核心目标: 构建 LLM 的数据基础,将原始文本转化为模型可处理的、包含丰富语义和结构信息的数值形式。
一、 环境与库准备 (Environment & Libraries):
- 必要库确认: 在开始之前,确保
torch(PyTorch深度学习框架) 和tiktoken(OpenAI的高效BPE分词器库) 已正确安装。可以通过以下代码检查它们的版本,这是后续代码能顺利运行的前提。from importlib.metadata import version import torch # 确保导入torch,虽然版本检查在下面,但先导入无妨 import tiktoken # 确保导入tiktokenprint("torch version:", version("torch")) print("tiktoken version:", version("tiktoken")) # 确认库已安装并显示当前安装的版本 - 本书代码仓库:
- 英文原版:
https://github.com/rasbt/LLMs-from-scratch - 汉化版 (供参考):
https://github.com/GoatCsu/CN-LLMs-from-scratch.git
- 英文原版:
二、 理解文字嵌入 (Understanding Word Embeddings) (2.1):
基础概念
- 核心概念: 将离散的文本单元(如词语、子词)转换为计算机能够理解和处理的稠密数值向量(嵌入向量)。这些向量在高维空间中捕捉词语的语义关系。
- 高维视角: LLM 通常在非常高(例如上千)维度的空间中理解和表示文本,这远超人类的直观想象能力。
- 二维模拟 (辅助理解): 我们可以通过二维或三维的降维可视化来粗略地理解嵌入空间的概念,例如语义相似的词语在空间中会聚集在一起。
- 本书重点: 本章及后续内容将主要关注文本嵌入中的词嵌入 (word embeddings) 和 子词嵌入 (subword embeddings),因为这是构建类GPT模型的基础。
三、 文本分词/令牌化 (Tokenizing Text) (2.2):
-
目标: 将连续的文本字符串拆解成一系列离散的、模型易于处理的基本单元,这些单元被称为令牌 (tokens)。令牌可以是完整的词、有意义的子词(如词根、词缀),甚至是单个字符或字节。
图示:词元化 (Tokenization) 是将原始文本数据转换为LLM能够处理的离散单元的第一步。 -
实践步骤:
- 载入源数据: 首先,我们需要一个文本源作为处理对象。本章以 Edith Wharton 的短篇小说 “The Verdict” (已进入公共领域) 为例。
import os import urllib.requestfile_name = "the-verdict.txt" if not os.path.exists(file_name):url = ("https://raw.githubusercontent.com/rasbt/""LLMs-from-scratch/main/ch02/01_main-chapter-code/""the-verdict.txt")urllib.request.urlretrieve(url, file_name)print(f"Downloaded '{file_name}'") else:print(f"'{file_name}' already exists.")with open(file_name, "r", encoding="utf-8") as f:raw_text = f.read() ##读入文件按照utf-8print(f"\nTotal number of characters in '{file_name}': {len(raw_text)}") print(f"First 99 characters:\n{raw_text[:99]}") - 使用正则表达式进行初步分词:
- 正则表达式是一种强大的文本匹配工具,可以用来根据预定义的模式(如标点符号、空白字符)来分割文本。
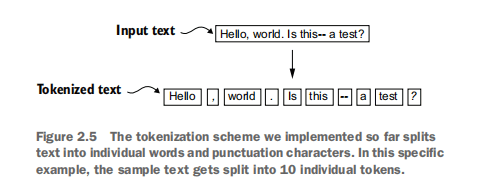
图示:展示了使用正则表达式将文本分割成令牌的过程。
import re# 示例简单文本 example_text_regex = "Hello, world. Is this-- a test?"# 初始分割(仅按空白) # result_initial = re.split(r'(\s)', example_text_regex) # print(f"Initial split: {result_initial}")# 优化分割(按逗号、句号和空白) # result_punct = re.split(r'([,.]|\s)', example_text_regex) # print(f"Split with some punctuation: {result_punct}")# 去除空白项 # result_no_space_items = [item for item in result_punct if item.strip()] # print(f"Split with punctuation, no empty/space items: {result_no_space_items}")# 更全面的正则表达式,处理更多标点符号 comprehensive_regex = r'([,.:;?_!"()\']|--|\s)' preprocessed_tokens_list = re.split(comprehensive_regex, raw_text) ##按照符号继续把原文件给分割了 # 去掉两端的空白字符,同时移除因分割产生的空字符串和仅包含空白字符的项 preprocessed_tokens_list = [item.strip() for item in preprocessed_tokens_list if item.strip()]print(f"\nFirst 30 preprocessed tokens from 'the-verdict.txt':\n{preprocessed_tokens_list[:30]}") print(f"Total number of preprocessed tokens: {len(preprocessed_tokens_list)}") # 示例输出约4690 - 正则表达式是一种强大的文本匹配工具,可以用来根据预定义的模式(如标点符号、空白字符)来分割文本。
- 载入源数据: 首先,我们需要一个文本源作为处理对象。本章以 Edith Wharton 的短篇小说 “The Verdict” (已进入公共领域) 为例。
四、 将令牌转换为令牌ID (Converting Tokens into Token IDs) (2.3):
-
目标: 为词汇表中的每一个唯一的令牌分配一个独一无二的整数ID。这是将文本进一步数值化的关键步骤。
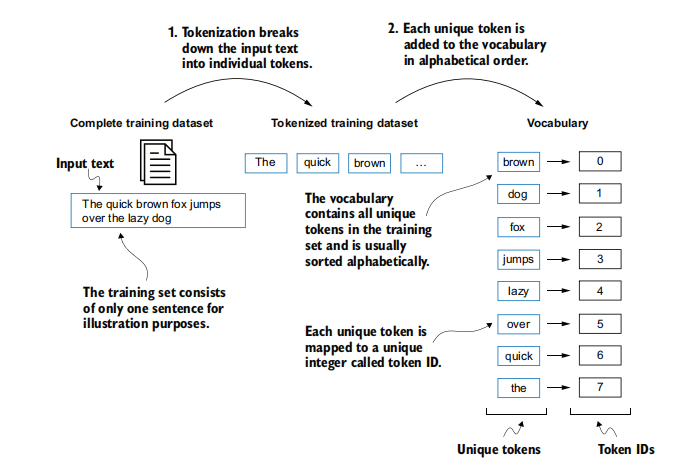
图示:将分词后的文本令牌映射为整数ID的过程。 -
步骤与代码:
-
创建词汇表 (Vocabulary):
# 从预处理后的令牌列表中提取所有唯一的令牌,并排序 all_unique_words = sorted(list(set(preprocessed_tokens_list))) vocab_size_simple = len(all_unique_words) print(f"Vocabulary size (SimpleTokenizer): {vocab_size_simple}") # 示例输出1130# 使用字典推导式生成词汇表,key是token字符串,value是整数ID # enumerate(all_unique_words) 会生成 (索引, 令牌) 的元组 vocab_simple = {token: integer for integer, token in enumerate(all_unique_words)} -
查看词汇表示例:
print("\nFirst 50 entries in the simple vocabulary:") for i, (token_str, token_id) in enumerate(vocab_simple.items()):print(f"'{token_str}': {token_id}")if i >= 49: # 打印50个break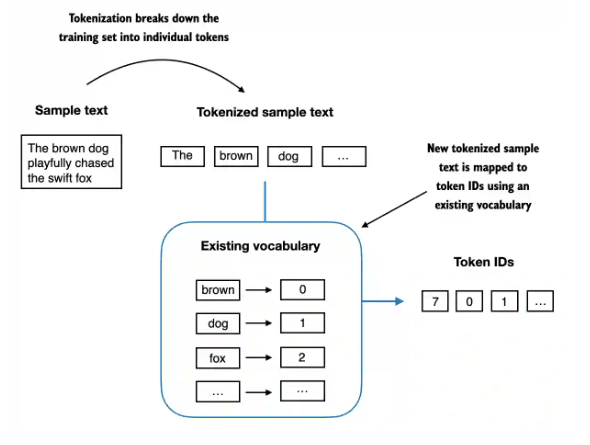
图示:展示了词汇表的一部分,将词语或标点符号映射到整数。 -
实现简单的分词器类 (
SimpleTokenizerV1):class SimpleTokenizerV1:def __init__(self, vocab_dict): # 接收词汇表字典作为参数self.str_to_int = vocab_dictself.int_to_str = {i: s for s, i in vocab_dict.items()} # 创建反向映射def encode(self, text_input: str) -> list[int]:# 使用与构建词汇表时相同的正则表达式和处理方式preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text_input)preprocessed = [item.strip() for item in preprocessed if item.strip()]# 注意:这里假设所有 preprocessed 中的 item 都能在 self.str_to_int 中找到# 如果词汇表不完整,这里会抛出 KeyErrorids = [self.str_to_int[s] for s in preprocessed]return idsdef decode(self, ids_input: list[int]) -> str:text_tokens = [self.int_to_str[i] for i in ids_input]text = " ".join(text_tokens)# 替换标点符号前的多余空格text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)return text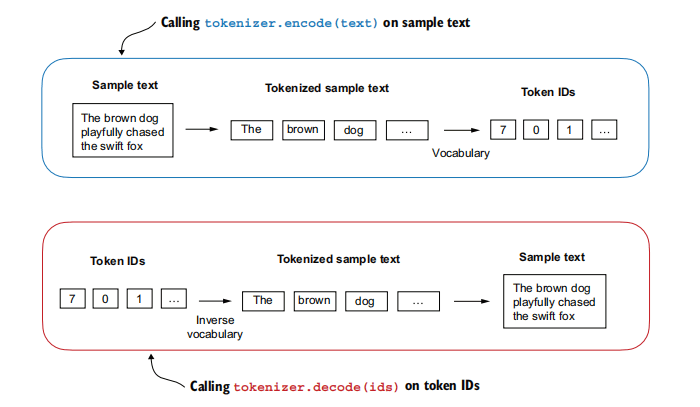
图示:SimpleTokenizerV1类的encode和decode过程。
-
五、 添加特殊上下文令牌 (Adding Special Context Tokens) (2.4):
-
目的: 使用特殊标记来帮助LLM处理如文本边界、未知词等特殊情况,从而获取更丰富的上下文信息。
-
常用的通用特殊标记:
[BOS](序列开始)[EOS](序列结束)[PAD](填充)[UNK](未知词)
-
GPT-2分词器的特殊性:
- 主要使用
<|endoftext|>作为结束和填充标记。 - 通过BPE处理未知词,不依赖
<UNK>。 - 在独立文本之间使用
<|endoftext|>进行分隔。
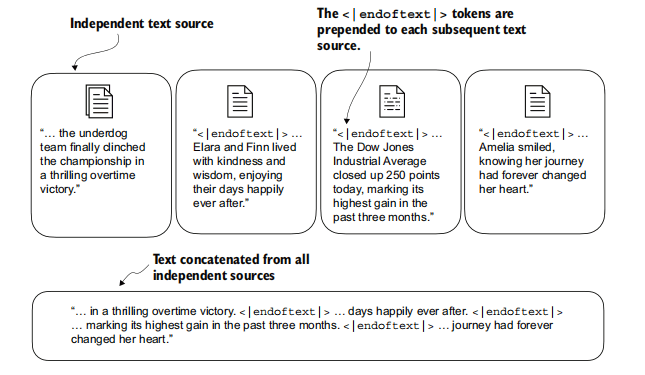
- 主要使用
-
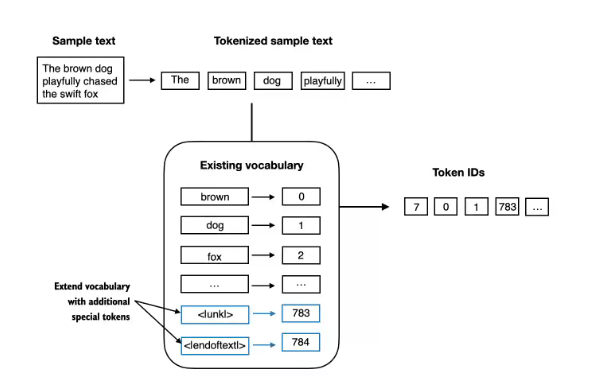
SimpleTokenizer类 (V2, 处理<|unk|>)# 重新构建词汇表,加入特殊token all_tokens_list_extended = sorted(list(set(preprocessed_tokens_list))) all_tokens_list_extended.extend(["<|endoftext|>", "<|unk|>"]) # 添加特殊token vocab_extended = {token: integer for integer, token in enumerate(all_tokens_list_extended)}class SimpleTokenizerV2: # 与您提供的代码一致def __init__(self, vocab_param): # 明确参数名self.str_to_int = vocab_paramself.int_to_str = {i: s for s, i in vocab_param.items()}def encode(self, text_param: str) -> list[int]:preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text_param)preprocessed = [item.strip() for item in preprocessed if item.strip()]processed_tokens = []for item in preprocessed:if item in self.str_to_int:processed_tokens.append(item)else:processed_tokens.append("<|unk|>") # 确保 <|unk|> 在词汇表中ids = [self.str_to_int[s] for s in processed_tokens]return idsdef decode(self, ids_param: list[int]) -> str:text_tokens = [self.int_to_str[i] for i in ids_param]text = " ".join(text_tokens)text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)return text# 使用示例 tokenizer_v2_instance = SimpleTokenizerV2(vocab_extended) text1_example = "Hello, do you like tea?" text2_example = "In the sunlit terraces of the palace." combined_text_example = " <|endoftext|> ".join((text1_example, text2_example)) print(f"\nCombined text with special token:\n{combined_text_example}") encoded_ids_v2 = tokenizer_v2_instance.encode(combined_text_example) print(f"Encoded IDs (V2): {encoded_ids_v2}") decoded_text_v2 = tokenizer_v2_instance.decode(encoded_ids_v2) print(f"Decoded text (V2): {decoded_text_v2}")- 关键点强调:
- 初始化时传入的
vocab_extended必须包含<|unk|>和<|endoftext|>。 encode方法现在会将词汇表中不存在的词映射为<|unk|>对应的ID。
- 初始化时传入的
- 关键点强调:
六、 字节对编码 (Byte Pair Encoding, BPE) (2.5):
- 背景: 为了更有效地处理未知词和控制词汇表大小,GPT-2等模型采用BPE分词。BPE能够将词语分解为有意义的子词单元,从而大幅减少OOV情况,并能表示新词和罕见词。
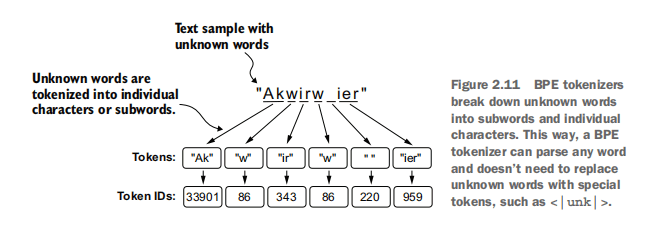
图示:BPE通过合并高频字节对来构建词汇表和切分词语。 tiktoken库: OpenAI 提供的官方BPE实现,性能较高。- 实践代码:
import tiktoken# 获取GPT-2的BPE分词器 bpe_tokenizer = tiktoken.get_encoding("gpt2")text_for_bpe = ("Hello, do you like tea? <|endoftext|> In the sunlit terraces"" of someunknownPlace." ) # 使用BPE进行编码,允许<|endoftext|>作为特殊标记 bpe_encoded_ids = bpe_tokenizer.encode(text_for_bpe, allowed_special={"<|endoftext|>"}) print(f"\nBPE Encoded IDs: {bpe_encoded_ids}")# 使用BPE进行解码 bpe_decoded_text = bpe_tokenizer.decode(bpe_encoded_ids) print(f"BPE Decoded text: {bpe_decoded_text}")- BPE的优势: BPE能够将未知词(如 “someunknownPlace”)分解为已知的子词序列,而不是简单地替换为
<UNK>,从而保留了更多的语义信息。
- BPE的优势: BPE能够将未知词(如 “someunknownPlace”)分解为已知的子词序列,而不是简单地替换为
七、 使用滑动窗口进行数据采样 (Data Sampling with a Sliding Window) (2.6):
- 目标: 为LLM的“下一词预测”训练任务准备输入-目标对。模型根据一段输入文本(上下文)来预测序列中的下一个词。
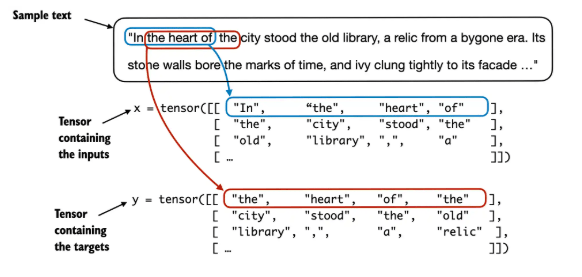
图示:滑动窗口方法将长文本切分为多个输入-目标对。 GPTDatasetV1类 :__init__:接收完整文本、分词器、最大序列长度 (max_length) 和步幅 (stride)。将整个文本编码为token ID,然后使用滑动窗口切分出input_chunk和target_chunk(目标块是输入块向右平移一位)。__len__:返回数据集中样本(即切分出的块)的数量。__getitem__:根据索引返回一个输入块和目标块。
create_dataloader_v1函数 (已在您提供的代码中):- 封装了
GPTDatasetV1的实例化和torch.utils.data.DataLoader的创建。DataLoader负责批处理、数据打乱等。
- 封装了
- 代码示例 (演示DataLoader工作方式):
# 假设 raw_text 已经加载 # dataloader = create_dataloader_v1( # raw_text, batch_size=8, max_length=4, stride=4, shuffle=False # ) # data_iter = iter(dataloader) # inputs_batch, targets_batch = next(data_iter) # print("Inputs Batch:\n", inputs_batch) # print("\nTargets Batch:\n", targets_batch)
八、 创建令牌嵌入 (Creating Token Embeddings) (2.7):
- 目标: 将离散的整数令牌ID转换为稠密的、连续的向量表示(嵌入向量)。这是LLM能够处理数值输入的基础。
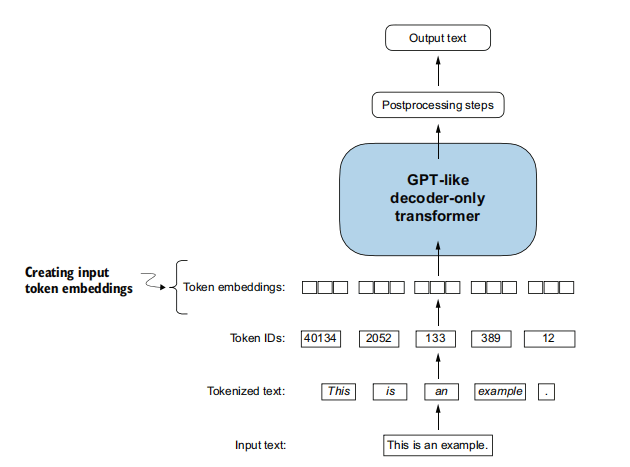
图示:将Token ID通过嵌入层映射为嵌入向量。 torch.nn.Embedding层: PyTorch中实现嵌入层的主要模块。- 本质是查找表: 接收一个token ID作为输入,输出该ID对应的嵌入向量。
- 权重矩阵:
embedding_layer.weight是一个形状为(vocab_size, output_dim)的可学习参数矩阵,存储了每个token的嵌入向量。
- 代码示例:
import torch # 确保导入input_ids_example = torch.tensor([2, 3, 5, 1]) # 示例token IDs vocab_size_example = 6 # 词汇表大小(嵌入层支持的唯一标记总数) output_dim_example = 3 # 嵌入向量的维度torch.manual_seed(123) # 设置随机种子以保证结果可复现 embedding_layer_example = torch.nn.Embedding(vocab_size_example, output_dim_example) # 每行表示一个标记的嵌入向量print("\nEmbedding Layer Weight Matrix:") print(embedding_layer_example.weight) print("\nEmbedding for token ID 3:") print(embedding_layer_example(torch.tensor([3]))) # 第4行 (索引从0开始) print("\nEmbeddings for input_ids_example:") print(embedding_layer_example(input_ids_example))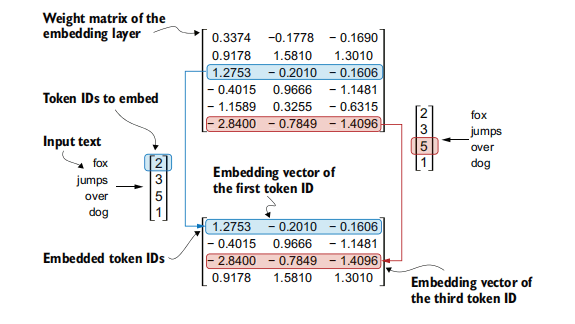
图示:嵌入层权重矩阵和查找过程。
九、 编码词语位置 (Encoding Word Positions) (2.8):
- 问题: 单纯的词嵌入无法区分同一个词在句子中不同位置的含义。
- 解决方案 (GPT-2使用绝对位置嵌入): 引入位置嵌入,与词嵌入相加,使模型能够感知词语的顺序和相对位置。
- 实现步骤:
- 词嵌入层: (同上)
vocab_size_gpt = 50257 embedding_dim_gpt = 256 # GPT-2 small的嵌入维度 token_embedding_layer_gpt = torch.nn.Embedding(vocab_size_gpt, embedding_dim_gpt) - 位置嵌入层: 创建另一个
nn.Embedding层,其“词汇表大小”为最大上下文长度 (context_length),嵌入维度与词嵌入相同。# 假设处理的序列最大长度 (也是位置嵌入要覆盖的范围) max_seq_length = 4 # 示例长度 context_length_for_pos = max_seq_length pos_embedding_layer_gpt = torch.nn.Embedding(context_length_for_pos, embedding_dim_gpt)# 为当前序列生成位置IDs (0, 1, 2, ...) position_ids_gpt = torch.arange(max_seq_length) position_embeddings_gpt = pos_embedding_layer_gpt(position_ids_gpt) # position_embeddings_gpt.shape 将是 torch.Size([max_seq_length, embedding_dim_gpt]) - 合并词嵌入与位置嵌入: 将词嵌入和位置嵌入按元素相加。
# 假设我们有一个批次的token IDs # batch_input_ids = torch.randint(0, vocab_size_gpt, (2, max_seq_length)) # 示例批次 (batch_size=2, seq_len=4) # token_embeddings_batch = token_embedding_layer_gpt(batch_input_ids) # token_embeddings_batch.shape 将是 torch.Size([2, max_seq_length, embedding_dim_gpt])# 为了演示,我们使用之前笔记中的 mock_token_embeddings batch_size_final = 2 sequence_length_final = max_seq_length torch.manual_seed(123) mock_token_embeddings_final = torch.randn(batch_size_final, sequence_length_final, embedding_dim_gpt)# 位置嵌入需要广播到批次中的每个样本 # position_embeddings_gpt 的形状是 [sequence_length, embedding_dim] # mock_token_embeddings_final 的形状是 [batch_size, sequence_length, embedding_dim] # PyTorch 会自动进行广播 final_input_embeddings_gpt = mock_token_embeddings_final + position_embeddings_gpt print(f"\nShape of final input embeddings: {final_input_embeddings_gpt.shape}") # 输出: Shape of final input embeddings: torch.Size([2, 4, 256])
- 词嵌入层: (同上)
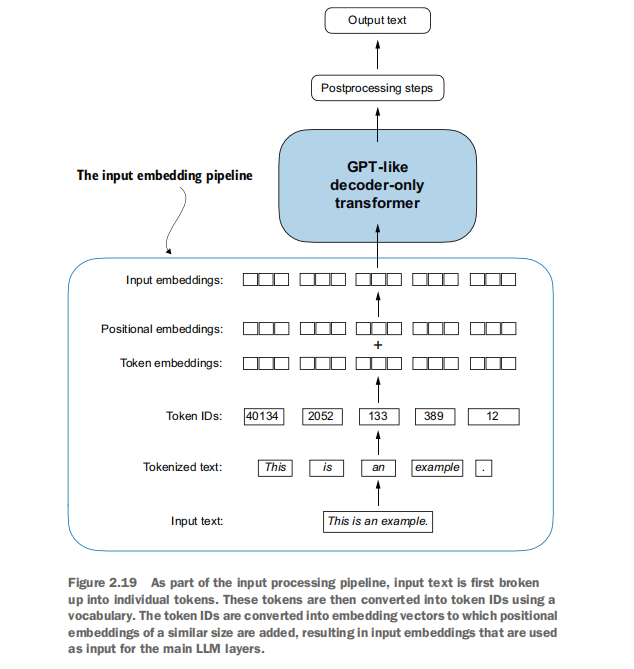 **
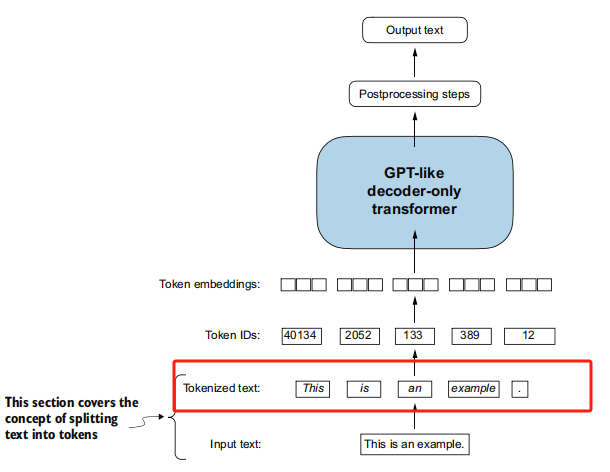
**- 整体输入处理流程回顾图示:**
- 输入文本 (Input text): 原始的文本字符串
- 分词 (Tokenized text): 文本被分词器(如BPE)分割成独立的标记序列
- 标记ID (Token IDs): 每个标记根据预定义的词汇表转换为其对应的整数ID,例如 ``。
- 词嵌入 (Token embeddings): 每个token ID通过词嵌入层转换为一个高维向量(例如256维)。
- 位置嵌入 (Positional embeddings): 为序列中的每个位置生成一个对应的位置嵌入向量。
- 最终输入嵌入 (Input embeddings to LLM): 将词嵌入和位置嵌入相加,得到最终输入给LLM后续层(如Transformer块)的表示。




