总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
How to Steer LLM Latents for Hallucination Detection?
https://arxiv.org/pdf/2503.01917
https://www.doubao.com/chat/2818934852496130
其它资料:
https://blog.csdn.net/weixin_40240616/article/details/146155278
摘要
大语言模型(LLMs)中的幻觉问题对其在现实世界应用中的安全部署构成了重大担忧。最近的一些方法利用大语言模型的潜在空间来检测幻觉,但其嵌入是针对语言连贯性而非事实准确性进行优化的,常常无法清晰地将真实内容和幻觉内容区分开来。为此,我们提出了真实性分离向量(TSV),这是一种轻量级且灵活的导向向量,它在推理过程中重塑大语言模型的表示空间,以增强真实输出和幻觉输出之间的区分度,同时不改变模型参数。我们的两阶段框架首先在一小部分有标记的示例上训练TSV,以形成紧凑且分离良好的聚类。然后,它利用未标记的大语言模型生成内容来扩充示例集,采用基于最优传输的算法进行伪标记,并结合基于置信度的过滤过程。大量实验表明,TSV在使用极少标记数据的情况下达到了最先进的性能,在不同数据集上表现出很强的泛化能力,并为现实世界中的大语言模型应用提供了一个切实可行的解决方案。
1. 引言
大语言模型(LLMs)在自然语言理解和生成方面展现出了卓越的能力,彰显了其作为通用任务解决器的潜力(Zhao等人,2023)。尽管取得了成功,但大语言模型可能会生成幻觉输出——即那些看似合理但在事实上不准确或没有依据的陈述。这种幻觉可能会削弱用户的信任,并可能导致潜在的有害后果,尤其是在高风险应用中(Zhang等人,2023;Pal等人,2023)。因此,要真正值得信赖,一个大语言模型不仅必须生成与用户提示一致的文本,还必须具备检测幻觉并在幻觉出现时提醒用户的能力。
最近的一些研究探索了利用大语言模型的潜在空间来识别幻觉(Burns等人,2023;Azaria和Mitchell,2023;Marks和Tegmark,2024;Yin等人,2024a;Du等人,2024;Chen等人,2024a;Li等人,2024;Kossen等人,2024)。这些方法通常依赖于现成的大语言模型的嵌入,将输出分类为真实的或幻觉的。然而,预训练的大语言模型是使用下一个词预测目标来针对语言连贯性进行优化的,往往更优先考虑流畅性和句法正确性,而非事实准确性(Radford等人,2019)。结果是,它们的内部表示虽然在一般文本生成方面很强大,但可能无法清晰地区分真实内容和幻觉内容(见图1a中的实际示例)。这引发了一个关键问题:
我们如何塑造大语言模型的潜在空间以用于幻觉检测?
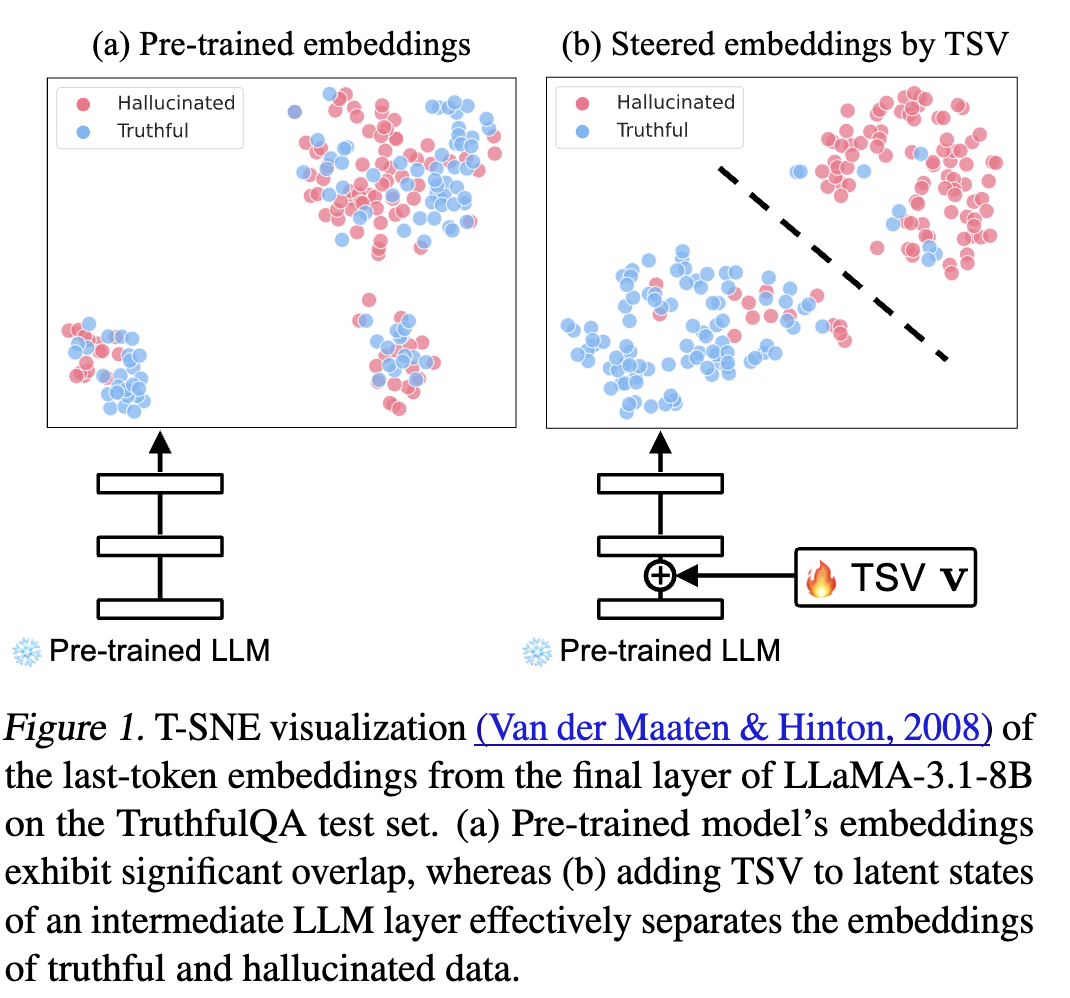
我们没有对大语言模型进行微调(微调计算成本高昂且会改变模型参数(Gekhman等人,2024)),而是提出学习一种轻量级向量,称为真实性分离向量(TSV)。如图1b所示,这个可学习向量在推理过程中被引入,并调整大语言模型的内部表示,以增强真实生成和幻觉生成之间的区分度,同时不修改模型参数。TSV专注于重塑潜在空间,以对幻觉响应进行分类,这与减轻幻觉生成的目标有着根本的不同(Li等人,2024;Chen等人,2024b;Marks和Tegmark,2024)。据我们所知,这是首次对用于幻觉检测的导向表示进行的探索。
学习TSV很有吸引力,但也具有挑战性,因为缺乏带有大语言模型生成内容真实性注释的大规模人工标记数据集,创建这些数据集既昂贵又耗时。为了克服这一问题,我们提出了一个两阶段训练框架。在初始阶段,使用一小部分有标记的数据示例集来指导学习过程。此阶段的目标是促使导向嵌入围绕代表真实和幻觉生成的类别原型形成紧凑的聚类。在第二阶段,我们通过利用未标记的大语言模型生成内容来扩充训练数据,这些数据可通过用户查询和交互从已部署的大语言模型系统中免费获得(Du等人,2024)。为了给这些未标记的样本分配伪标签,我们提出了一种基于最优传输的算法,该算法通过最小化传输成本,在考虑类别比例不平衡的情况下,将未标记数据嵌入与类别原型对齐。此外,然后使用基于置信度的样本选择,仅将最可靠的伪标记样本纳入训练过程。这些阶段共同使TSV能够有效地分离真实和幻觉表示,同时显著减少对人工标记的依赖。
大量实验表明,我们的方法在各种不同的数据集上表现出强大的性能。在具有挑战性的TruthfulQA基准测试中(Lin等人,2022a),与最先进的方法相比,我们的方法在幻觉检测准确率(AUROC)上实现了显著的 +12.8% 的提升。值得注意的是,我们的方法在使用仅包含32个示例的小标记示例集的情况下,达到了与完全监督的上限相当的性能(例如,在TruthfulQA上为84.2% 对比 85.5%)。TSV还表现出很强的泛化能力,在应用于未见过的数据集时仍能保持有竞争力的性能。我们的主要贡献总结如下:
- 我们提出了真实性分离向量(TSV),这是一种轻量级的方法,无需对大语言模型进行微调即可分离真实表示和幻觉表示,这在幻觉检测领域在很大程度上尚未被探索。
- 我们开发了一种基于最优传输的伪标记框架,并结合基于置信度的样本选择,以有效地利用未标记的大语言模型生成内容。
- 我们展示了TSV的优越性能,并进行了深入的消融研究,以评估TSV中各种设计选择的影响,并验证其在更大的大语言模型和不同数据集上的可扩展性。这些发现为利用导向向量和有限的标记数据进行幻觉检测提供了系统的理解,为未来的研究铺平了道路。
2. 相关工作
幻觉检测已成为一个关键的研究领域,它解决了大语言模型(LLMs)的安全问题以及它们在现实世界应用中的部署问题(Huang等人,2023)。大量的研究工作通过设计不确定性评分函数来处理幻觉检测。例如,基于对数几率(logit)的方法将词元级别(token-level)的概率用作不确定性分数(Ren等人,2022;Malinin和Gales,2021;Kuhn等人,2023),言语化方法促使大语言模型用人类语言表达其不确定性(Lin等人,2022b;Xiong等人,2024),而基于一致性的方法则通过评估多个回答之间的一致性来评估不确定性(Manakul等人,2023;Chen等人,2024a)。最近,基于内部状态的方法利用隐藏激活,采用诸如对比一致性搜索(Burns等人,2023)和识别幻觉子空间(Du等人,2024)等技术。然而,这些方法通常依赖于默认的大语言模型嵌入,这些嵌入本质上并不能分离真实数据和幻觉数据。相比之下,我们的方法旨在通过一个可学习的导向向量来塑造潜在空间,以增强这两种类型数据之间的分离度。
另一方面,有监督的方法利用标记数据来训练分类器,假设预训练的大语言模型在其内部状态中对响应的真实性进行了编码(Azaria和Mitchell,2023;Marks和Tegmark,2024)。然而,这些方法需要大量的标记工作。相比之下,我们的方法在极少的人工监督下进行幻觉检测,这在现实世界的应用中更具实用性。
激活工程能够在推理过程中控制大语言模型的生成,将特定任务的导向向量应用到模型的内部表示中(Zou等人,2023)。例如,一些研究通过沿着通过分析对比对之间的激活差异所确定的真实方向移动激活来减轻幻觉(Li等人,2024;Chen等人,2024b;Marks和Tegmark,2024)。同时,表示微调方法在隐藏表示的线性子空间(Wu等人,2024)或注意力头的稀疏子集(Yin等人,2024b)上引入特定学习任务的干预措施。
我们的方法在以下关键方面有所不同:(1)我们专门学习一个用于幻觉检测的导向向量,重点在于分离表示,而不是减轻幻觉生成;(2)虽然之前的方法依赖于大量的标记数据集,但我们的方法在极少的人工监督下就取得了出色的性能。





