1、添加分词插件
1)在线安装
执行命令
需要指定相同的版本
bin/elasticsearch-plugin.bat install https://get.infini.cloud/elasticsearch/analysis-ik/7.17.24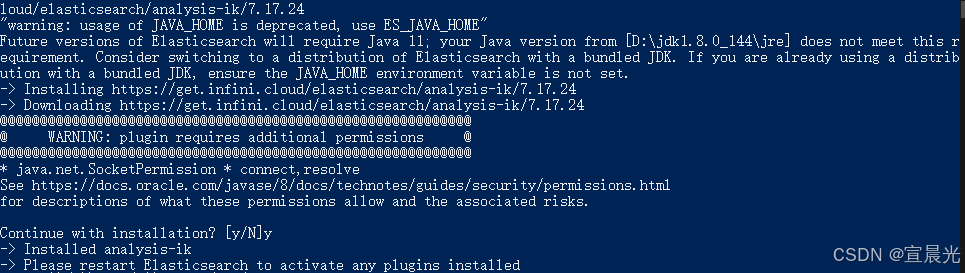
2)离线安装
将安装包解压到 /plugins 目录下
安装包可以从对应的资源处下载
启动成功后可以看到已经加载的插件
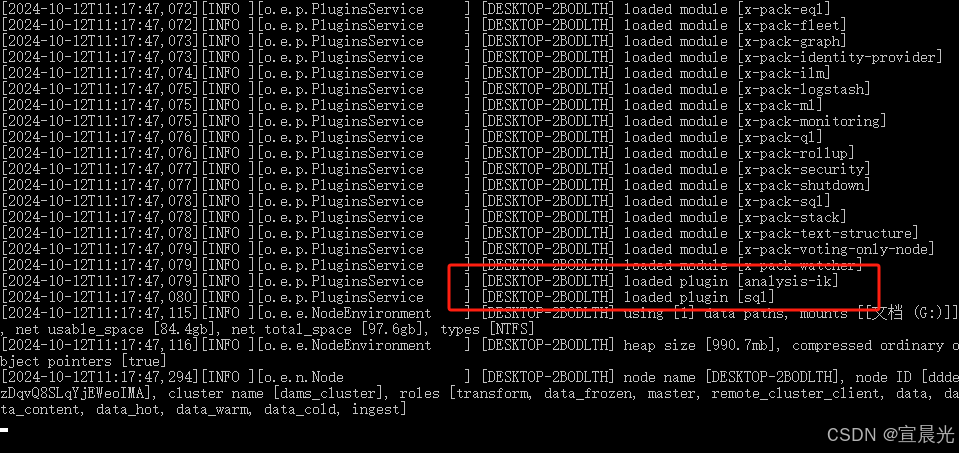
2、补充分词字典
将analysis-ik_config.zip 解压到 plugins\analysis-ik 目录下
压缩文件见附件资源。

3、创建自定义索引库
PUT 请求 http://127.0.0.1:9200/my_index_name
{"mappings": {"date_detection": false,"numeric_detection": false,"properties": {"CAT_NO": {"fields": {"keyword": {"type": "keyword"}},"type": "text"},"VOL_NO": {"fields": {"keyword": {"type": "keyword"}},"type": "text"},"content": {"type": "wildcard"},"content_file": {"type": "text"},"content_vt": {"type": "wildcard"}}},"settings": {"analysis": {"analyzer": {"default": {"type": "ik_max_word"}}},"index": {"max_result_window": 100000000,"number_of_replicas": 1,"number_of_shards": 1}}
}以上参数配置含义如下:
1. mappings 部分
mappings 用于定义文档中字段的类型和如何处理这些字段的配置。
1.1 date_detection: false
- 作用:设置为
false表示 Elasticsearch 不会自动将符合日期格式的字段解析为date类型。 - 解释:有时候字符串字段可能看起来像日期,但其实不希望它们被自动识别为日期,设置
false可以避免这种情况。
1.2 numeric_detection: false
- 作用:设置为
false表示 Elasticsearch 不会自动将符合数值格式的字段解析为numeric类型(如integer、double等)。 - 解释:如果有些数字其实是文本形式,不希望被自动检测为数字类型,这个配置可以避免这种转换。
1.3 properties
properties 中定义了各个字段的类型及其处理方式。
以下是业务自定义字段设置
CAT_NO和VOL_NO字段:type: text:表示该字段的数据是文本类型,适合分词和全文检索。fields.keyword:type: keyword:在text字段的基础上增加了keyword字段,keyword是不分词的,适合用于精确匹配(如过滤、聚合、排序等操作)。
content和content_vt字段:type: wildcard类型用于支持高效的通配符搜索。这是 Elasticsearch 7.9 引入的一种特殊数据类型,专门用于处理含有通配符查询的字段,适合快速的模式匹配搜索。
content_file字段:type: text:文本类型字段,适合分词和全文搜索。
2. settings 部分
settings 定义了索引的行为配置,包括分析器和索引分片等设置。
2.1 analysis
analysis 定义了如何对文本进行分析处理,特别是配置了自定义的分词器。
analyzer.default:type: ik_max_word:使用了 IK 分词器中的ik_max_word模式。ik_max_word:是一种中文分词模式,它会将文本尽可能切分为最多的词语,适合用于最大化覆盖搜索词的场景。
2.2 index
-
max_result_window: 100000000- 作用:表示 Elasticsearch 允许的最大分页窗口。
- 解释:默认情况下,Elasticsearch 的分页窗口大小(
from + size)限制为 10,000 个结果。通过设置max_result_window,可以增加这个限制到 100,000,000,这样可以处理大量数据的分页查询。不过,较大的窗口可能会增加内存消耗。
-
number_of_replicas: 1- 作用:表示索引的副本数,
1表示每个分片会有一个副本。 - 解释:副本可以提高查询性能,并提供容错能力,如果某个分片宕机,副本可以替代原分片。
- 作用:表示索引的副本数,
-
number_of_shards: 1- 作用:表示索引的主分片数,
1表示索引只会被划分为一个主分片。 - 解释:分片是 Elasticsearch 的水平扩展方式。对于小数据集,1 个分片可以节省资源。如果数据量增长,可以重新索引并增加分片。
- 作用:表示索引的主分片数,
4、使用Java代码创建索引库
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.DefaultConnectionKeepAliveStrategy;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequestBuilder;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.xcontent.XContentType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.io.IOException;
import java.util.Map;
import java.util.regex.Pattern;public class ElasticSearchClient {private RestHighLevelClient client;private static Logger logger = LoggerFactory.getLogger(ElasticSearchClient.class);private String indexdb;@SuppressWarnings("deprecation")public ElasticSearchClient() {String address = PropertyUtils.getProperty("indexServer");Integer port = Integer.parseInt(PropertyUtils.getProperty("serverPort"));String indexClusterName = PropertyUtils.getProperty("cluster");String userName = PropertyUtils.getProperty("es_user");String password = PropertyUtils.getProperty("es_pwd");final BasicCredentialsProvider credential = new BasicCredentialsProvider();// 配置身份验证credential.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(userName, password));// 该方法接收一个RequestConfig.Builder对象,对该对象进行修改后然后返回。// 连接超时(默认为1秒)// 套接字超时(默认为30秒)//更改客户端的超时限制默认30秒现在改为100*1000分钟client = new RestHighLevelClient(RestClient.builder(new HttpHost(address, port, "http")).setRequestConfigCallback(new RestClientBuilder.RequestConfigCallback() {@Overridepublic RequestConfig.Builder customizeRequestConfig(RequestConfig.Builder requestConfigBuilder) {return requestConfigBuilder.setConnectTimeout(50 * 1000).setSocketTimeout(60 * 1000);}}).setHttpClientConfigCallback(httpClientBuilder -> {// 设置 keep-alive 策略return httpClientBuilder.setDefaultCredentialsProvider(credential).setKeepAliveStrategy(DefaultConnectionKeepAliveStrategy.INSTANCE);}));this.indexdb = PropertyUtils.getProperty("indexdb");if (StringUtil.isBlank(indexdb)) {indexdb = "dams_index";}try {//client.putScript(putStoredScriptRequest, options);boolean exists = existIndex(indexdb);if (!exists) {String script = DefProperties.getScript();System.out.println(script);createIndex(indexdb, script);}} catch (Exception e) {e.printStackTrace();}}/*** 1、创建索引** @param index* @throws IOException*/private boolean createIndex(String index, String source) throws IOException {CreateIndexRequest request = new CreateIndexRequest(index);request.source(source, XContentType.JSON);CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);// 检查响应是否成功if (response.isAcknowledged()) {System.out.println("索引创建成功!");} else {System.out.println("索引创建失败!");}return response.isAcknowledged();}/*** 测试索引是否存在** @throws IOException*/public boolean existIndex(String index) throws IOException {GetIndexRequest request = new GetIndexRequest(index);boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);return exists;}}
由于elasticseach内置代码中,需要将mappings中的所有对象转成Map数据类型,需要对原始的Json脚本参数进行调整, 添加 type 参数
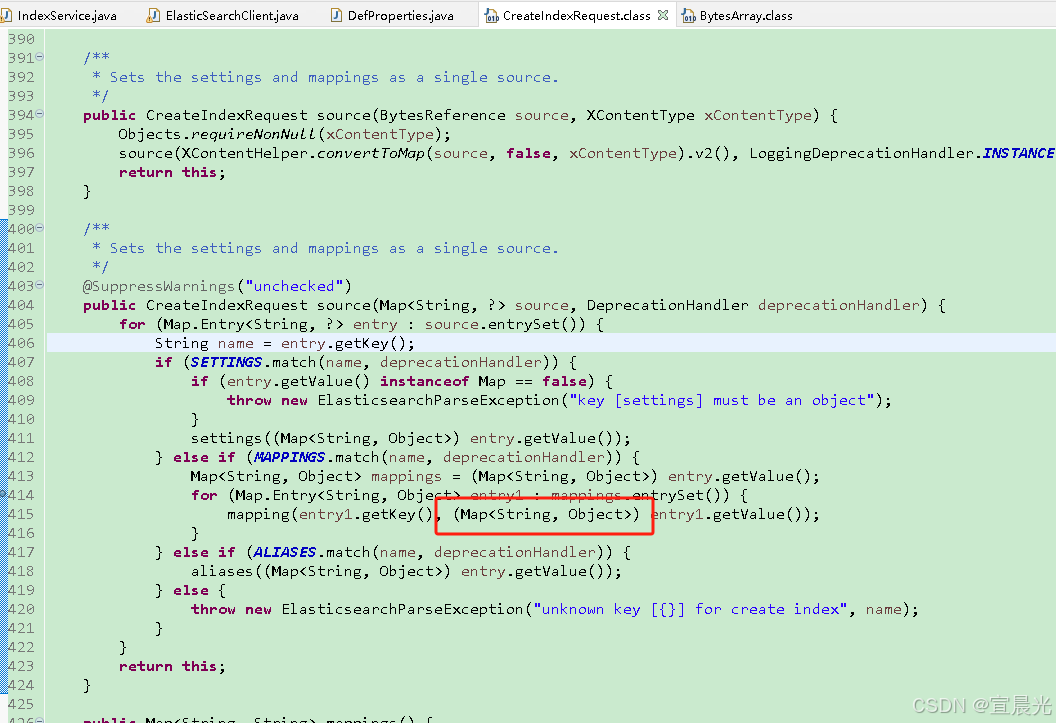
{"mappings": {"type": {"date_detection": false,"numeric_detection": false,"properties": {"VOL_NO": {"fields": {"keyword": {"type": "keyword"}},"type": "text"},"content": {"type": "wildcard"},"content_file": {"type": "text"},"content_vt": {"type": "wildcard"}}}},"settings": {"analysis": {"analyzer": {"default": {"type": "ik_max_word"}}},"index": {"max_result_window": 100000000,"number_of_replicas": 1,"number_of_shards": 1}}
}5、附录:全文检索配置文件
cluster.name: dams_cluster
network.host: 127.0.0.1
http.port: 9200# 不开启geo数据库
ingest.geoip.downloader.enabled: false
# 设置访问账号密码
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: false
##禁止机器学习
node.ml: false
xpack.ml.enabled: false## 与es-sql 插件冲突,不启用
xpack.sql.enabled: false##性能优化
## 不使用内存交换
bootstrap.memory_lock: true### 这个 fielddata 断路器限制fielddata的大小,默认情况下为堆大小的60%。
indices.breaker.fielddata.limit: 80%
### 这个 request 断路器估算完成查询的其他部分要求的结构的大小, 默认情况下限制它们到堆大小的40%。
indices.breaker.request.limit: 60%
### 这个 total 断路器封装了 request 和 fielddata 断路器去确保默认情况下这2个部分使用的总内存不超过堆大小的70%。
indices.breaker.total.limit: 80%
### 配置fieldData的Cache大小,可以配百分比也可以配一个准确的数值。cache到达约定的内存大小时会自动清理,驱逐一部分FieldData数据以便容纳新数据。默认值为unbounded无限。
indices.fielddata.cache.size: 90%




