我们非常高兴地向大家介绍 Seed-Coder,它是一个功能强大、透明、参数高效的 8B 级开源代码模型系列,包括基础变体、指导变体和推理变体。Seed-Coder 通过以下亮点促进开放代码模型的发展。
- 以模型为中心:Seed-Coder主要利用大语言模型(LLMs)而非手工规则进行代码数据过滤,最大限度地减少了预训练数据构建中的人工工作量。
- 透明:我们公开分享了以模型为核心的数据管道的详细见解,包括整理GitHub数据、提交数据和代码相关网络数据的方法。
- 强大:Seed-Coder在多种编码任务中,在同等规模的开源模型中实现了最先进的性能。
Seed-Coder-8B-Base 模型,具备以下特征:
- 类型:因果语言模型
- 训练阶段:预训练
- 数据来源:GitHub 数据、代码相关网络数据
- 训练标记:6 万亿
- 支持功能:代码补全、代码填充(中间填充)
- 上下文长度:32,768
代码示例
您需要安装最新版本的 transformers 和accelerate:
pip install -U transformers accelerate
这是一个简单的示例,展示了如何使用 Hugging Face 的 pipeline API 加载模型并执行代码生成:
import transformers
import torchmodel_id = "ByteDance-Seed/Seed-Coder-8B-Base"pipeline = transformers.pipeline("text-generation",model=model_id,model_kwargs={"torch_dtype": torch.bfloat16},device_map="auto",
)output = pipeline("def say_hello_world():", max_new_tokens=100)
print(output[0]["generated_text"])填充中间部分(FIM)示例
Seed-Coder-8B-Base 原生支持 填充中间部分(FIM) 任务,即模型被提供一个前缀和一个后缀,并要求预测缺失的中间内容。这使得在代码填充场景中,如完成函数体或在两段代码之间插入缺失的逻辑成为可能。
import transformers
import torchmodel_id = "ByteDance-Seed/Seed-Coder-8B-Base"pipeline = transformers.pipeline("text-generation",model=model_id,model_kwargs={"torch_dtype": torch.bfloat16},device_map="auto",
)# You can concatenate a prefix, a special FIM separator token, and a suffix
prefix = "def add_numbers(a, b):\n "
suffix = "\n return result"# Combine prefix and suffix following the FIM format
fim_input = '<[fim-suffix]>' + suffix + '<[fim-prefix]>' + prefix + '<[fim-middle]>'output = pipeline(fim_input, max_new_tokens=512)
print(output[0]["generated_text"])
评估
Seed-Coder-8B-Base 在代码生成、代码补全和代码推理基准测试中进行了评估,在约 8B 的开源模型中实现了最先进的性能。
| DeepSeek-Coder-6.7B-Base | OpenCoder-8B-Base | Qwen2.5-Coder-7B | Seed-Coder-8B-Base | |
|---|---|---|---|---|
| HumanEval | 47.6 | 66.5 | 72.0 | 77.4 |
| MBPP | 70.2 | 79.9 | 79.4 | 82.0 |
| MultiPL-E | 44.7 | 61.0 | 58.8 | 67.6 |
| cruxeval-O | 41.0 | 43.9 | 56.0 | 48.4 |
Seed-Coder-8B-Instruct 模型,具有以下特点:
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 数据来源:公共数据集、合成数据
- 上下文长度:32,768
代码示例
您需要安装最新版本的 transformers 和accelerate:
pip install -U transformers accelerate
这是一个简单的示例,展示了如何使用 Hugging Face 的 pipeline API 加载模型并执行代码生成:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torchmodel_id = "ByteDance-Seed/Seed-Coder-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True)messages = [{"role": "user", "content": "Write a quick sort algorithm."},
]input_ids = tokenizer.apply_chat_template(messages,tokenize=True,return_tensors="pt",add_generation_prompt=True,
).to(model.device)outputs = model.generate(input_ids, max_new_tokens=512)
response = tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=True)
print(response)
评估
Seed-Coder-8B-Instruct 在广泛的编码任务中进行了评估,包括代码生成、代码推理、代码编辑和软件工程,在约 8B 的开源模型中实现了最先进的性能。
| Model | HumanEval | MBPP | MHPP | BigCodeBench (Full) | BigCodeBench (Hard) | LiveCodeBench (2410 – 2502) |
|---|---|---|---|---|---|---|
| CodeLlama-7B-Instruct | 40.9 | 54.0 | 6.7 | 21.9 | 3.4 | 3.6 |
| DeepSeek-Coder-6.7B-Instruct | 74.4 | 74.9 | 20.0 | 35.5 | 10.1 | 9.6 |
| CodeQwen1.5-7B-Chat | 83.5 | 77.7 | 17.6 | 39.6 | 18.9 | 3.0 |
| Yi-Coder-9B-Chat | 82.3 | 82.0 | 26.7 | 38.1 | 11.5 | 17.5 |
| Llama-3.1-8B-Instruct | 68.3 | 70.1 | 17.1 | 36.6 | 13.5 | 11.5 |
| OpenCoder-8B-Instruct | 83.5 | 79.1 | 30.5 | 40.3 | 16.9 | 17.1 |
| Qwen2.5-Coder-7B-Instruct | 88.4 | 82.0 | 26.7 | 41.0 | 18.2 | 17.3 |
| Qwen3-8B | 84.8 | 77.0 | 32.8 | 51.7 | 23.0 | 23.5 |
| Seed-Coder-8B-Instruct | 84.8 | 85.2 | 36.2 | 53.3 | 20.5 | 24.7 |
Seed-Coder-8B-Reasoning 模型,具有以下特点:
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 数据来源:公共数据集
- 上下文长度:32,768
代码示例
您需要安装最新版本的 transformers 和accelerate:
pip install -U transformers accelerate
这是一个简单的示例,展示了如何使用 Hugging Face 的 pipeline API 加载模型并执行代码生成:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torchmodel_id = "ByteDance-Seed/Seed-Coder-8B-Reasoning"tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True)messages = [{"role": "user", "content": "Write a quick sort algorithm."},
]input_ids = tokenizer.apply_chat_template(messages,tokenize=True,return_tensors="pt",add_generation_prompt=True,
).to(model.device)outputs = model.generate(input_ids, max_new_tokens=16384)
response = tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=True)
print(response)
评估
Seed-Coder-8B-Reasoning 在竞争性编程中表现出色,表明较小的语言模型也能在复杂推理任务中胜任。我们的模型在 IOI’2024 上超越了 QwQ-32B 和 DeepSeek-R1,并在 Codeforces 竞赛中取得了与 o1-mini 相当的 ELO 评分。
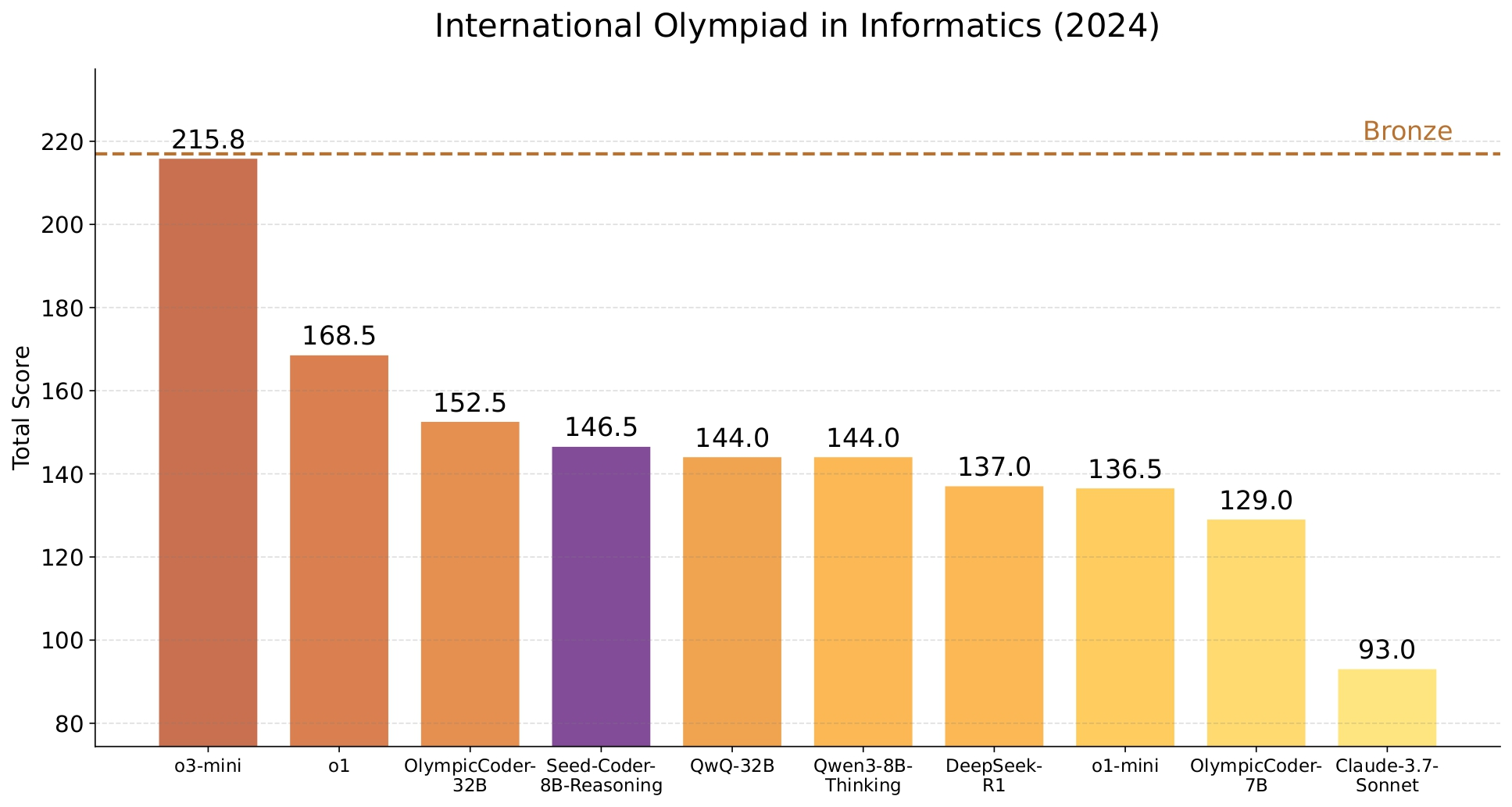
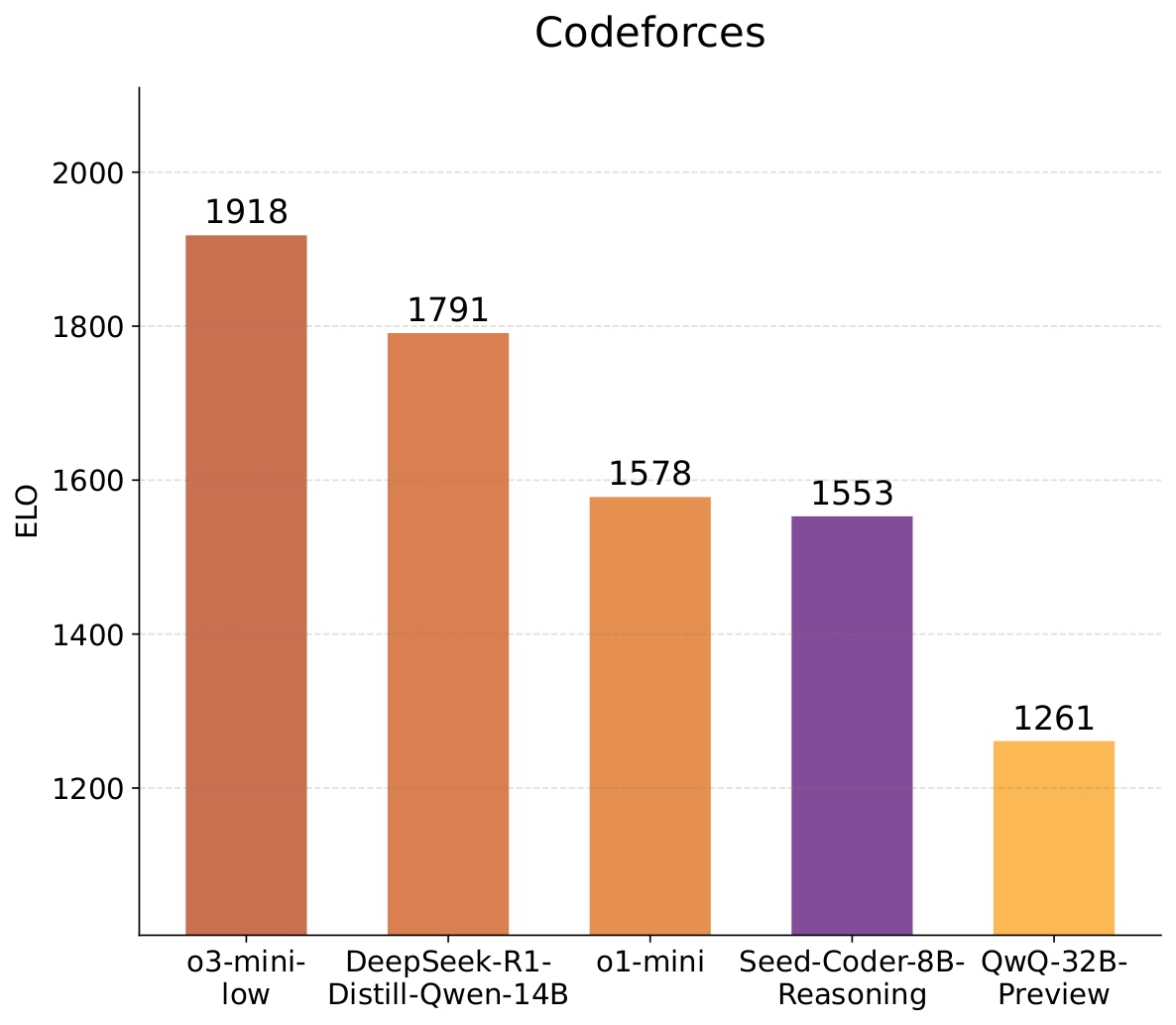
有关详细的基准性能,请参阅我们的📑 技术报告.






