NeuroPilot 离线工具(Quantization, Converter etc.)常见问题
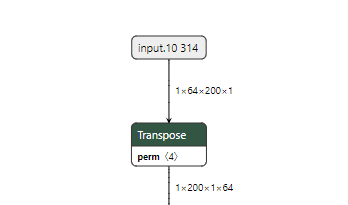
**在将模型从Caffe/PyTorch转换为TFLite格式后,因为输入从NCHW更改为NHWC,需要额外添加一个转置节点,有可能避免增加这个额外的操作吗?

【问题描述】
在将模型从Caffe/PyTorch转换为TFLite格式后,因为输入从NCHW更改为NHWC,需要额外添加一个转置节点,有可能避免增加这个额外的操作吗?
【解答】
为了避免添加这个额外的节点,您可以向Caffe/PyTorch模型添加一个wrapper。
对于Caffe,参见NeuroPilot SDK文档:Developer Tools > Model Development > Converter > Converter Tool Examples > Converting from Caffe > Floating-point (with NHWC Input/Output Tensors)。
对于PyTorch,参见NeuroPilot SDK文档:Developer Tools > Model Development > Converter > Converter Tool Examples > Converting from PyTorch > Floating-point (with NHWC Input/Output Tensors)。
**Per-axis Quantization(Per-channel Quantization)和 Per-tensor Quantization两种量化方式解析
【问题描述】
NeuroPilot Quantization tool支持的Per-axis Quantization (Per-channel Quantization)和 Per-tensor Quantization两种量化有什么区别?两者分别的适宜的使用场景是什么?对于最终量化出的模型精度有差异吗?分别通过什么参数进行配置使用?
【解答】
1)区别:
per-tensor就是整个神经网络层用一组量化参数(scale, zero-point),per-channel就是一层神经网络的每个通道用一组量化参数(scale, zero-point),最终会有多组(通道数)量化参数。
2)使用场景:
这个要依据客户模型的需求来看,是否要求每个 channel 有不同的量化参数需求,一般使用场景下一套量化参数(per-tensor)即可满足量化需求。
3)精度有差异吗:
要视具体情况而定,如果要求每个 channel 都有不同的量化参数,那肯定 per-channel 精度更高,反之,不一定。
4)参数配置:
在使用mtk_converter转模型时,通过use_per_output_channel_quantization参数来控制使用per-tensor Quantization (False)还是per-channel Quantization (True)
【适用NP版本】
NP5, NP6
NP-Online Doc Reference:
1. Developer Tools » Model Development » Quantization » Quantization Tool Introduction » Background » Per-axis Quantization and Per-tensor Quantization
2. Mediatek API Reference » Converter Tool API Documentation» Python API
**模型量化后精度不达标的情况,MTK建议有什么继续优化的方案? 混合精度在端侧是否有成熟方案?
【解答】
建议使用 QAT对模型进行量化。精度可以选择 a16w16, 如果对 performance 有要求,也可以使用 a16w8混合量化精度。
如果仍然不满足精度可以再 case by case 讨论。混合精度量化是NeuroPilot5.0后的成熟功能,已有成功落地的案例。
Note:
1)a16w16中的“a”指模型中的activation,“w”指模型中的weight
2)NP-Online Doc Reference:
Developer Tools » Model Development » Quantization » Quantization Tool Introduction » Quantization-Aware Training Tool
**如何判断模型OP是symmetric 还是asymmetric minmax?它们之间的误差范围是多少?
【问题描述】
如何根据Quantization-Aware Training后生成的pb,判断模型OP是symmetric 还是asymmetric minmax?它们之间的误差范围是多少?
【解答】
判断条件:
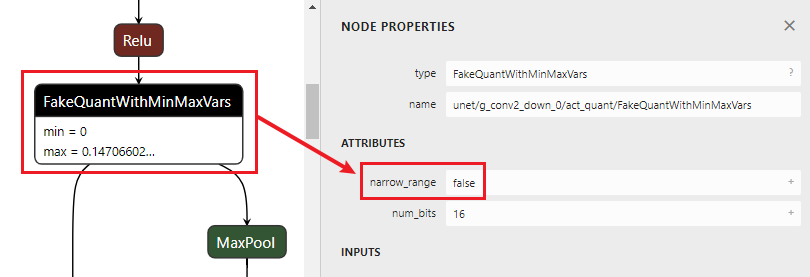
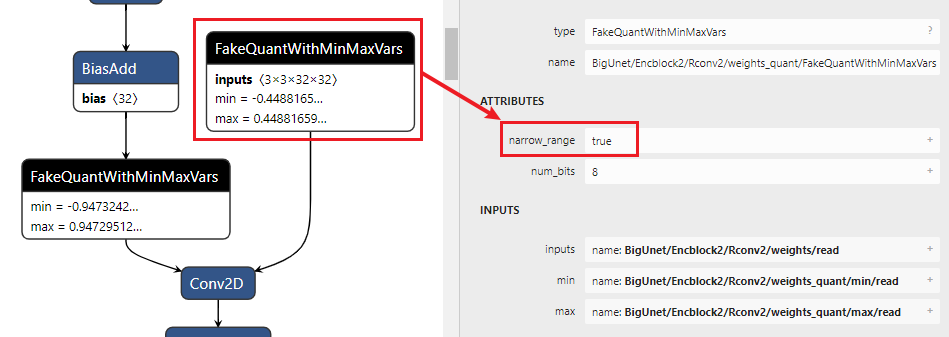
1)首先查看模型的ATTRIBUTES: narrow range是False还是True?如果是False,则为asymmetric;如果是True,则再进入2)进行判断。
2)查看Fakequant OP中的min/max值,根据bit width来判断,例如min =? (-128/127) * max
参考:Developer Tools » Model Development » Converter » Appendix – Integrate with Custom Quantization-aware Training Tools
【例子】
1)asymmetric
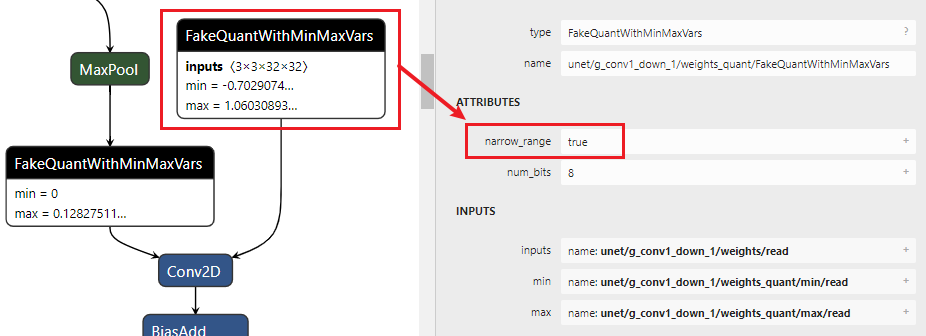
2)symmetric
Neuron SDK常见问题(包括Tools和Neuron RuntimeAPI)
** TFlite编译dla时,报错不支持float32,如何进一步处理?
【问题描述】
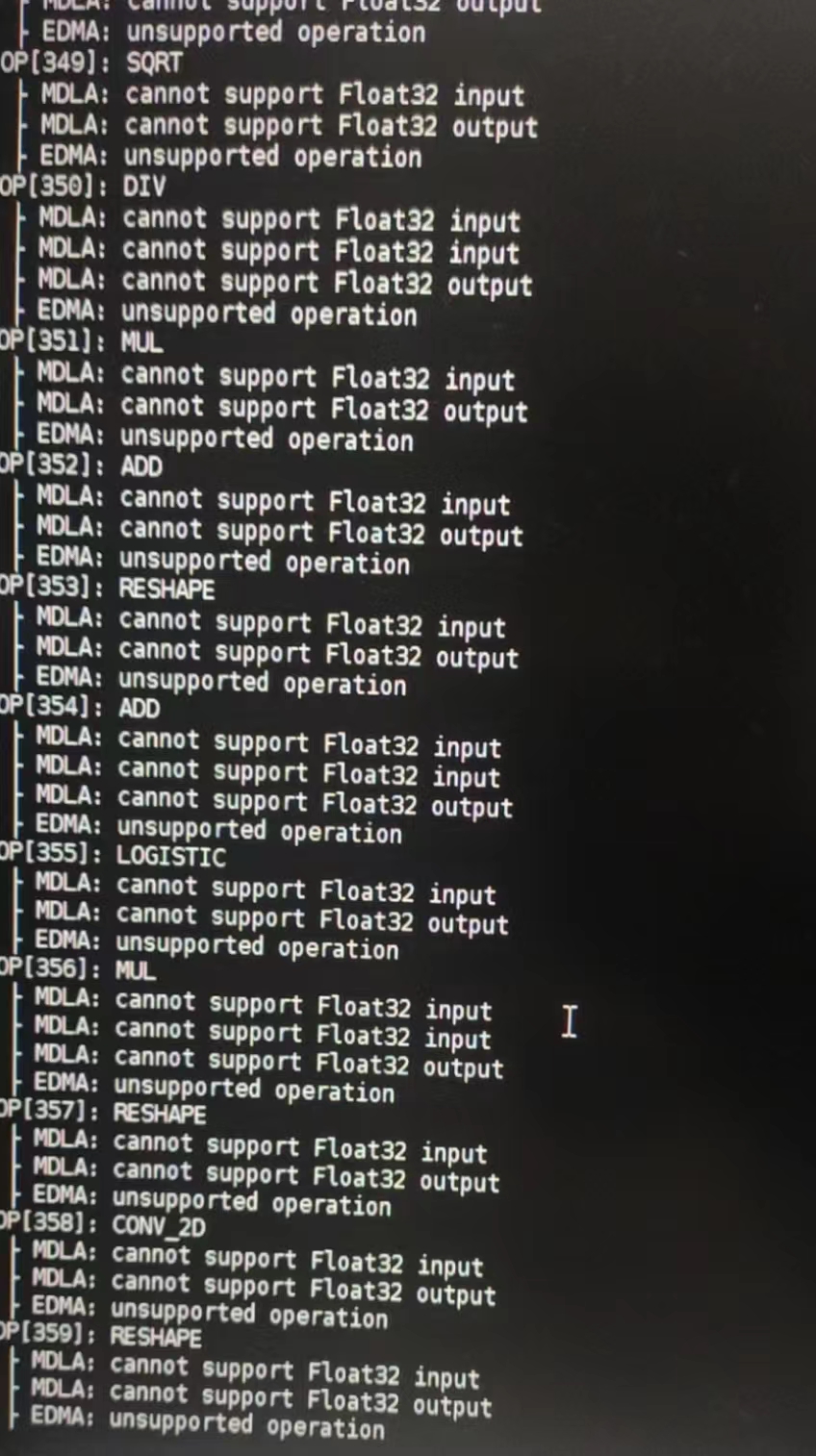
【解答】
使用NeuronSDK中的ncc-tflite编译DLA时有参数 “--relax-fp32” 可以将float32 转为float16
NP-Online Doc Reference:
Developer Tools » Model Development » Neuron SDK » Neuron Compiler (ncc-tflite), "--relax-fp32"
【适用NP版本】
NP4, NP5, NP6
**使用neuron runtime API(V1,V2)进行模型推理时的内存分配&释放过程
【问题描述】
基于neuron runtime进行AI模型部署的过程中,内存的分配方式是如何进行的?比如模型初始化阶段内存是否已经完全分配好了?执行阶段是否有新增内存?反初始化(neuron release)是否完全释放掉内存?
【解答】
以NP5的neuron runtime v2 API为例:
(1)对于MDLA和eDMA,模型初始化阶段不会分配Input/output mem,其他的static 、temporary mem会在此阶段时配好;
但如果dla模型推理中是MVPU参与的,那么初始化的时候不仅会把eDMA、MDLA的static、temporary mem分配好,还会把MVPU的input/output、static、temporary mem分配好。
(2)推理的时候,MDLA和eDMA只会另外配input/output mem(假如有用dmabuf就不会再配,因为在此之前已经分配好)。
(3)推理完毕后,所有的mem会被完全释放。
【适用NP版本】
NP4, NP5, NP6
**如何解读使用ncc-tflite编译模型时下“—show-memory-summary”参数后印出的数据中Static和Temporary的数据?
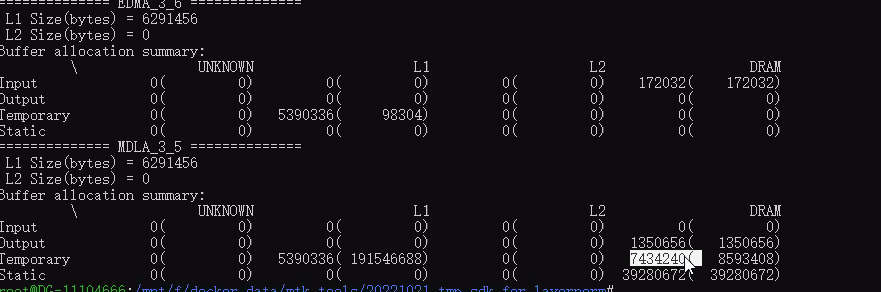
Static是指模型离线编译时就知道的constant 或是tflite档案里面就带有的数值,例如模型透过训练得到的weight值。
Temporary指的是模型中间张量的working buffer(工作缓冲区),ncc-tflite (compiler)会分析模型中graph的依赖性并会尽量减少缓冲区的使用。
例如,model中有3个op,op1 --> op2 --> op3,执行时,op1算出来的output (也就是op2的input) ,这种就会放在temporary。
【注】但如果用户在使用ncc-tflite编译模型期间下了“–l1-size-kb”配置了APU的L1 cache,那么这里op1算出来的temp data就会尽可能放在L1中(除非放不下才会有额外的temporary mem申请出来存放这部分temp data)。
使用Neuron Runtime API加载模型并初始化创建runtime instance以后, static和temporary对应的mem就会被申请出来(如果是MVPU,则会在此阶段多申请input/output mem),程序就会占用这么多内存。在模型推理过程中,内存占用会在此基础上再增加Input/Output的内存。
不过需要注意的是,V2 API的时候是runtime instance初始化创建起来后就会有,V1 API则是NeuronRuntime_loadNetwork后才会有static + temporary的内存被分配出来。
**使用NP5.x版本的NeuronSDK尝试将Tflite编译为dla档案时遇到“MDLA:data type mismatch for input and filter”问题
【问题描述】
使用converter1.4.0转出的Tflite模型可以使用ncc-tflite成功编译为dla,但是使用converter1.5.0转出的Tflite模型使用ncc-tflite编译时会报“MDLA:data type mismatch for input and filter”的错误。
【解决】
1.原因:Converter在1.5.0有一个behavior改动造成了此问题
原本PB模型是asymmetric weight minmax的
在1.4.0的converter转下来被我们强制改成symmetric quantized,搭配8w16a运算没有问题 (那时候可能这个强制改动也不会造成太明显quality issue)
但1.5.0的converter转下来,我们保留原本asymmetric weight minmax的行为,疑似造成8W16A相关compile error
2.解决方案:
在QAT时改使用symmetric的weight quantization
如果不能改模型,那可能只能先继续使用v1.4.0的converter了
**使用neuronrt时遇到“error while loading shared libraries: libc++abi.so.1: cannot open shared object file: No such file or directory”报错问题及其解决
【解答】
原因:executor binary找不到相关so导致
解决:在执行binary之前,指定LD_LIBRARY_PATH即可解决,指令:Export LD_LIBRARY_PATH={shared_lib path}
【适用NP版本】
NP4,NP5,NP6
**NeuronRuntimeV2_create API参数解析
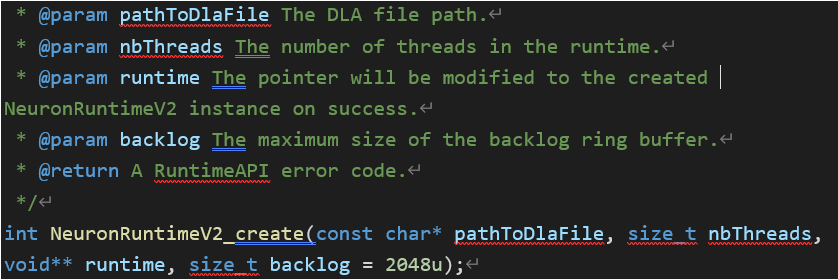
【问题描述】
1)NeuronRuntimeV2_create中的nbThread和backlog参数的含义是什么?
2)应该怎么设置它们? 如果使用SyncInferenceRequest, nbThreads传递0或1


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

