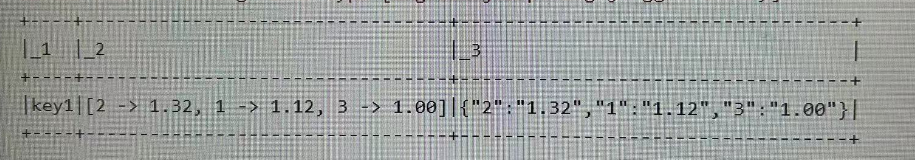前言:一般我们列转行都是使用concat_ws函数或者concat函数,但是concat一般都是用于字符串的拼接,后续处理数据时并不方便。
需求:将两列数据按照设备id进行分组,每个设备有多个时间点位和对应值,将其一一对应,并以json形式存储。
| 设备id(device_name) | 点位值(point) | 测量值(value) |
| key1 | 1 | 1.12 |
| key1 | 2 | 1.32 |
| key3 | 3 | 1.00 |
实现:
1、依旧需要对数据进行分组后聚合。由于有大量键值对,通过groupByKey进行分组
2、分组后得到(key, value[Iteratable])类型数据,对value进行转换后操作
import spark.implicits._//定义数据源
val seq = Seq(("key1","1","1.12"),("key1","3","1.32"),("key1","3","1.00")
).toDF("device","point","value")//数据处理
seq.as[pointKey].groupByKey(_.device).mapGroups((key, value) => {val list = value.toListval map = new mutable.HashMap[String, String]()list.foreach(elem => map.put(elem.point, elem.value))//此时的数据格式为map格式//map转jsonimplicit val formats: DefaultFormats.type = DefaultFormatsval json = Serialization.write(map)(key, map, json)})//样例类,用于装载
case class pointKey(device: String, point: String, value: String
)