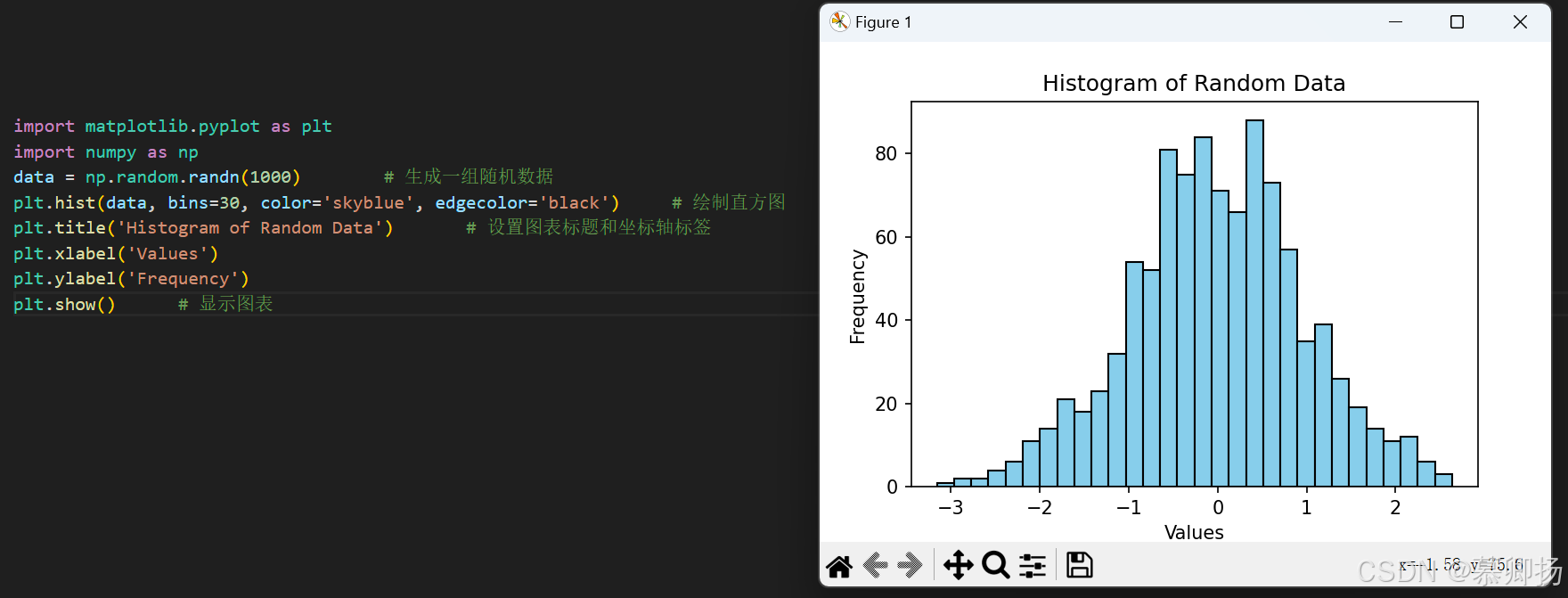
直方图通过将数据分成若干个小的区间(称为“bin”),并统计每个区间中数据的频数或密度来展示数据的分布。通常用于展示连续数据的分布,比如表示一组数值数据的分布情况。可以使用plt.hist()函数来绘制直方图。
我们生成一组随机数据,并使用plt.hist()函数绘制直方图:
我们把印第安人糖尿病数据集(pima_data.csv)的各项数据用直方图可视化出来,代码如下:
from pandas import read_csv
import matplotlib.pyplot as plt
filename = 'Sklearn\pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names = names)
data.hist()
plt.show()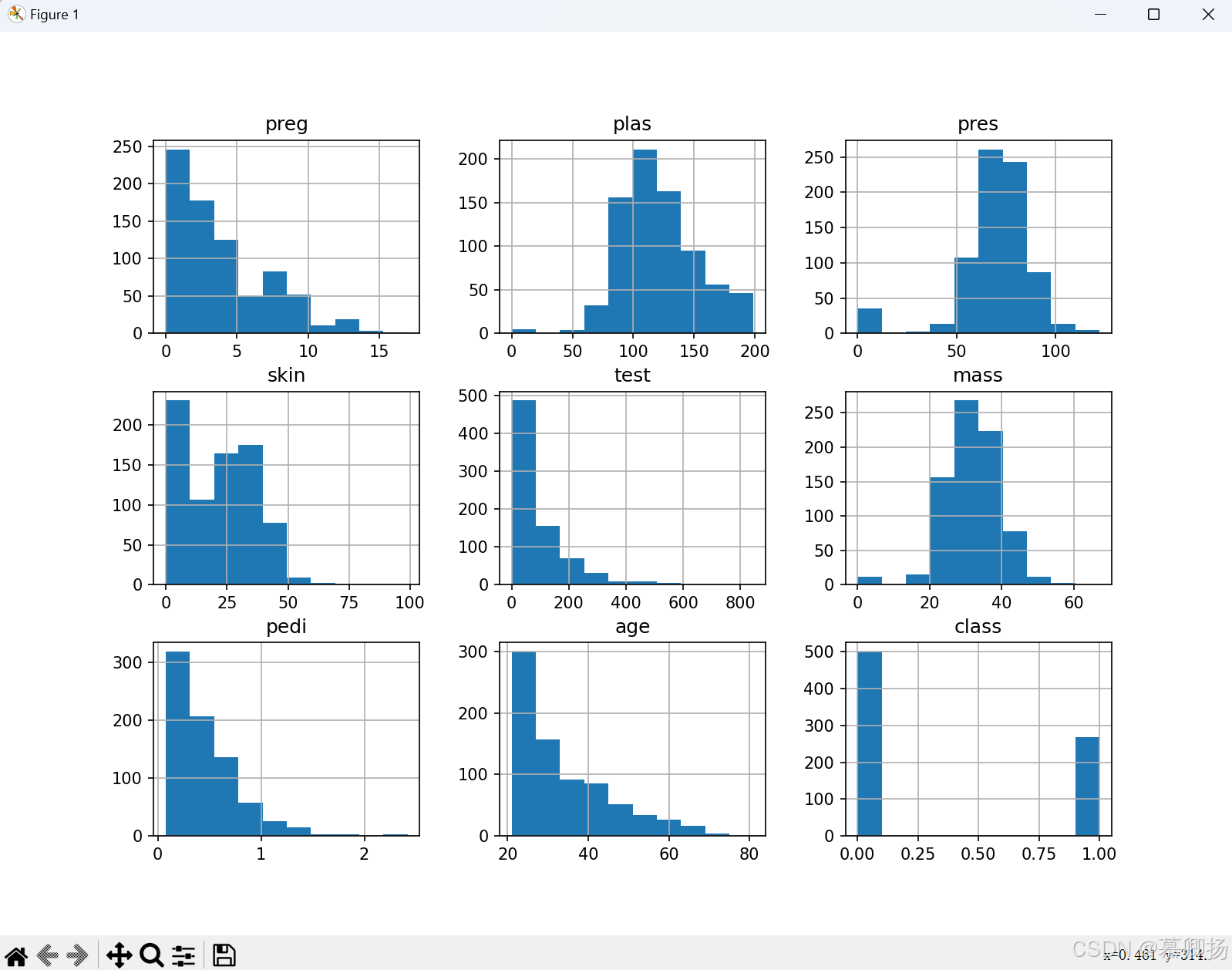
1.1.2 密度图
密度图是一种展示数据分布情况的图表,通过将数据点在数轴上的位置进行核密度估计,绘制出反映概率密度的曲线图形。密度图可以帮助我们更直观地了解数据的分布形态,发现数据的聚集区域和趋势。
在Matplotlib中,可以使用plt.plot()或plt.fill_between()等函数绘制密度图。把印第安人糖尿病数据集(pima_data.csv)的各项数据用密度图可视化出来,代码如下:
from pandas import read_csv
import matplotlib.pyplot as plt
filename = 'Sklearn\pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names = names)
data.plot(kind='density', subplots = True, layout=(3,3), sharex=False)
plt.show()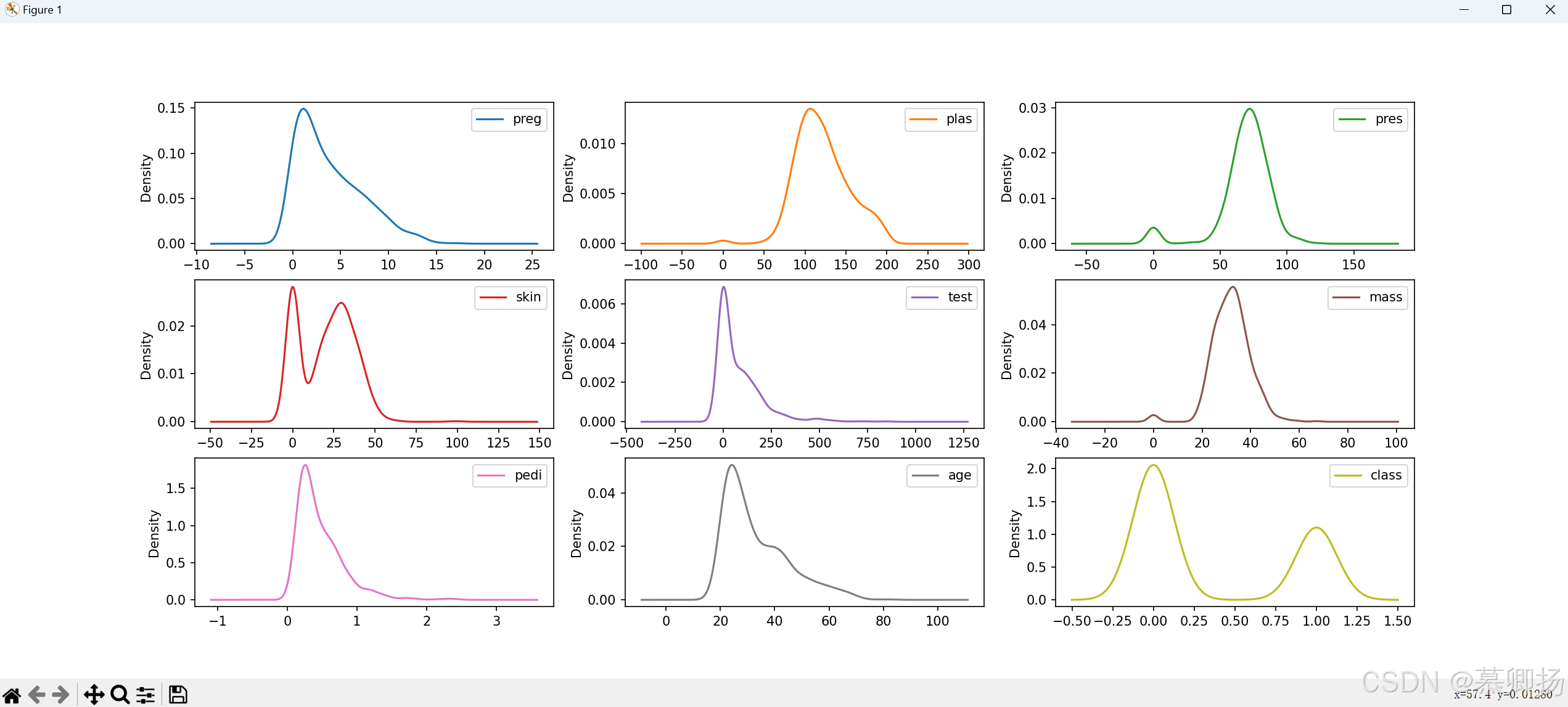
1.1.3 箱线图
箱线图是一种统计图表,用于展示数据的分布情况和离群值的情况。
箱线图将数据按照四分位数分成四部分,通过盒子的长度和上下边界的线条表示数据的分散程度和离群值的位置。箱线图可以快速识别数据的中位数、上下四分位数以及异常值的分布,帮助分析数据的稳定性和偏斜程度。
在Matplotlib中,可以使用plt.boxplot()函数绘制箱线图,并通过参数设置来调整箱线图的样式和展示方式。用箱线图把印第安人糖尿病数据集(pima_data.csv)的各项数据可视化出来,代码如下:
from pandas import read_csv
import matplotlib.pyplot as plt
filename = 'Sklearn\pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names = names)
data.plot(kind = 'box', subplots = True, layout = (3,3), sharex = False)
plt.show()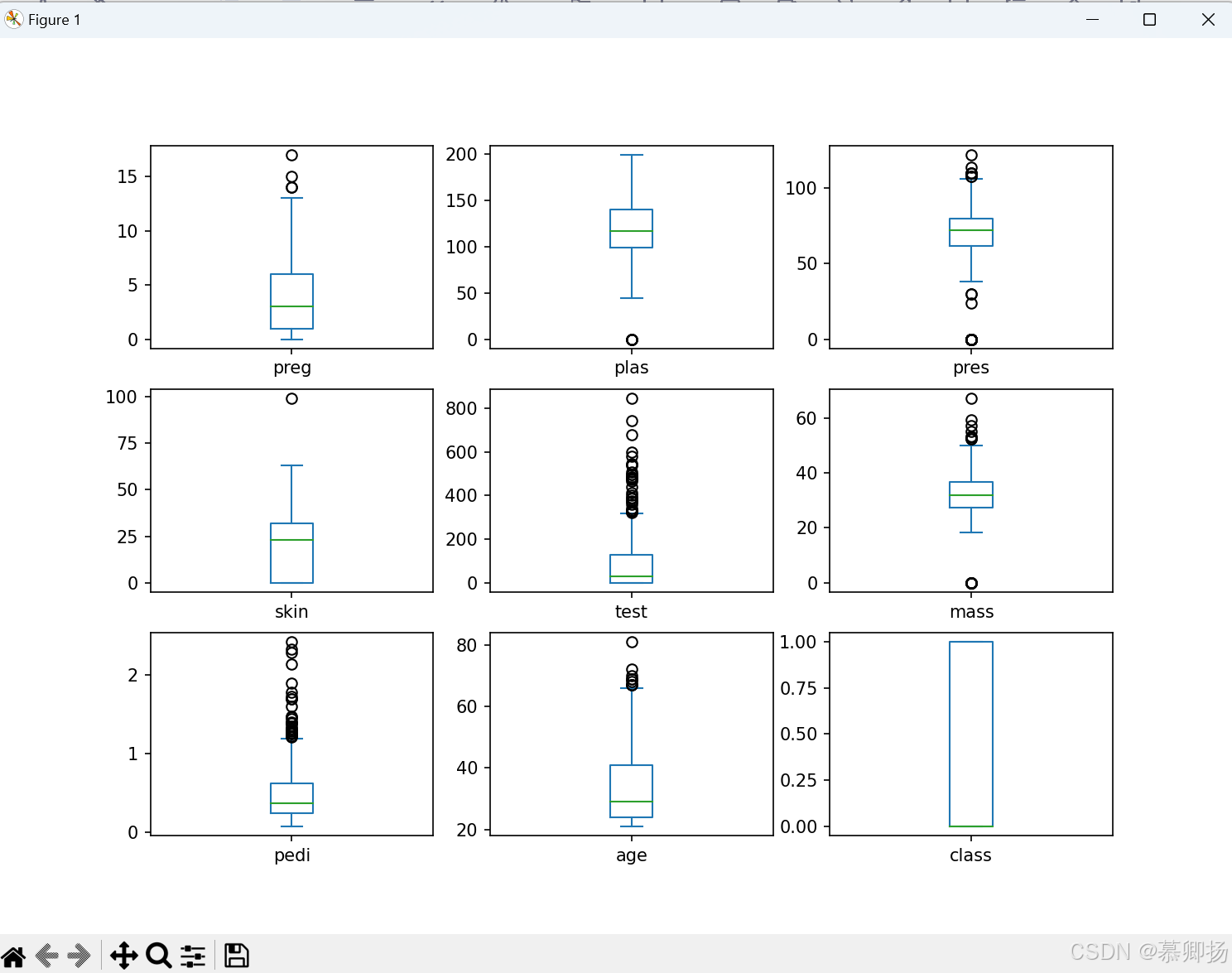
1.2 多重图表
多重图表是指在一个图表中同时展示多个数据系列或多种图表类型的组合。这种数据可视化方法可以让读者一目了然地比较不同数据之间的关系,更直观地传达复杂信息。
常见的多重图表类型包括:相关矩阵图、散点矩阵图。
1.2.1 相关矩阵图
相关矩阵图主要是用来展示两个不同的属性之间的相互影响的程度。如果两个属性按照相同的方向变化,说明是正向影响。如果两个属性是相反方向变化,说明是反向影响。把所有属性两两影响的关系展示出来的图表就叫相关矩阵图。
from pandas import read_csv
from pandas import read_csv
import matplotlib.pyplot as plt
import numpy as np
filename = 'Sklearn\pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
correlations = data.corr()
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin = -1, vmax = 1)
fig.colorbar(cax)
ticks = np.arange(0, 9, 1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
plt.show()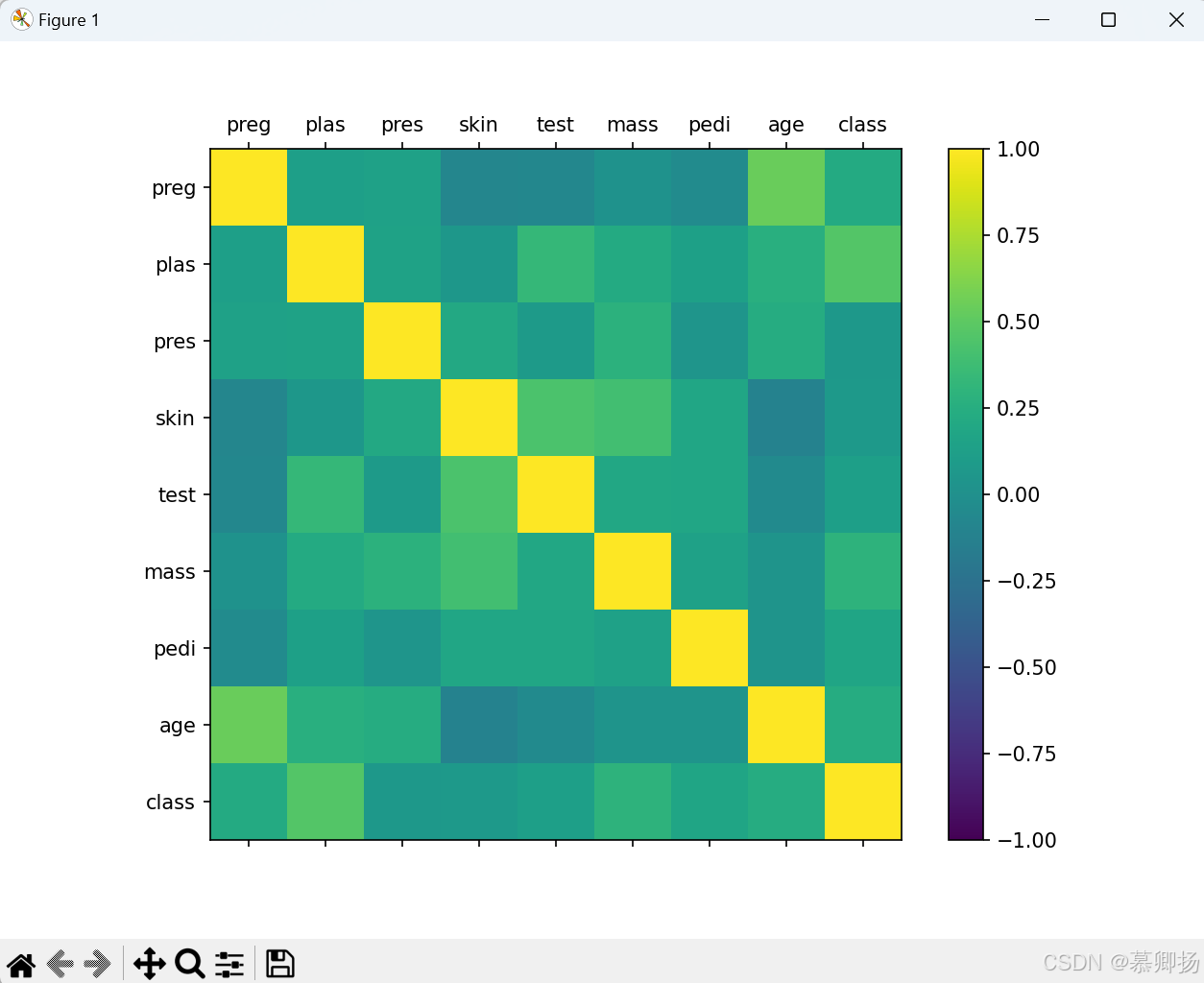
1.2.2 散点矩阵图
散点矩阵图由多个散点图组成,每个散点图展示两个不同变量之间的关系。通过矩阵的形式呈现,可以同时比较多个变量之间的相关性和分布情况,有助于发现变量之间的模式和趋势。
from pandas import read_csv
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
filename = 'Sklearn\pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names = names)
scatter_matrix(data)
plt.show()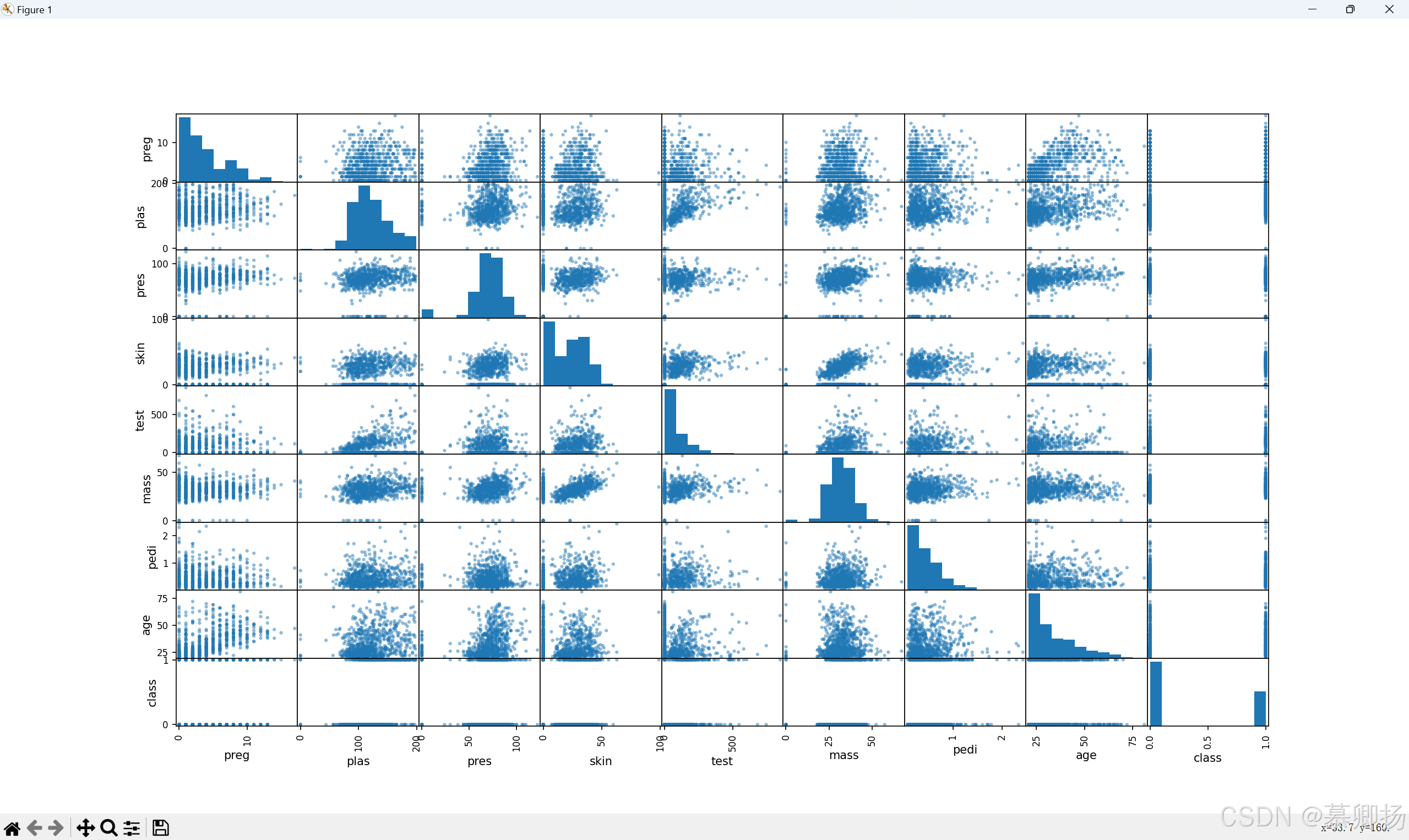
二、数据预处理
数据预处理是数据分析中至关重要的一环,其作用是清洗、转换、整合和优化原始数据,以提高数据质量、准确性和可用性,为后续的数据分析、建模和预测提供良好的数据基础。
2.1 为什么需要数据预处理
数据预处理在数据分析和机器学习中起着至关重要的作用,可以减少噪声、提取有效特征、改善数据的可用性,从而为后续的数据分析和建模工作奠定基础,提高模型的准确性和可解释性。进行数据预处理主要有以下几个原因:
-
数据质量:数据预处理可以帮助清洗和处理数据中的错误值、缺失值、异常值和重复值,提高数据的质量和准确性。
-
特征工程:数据预处理包括特征提取、特征选择和特征转换等步骤,可以将原始数据转换为更适合模型训练的特征表示,提高模型性能。
-
数据标准化:对数据进行标准化或归一化可以消除特征之间的量纲差异,确保模型训练过程更加稳定和有效。
-
处理类别型数据:将类别型数据转换为数值型数据是许多机器学习算法的要求,数据预处理可以对类别型数据进行编码。
-
降维处理:数据预处理可以通过降维技术(如主成分分析)减少数据的维度,提高模型的训练效率和泛化能力。
2.2 数据清洗
2.2.1 错误值处理
错误值指的是在数据中出现的不合理数值或超出范围的异常值。处理错误值的常见方法包括:删除或修正。
import pandas as pd# 创建一个包含错误值的数据框
data = {'A': [1, 2, 3, 1000], 'B': [4, 5, 6, 7]}
df = pd.DataFrame(data)# 删除超出范围的数据
df = df[df['A'] < 100] # 删除'A'列中大于100的错误值
print(df)
2.2.2 缺失值处理
缺失值是指数据中的空值或缺失数值。处理缺失值的方法包括:填充缺失值或删除包含缺失值的行。
import pandas as pd# 创建一个包含缺失值的数据框
data = {'A': [1, 2, None, 4], 'B': [5, None, 7, 8]}
df = pd.DataFrame(data)# 填充缺失值为均值
mean_A = df['A'].mean()
df['A'].fillna(mean_A, inplace = True)
print(df)2.2.3 异常值处理
异常值是指与数据分布显著不同的数值。处理异常值的方法包括:通过统计方法或可视化方法检测异常值,并进行删除、替换或转换。
import pandas as pd
import numpy as np# 创建一个包含异常值的数据框
data = {'A': [1, 2, 3, 100], 'B': [4, 5, 6, 7]}
df = pd.DataFrame(data)# 使用Z-score方法检测和处理异常值
from scipy import stats
df = df[(np.abs(stats.zscore(df)) < 3).all(axis = 1)] # 删除Z-score大于3的异常值
print(df)2.2.4 重复值处理
重复值是指数据集中存在相同的记录或特征值。处理重复值的方法包括:检测和删除重复记录或特征。
import pandas as pd# 创建一个包含重复值的数据框
data = {'A': [1, 2, 3, 3], 'B': [4, 5, 6, 7]}
df = pd.DataFrame(data)# 删除重复记录
df.drop_duplicates(inplace = True)
print(df)2.3 数据降维
数据降维是指减少数据集中特征的数量,同时保留数据中最重要的信息。在现实应用中,数据往往包含大量的特征,这些特征可能存在冗余、噪声或不必要的信息,导致模型训练效率低下、过拟合等问题。通过降维可以去除这些无用信息,提取数据的核心特征,以便更好地训练模型和解释数据。
2.3.1 数据降维的原理
数据降维的原理是通过保留数据集中最重要的信息,将原始高维数据映射到一个更低维度的空间中。在降维过程中,通常会选择一些主要的特征来表征数据集,以便更好地表达原始数据的结构和特征。
2.3.2 常见的数据降维方法
常见的数据降维方法包括:主成分分析(PCA)、线性判别分析(LDA)、t-SNE等,它们通过不同的数学技术实现对数据的降维处理。
2.3.2.1 主成分分析(PCA)
主成分分析(PCA)是一种常用的无监督降维技术,它通过线性变换将原始数据映射到一个新的坐标系中,新坐标系的选择是使得映射后数据的方差尽可能大。PCA通过计算数据的协方差矩阵和特征值分解来找到数据集中最重要的主成分,从而实现数据降维。
下面是简单的主成分分析示例代码:
import numpy as np
from sklearn.decomposition import PCA# 创建样本数据
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 初始化PCA对象,指定降维后的维度为2
pca = PCA(n_components = 2)# 对数据进行降维
X_pca = pca.fit_transform(X)print("原始数据shape:", X.shape)
print("降维后数据shape:", X_pca.shape)2.3.2.2 线性判别分析(LDA)
线性判别分析(LDA)是一种有监督的降维方法,它试图找到一个投影方向,使得不同类别之间的距离最大化,同一类别内的样本距离最小化。LDA在分类问题中经常用于降维和特征提取。
使用scikit-learn库加载了鸢尾花数据集,初始化了一个LDA对象,将数据降维到2维。再对数据进行了降维处理,并使用matplotlib库进行可视化展示,不同类别的数据点用不同颜色表示。最终展示了鸢尾花数据集在LDA降维后的分布情况。
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target# 初始化LDA对象,指定降维后的维度为2
lda = LinearDiscriminantAnalysis(n_components = 2)# 对数据进行降维
X_lda = lda.fit_transform(X, y)# 绘制降维后的数据
plt.figure()
colors = ['navy', 'turquoise', 'darkorange']
lw = 2for color, i, target_name in zip(colors, [0, 1, 2], iris.target_names):plt.scatter(X_lda[y == i, 0], X_lda[y == i, 1], color = color, alpha = .8, lw = lw,label = target_name)
plt.legend(loc = 'best', shadow = False, scatterpoints = 1)
plt.title('LDA of IRIS dataset')
plt.show()2.3.2.3 t-SNE
t-SNE是一种流形学习的降维方法,它可以有效地保留数据之间的局部结构关系。t-SNE通过优化高维数据在低维空间中的位置,使得相似的数据点在低维空间中靠近,从而实现数据的可视化和理解。
2.4 数据变换
数据变换是指将数据从原始状态转换为符合特定需求的形式的过程。在数据分析中,数据变换通常包括数据清洗、数据整合、数据规范化、数据标准化等操作,旨在提高数据的可用性和质量,为进一步分析和建模提供更合适的数据源。
2.4.1 数据整合
数据整合是将多个数据源合并为一个数据集的过程,常见的数据整合方法有:
- 基于键的合并:根据某个共同的键将不同数据集进行合并。
- 连接操作:根据相同的列值将不同数据集进行连接。
import pandas as pddata = {'A': [1, 2, 3, 4],'B': [10, 20, 30, 40]}df = pd.DataFrame(data)print("\n",df.sum()) # 求和
print("\n",df.mean()) # 平均值
print("\n",df.count()) # 计数2.4.2 数据规范化
数据规范化是将数据转换为统一的标准形式的过程,以便于比较分析。常见的数据规范化方法包括最小-最大规范化、Z-score规范化、小数定标规范化等。
2.4.3 数据标准化
数据标准化是指将原始数据按照一定的规则进行转换,使得数据的分布满足特定的数学关系。常见的数据标准化方法包括 Min-Max 标准化、Z-score 标准化和均值标准化等。
下面是一个简单的示例代码,演示了如何对数据进行 Min-Max 标准化:
import numpy as np
from sklearn.preprocessing import MinMaxScaler# 创建一个示例数据集
X = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])# 创建 Min-Max 标准化器
scaler = MinMaxScaler()# 对数据进行 Min-Max 标准化
X_normalized = scaler.fit_transform(X)print("原始数据:")
print(X)
print("Min-Max 标准化后的数据:")
print(X_normalized)2.5 数据集成
数据集成是指将不同数据源的数据整合到一个统一的数据存储中,以便进行分析和处理的过程。数据集成是数据管理中的一个重要环节,它可以帮助整合分散的数据,消除数据孤岛,提高数据的可用性和价值。
下面是一个简单的示例代码,演示了如何使用Python进行数据集成:
# 导入需要的库
import pandas as pd# 定义两个数据源
data_source1 = {'id': [1, 2, 3],'name': ['Alice', 'Bob', 'Charlie']
}data_source2 = {'id': [2, 3, 4],'age': [25, 30, 35]
}# 将数据源转换为DataFrame
df1 = pd.DataFrame(data_source1)
df2 = pd.DataFrame(data_source2)# 使用merge函数进行数据集成
merged_data = pd.merge(df1, df2, on = 'id', how = 'inner')# 打印集成后的数据
print(merged_data)

?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

