VLM-AD: End-to-End Driving through Vision-Language Model Supervision
在自动驾驶技术迅猛发展的今天,端到端(End-to-End)模型凭借其简洁的架构和强大的整合能力,成为行业研究的热点。然而,现有方法在面对复杂路况和长尾场景时,常常表现出 “思考” 能力的缺失 —— 它们更擅长模仿人类驾驶轨迹,却难以理解背后的推理逻辑。Cruise LLC与Northeastern University提出了一种全新的解决方案:VLM-AD(基于视觉语言模型监督的端到端自动驾驶),看它如何通过引入视觉语言模型(VLM)的推理能力,让自动驾驶系统真正学会 “思考”。
一、自动驾驶的 “思考” 困境:从模仿到理解的鸿沟
1.1 端到端模型的现状与挑战
当前主流的端到端自动驾驶模型,如 UniAD、VAD 等,通过单一网络整合感知、预测和规划任务,在标准数据集上已取得令人瞩目的成绩。然而,这些模型往往依赖轨迹监督信号(即一系列坐标点)进行训练,本质上是在 “模仿” 人类驾驶行为,而非 “理解” 驾驶背后的逻辑。这种 “知其然,不知其所以然” 的特性,导致模型在面对以下挑战时表现乏力:
-
长尾场景处理:在罕见的交通状况(如突发障碍物、非标准路口)中,模型难以基于环境推理做出合理决策;
-
可解释性缺失:模型输出的轨迹缺乏决策依据,无法解释 “为什么这样开”;
-
知识迁移困难:训练数据中的驾驶模式难以迁移到未见过的场景,泛化能力受限。
1.2 人类驾驶的核心优势:推理与常识
反观人类驾驶,我们不仅依赖视觉输入,更依靠常识推理和环境理解来决策。例如,当看到行人横穿马路时,司机能快速判断 “需要停车让行”,并基于交通规则和安全常识解释这一行为。这种将视觉信息与语义推理结合的能力,正是现有端到端模型所缺乏的。
1.3 突破方向:引入外部知识与推理监督
如何让自动驾驶模型获得类似人类的推理能力?一个自然的想法是引入外部知识源。近年来,大型基础模型(如大语言模型 LLM、视觉语言模型 VLM)展现出强大的推理和常识理解能力,为解决这一问题提供了新思路。然而,直接将 VLM 集成到自动驾驶系统中面临两大挑战:
-
推理效率问题:VLM 参数量庞大,实时推理会导致严重的延迟,无法满足自动驾驶的实时性要求;
-
任务适配问题:VLM 的语言输出需要转化为精确的驾驶控制信号(如轨迹、转向角),这一过程需要大量领域特定的微调,成本高昂。
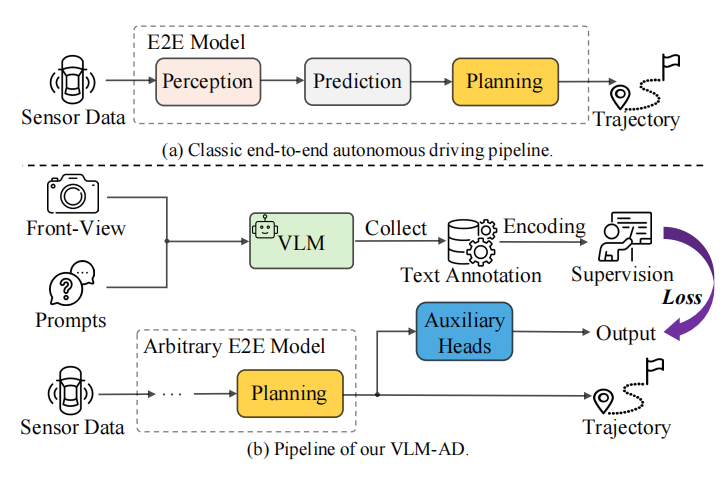
二、VLM-AD:让 VLM 成为自动驾驶的 “虚拟教练”
2.1 核心思路:知识蒸馏而非直接集成
VLM-AD 的创新之处在于,它不要求 VLM 在推理阶段参与,而是将其作为 “虚拟教练”,在训练阶段通过生成推理注释来引导模型学习。这种 “训练时监督,推理时独立” 的设计,完美平衡了知识引入与效率需求。
其核心流程可以概括为:
-
VLM 生成推理注释:利用 VLM 对驾驶场景进行语义理解,生成包含自由形式推理文本和结构化动作标签的注释;
-
辅助任务设计:基于注释设计辅助学习任务,引导端到端模型学习更丰富的特征表示;
-
联合训练:将辅助任务与原有的轨迹规划任务联合训练,提升模型的推理和规划能力。
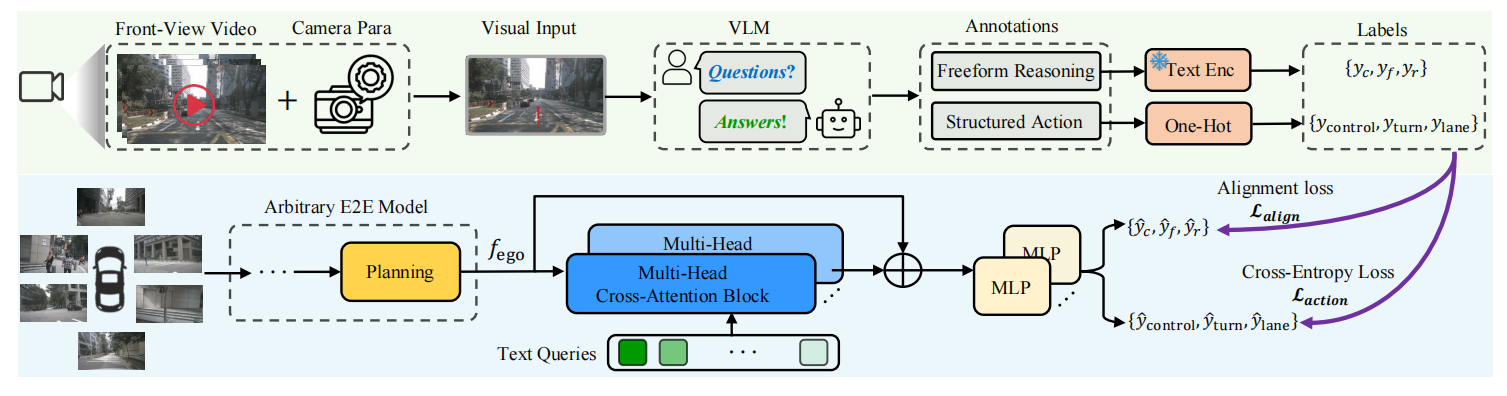
2.2 VLM 注释生成:从视觉输入到语义理解
VLM-AD 的注释生成过程是整个框架的基石。研究团队设计了一套巧妙的方法,让 VLM 能够准确理解驾驶场景并生成有用的注释:
2.2.1 视觉输入处理:融合时空信息
为了让 VLM 更好地理解驾驶场景的时间动态,研究团队提出了 “未来轨迹投影” 技术:
-
单视图选择:尽管车辆配备多摄像头,但前视图已包含大部分关键驾驶信息,因此选择前视图作为主要输入,简化处理流程;
-
轨迹投影:将车辆未来的轨迹(红色线条)投影到当前前视图中,直观地向 VLM 展示 “车辆即将如何移动”,解决了 VLM 处理连续帧时的时间连续性难题(实验表明,连续帧输入会导致 VLM 混淆车辆身份和时间顺序)。
2.2.2 双轨注释策略:自由推理与结构化动作
为了全面捕捉驾驶决策的逻辑,VLM-AD 采用两种注释方式:
1.自由形式推理注释:通过开放式问题引导 VLM 生成自然语言解释,例如:
这类注释包含丰富的语义信息,如 “车辆正在等待行人通过,因为前方有斑马线”,能够引导模型理解动作背后的原因。
-
“请描述车辆当前的动作”
-
“请预测车辆未来的动作”
-
“请解释当前和未来动作的推理过程”
2.结构化动作标签:通过预设动作集合,让 VLM 从有限选项中选择,例如:
这类注释提供明确的动作监督,便于模型学习可解释的决策模式。
-
控制动作:{直行、慢行、停车、倒车}
-
转向动作:{左转、右转、掉头、无}
-
车道动作:{左变道、右变道、并入左车道、并入右车道、无}

2.2.3 注释质量验证:VLM 的 “教学能力” 评估
为了验证 VLM 生成注释的可靠性,研究团队进行了人工评估:随机抽取 50 个案例,邀请 5 名参与者对注释质量打分。结果显示:
-
自由形式注释的平均得分为 4.48(满分 5 分),其中未来动作预测(
)得分最高(4.51 分),推理过程(
)得分略低(4.42 分);
-
结构化动作标签的准确率均超过 90%,其中车道动作准确率高达 96%。
这表明 VLM 能够生成高质量的驾驶推理注释,为模型训练提供可靠的监督信号。
2.3 辅助任务设计:让模型学会 “思考”
得到 VLM 生成的注释后,如何将这些语义信息融入端到端模型中?VLM-AD 设计了两个关键的辅助任务:
2.3.1 文本特征对齐任务
该任务旨在让模型的特征表示与 VLM 的推理文本对齐,具体步骤如下:
-
文本编码:使用 CLIP 模型将自由形式推理文本转换为特征向量;
-
交叉注意力机制:通过多头部交叉注意力(MHCA)块,让模型的自我特征(
)与文本查询交互,生成与文本特征对齐的输出;
-
温度软化策略:采用不同温度参数对文本和模型特征进行归一化,平衡特征分布的平滑度和尖锐度,提升知识蒸馏效果。
2.3.2 结构化动作分类任务
该任务引导模型学习预测 VLM 生成的结构化动作标签:
-
动作编码:将结构化动作转换为 one-hot 标签;
-
独立注意力模块:为每个动作类别(控制、转向、车道)设计独立的 MHCA 块,让模型特征与动作查询交互;
-
分类损失优化:使用交叉熵损失优化动作预测准确率。
2.3.3 联合损失函数
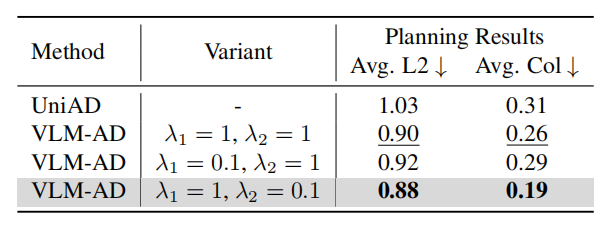
最终的训练损失由两部分组成:
其中,是文本特征对齐损失,
是结构化动作分类损失,
和
为平衡权重(实验表明,推理注释比结构化动作包含更多有价值信息)。
三、实验验证:VLM-AD 的 “学习成果”
3.1 实验设置与基线对比
为了验证 VLM-AD 的有效性,研究团队在 nuScenes 数据集上进行了全面实验,选择了两种主流端到端模型作为基线:
-
UniAD:规划导向的端到端自动驾驶模型,整合感知、预测和规划;
-
VAD:基于矢量化场景表示的高效自动驾驶模型。
同时,与 VLP(视觉语言规划)方法进行对比,VLP 将真实轨迹和边界框标签转换为文本特征进行对比学习,但未引入额外推理信息。
3.2 核心性能指标:规划精度与安全性提升
实验结果显示,VLM-AD 在关键指标上取得了显著提升:
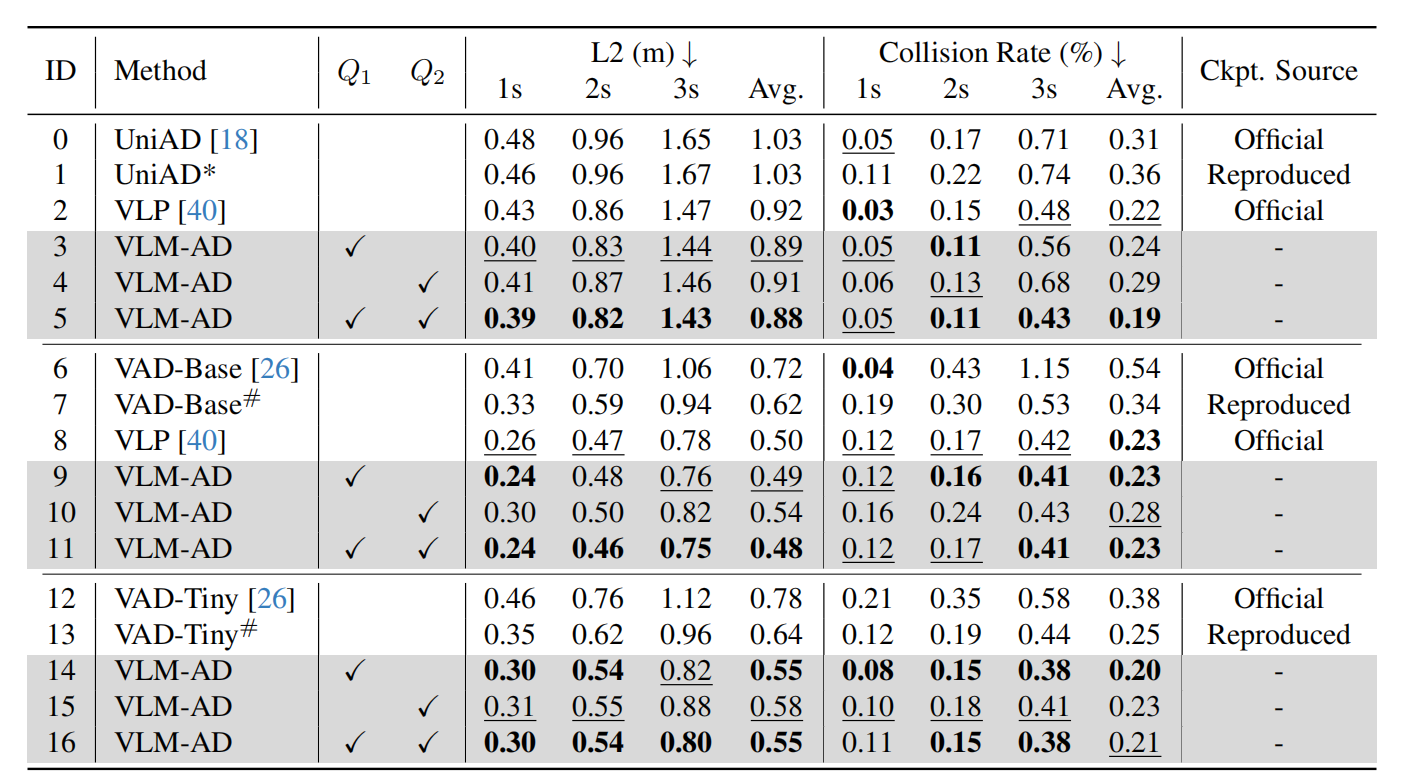
3.2.1 L2 规划误差(越低越好)
-
对于 UniAD,VLM-AD 将平均 L2 误差从 1.03 米降至 0.88 米,降幅达 14.6%;
-
对于 VAD-Base,平均 L2 误差从 0.62 米降至 0.48 米,降幅达 22.6%;
-
在 3 秒预测时域上,VLM-AD 对 UniAD 的碰撞率从 0.31% 降至 0.19%,降幅达 38.7%;对 VAD-Tiny 的碰撞率从 0.25% 降至 0.21%,降幅达 16%。
这些结果表明,VLM-AD 不仅提升了轨迹规划的精度,更重要的是显著提高了驾驶安全性。
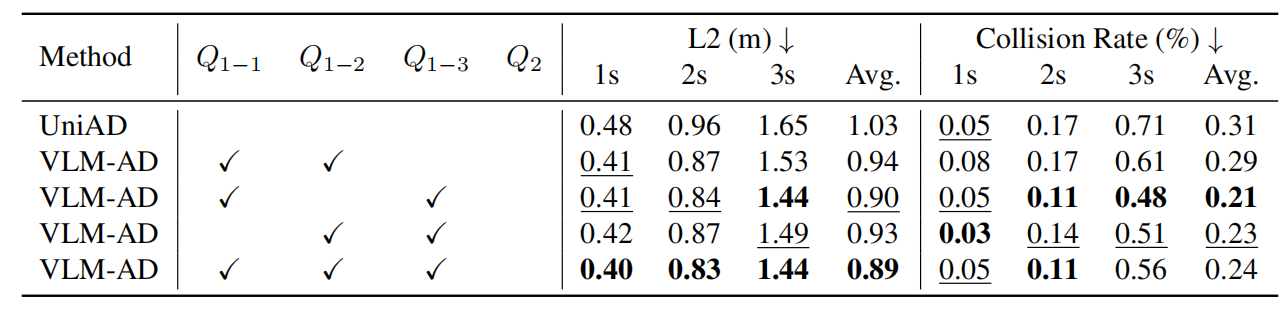
3.2.2 消融实验:各组件的贡献
为了深入理解 VLM-AD 各组件的作用,研究团队进行了详细的消融实验:
1.子问题贡献分析:
-
(当前动作描述)、
(未来动作预测)、
(推理过程)均对性能有积极影响,其中推理特征(
-
同时使用
和
比单独使用效果更好,说明自由推理与结构化动作的互补性。
2.特征对齐损失对比:
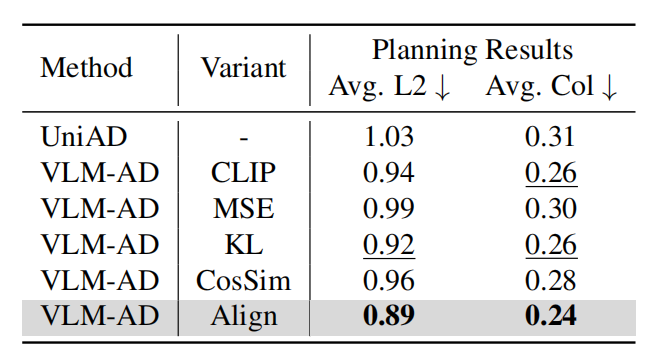
-
研究团队对比了 MSE 损失、KL 散度、余弦相似度等多种对齐方式,结果表明 VLM-AD 设计的温度软化交叉熵损失效果最佳,平均 L2 误差降至 0.89 米,优于其他方法。
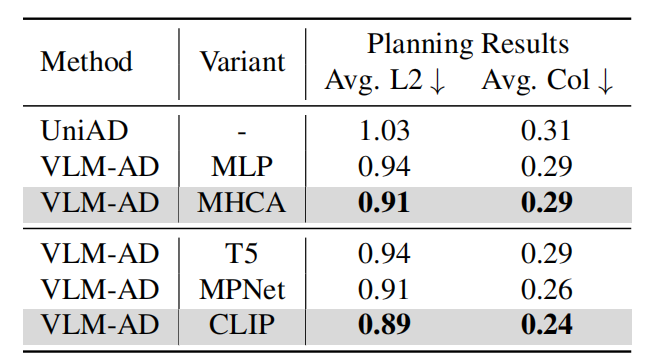
3.模型设计选择:
-
使用 MHCA 块比 MLP 层效果更好,证明交叉注意力机制在特征对齐中的优势;
-
CLIP 作为文本编码器比 T5、MPNet 表现更优,可能因其更擅长跨模态特征对齐。
3.3 可视化对比:从 “盲目模仿” 到 “理性规划”
通过可视化规划轨迹,VLM-AD 的优势更加直观:
-
轨迹平滑性:UniAD 生成的轨迹常出现 “蛇形” 摆动,而 VLM-AD 的轨迹更贴近道路中心线,如在夜间行驶和弯道场景中表现尤为明显;
-
决策合理性:在直行场景中,UniAD 可能错误预测转向动作,而 VLM-AD 的动作头能准确输出 “直行” 标签,如在雨天和城市道路场景中所示;
-
场景适应性:面对交通灯、行人等复杂场景,VLM-AD 的规划结果更符合人类驾驶逻辑,如在红灯停车和让行行人的场景中。

四、VLM-AD 的应用价值与行业影响
4.1 从研究到落地:实用性与效率优势
VLM-AD 的一个关键优势是其 “推理时无 VLM 依赖” 的设计,这带来了显著的工程落地价值:
-
实时性保障:无需在车载系统中部署庞大的 VLM 模型,避免了推理延迟,满足自动驾驶的实时性要求;
-
计算资源节约:训练阶段的 VLM 注释生成可离线进行,不影响在线推理效率;
-
兼容性强:作为插件式框架,VLM-AD 可轻松集成到现有端到端模型中,如 UniAD、VAD,无需大幅修改原有架构。
4.2 可解释性提升:让自动驾驶更透明
VLM-AD 不仅提升了性能,还增强了模型的可解释性:
-
动作可解释性:结构化动作标签(如 “直行”“左转”)为模型决策提供了明确的语义解释;
-
推理可追溯性:自由形式推理注释(如 “因为前方有行人,所以停车”)揭示了决策背后的逻辑链条;
-
调试与优化:通过分析模型对 VLM 注释的拟合程度,可定位模型在特定场景下的缺陷,指导针对性优化。
4.3 行业启示:大模型与自动驾驶的融合新范式
VLM-AD 的成功为自动驾驶与大模型的结合提供了新的思路:
-
知识蒸馏而非直接调用:对于实时性要求高的自动驾驶任务,大模型更适合作为 “教师” 在训练阶段注入知识,而非在推理阶段直接调用;
-
多模态注释的价值:将视觉信息转化为语义注释(文本 + 结构化标签),为模型提供了超越轨迹监督的更丰富学习信号;
-
任务定制化提示工程:精心设计的提示词(如 VLM-AD 中的问题设计)是释放大模型能力的关键,需要结合自动驾驶任务特性进行优化。
五、挑战与未来展望
5.1 现存挑战
尽管 VLM-AD 取得了显著进展,仍面临一些挑战:
-
VLM 注释的局限性:VLM 偶尔会生成错误注释,如将 “右转” 误判为 “左转”,或混淆交通灯与行人灯;
-
长尾场景覆盖不足:nuScenes 数据集中 “倒车”“掉头” 等动作比例极低(接近 0),可能导致模型在这些罕见场景下表现不佳;
-
计算成本权衡:生成 VLM 注释需要调用先进的 VLM(如 GPT-4o),大规模应用时的注释成本需要进一步优化。
5.2 未来发展方向
未来研究可从以下方向进一步提升 VLM-AD:
1.注释质量优化:
-
开发针对性提示策略,减少 VLM 的注释错误,如引入多轮追问机制;
-
结合自动驾驶领域知识微调 VLM,提升其对驾驶场景的理解准确性。
2.多模态融合增强:
-
除视觉外,融合雷达、激光雷达等多传感器信息,为 VLM 提供更全面的场景输入;
-
探索将高精地图信息融入注释生成,提升复杂路口的规划能力。
3.动态推理能力提升:
-
研究如何让模型学习 VLM 的时序推理能力,处理更复杂的动态场景(如多车交互);
-
开发自适应注释策略,根据场景复杂度动态调整注释的详细程度。
4.实际道路测试与部署:
-
在真实道路环境中验证 VLM-AD 的性能,特别是在极端天气、复杂交通状况下的表现;
-
与车企合作,推动 VLM-AD 在量产车型中的集成与应用。
六、结语:让自动驾驶拥有 “思考” 的翅膀
VLM-AD 的提出,标志着自动驾驶技术从 “数据驱动的模仿” 向 “知识引导的推理” 迈出了重要一步。通过引入视觉语言模型的推理能力,自动驾驶系统不仅提升了规划精度和安全性,更获得了初步的 “解释” 和 “思考” 能力。这一创新不仅具有学术价值,更为自动驾驶技术的实际落地提供了可行路径。
在未来,随着大模型技术的不断进步和自动驾驶场景的深入探索,我们有理由相信,类似 VLM-AD 的 “大模型监督学习” 范式将成为连接人工智能与自动驾驶的重要桥梁,最终实现安全、智能、可解释的全自动驾驶。




