FedAvg代码实现详细流程
目录
- FedAvg代码实现详细流程
- 1、环境配置
- 2、测试运行
- 3、源码解析
先下载源码–源码下载
1、环境配置
1、建议使用Anaconda管理环境,方便切换
2、Anaconda创建一个虚拟环境,要求python>=3.6 pytorch>=0.4
3、创建环境之后先不管,下载好的源码用pycharm打开
Pycharm:File→Setting→Project→Python Interpreter→Add Interpreter→Add Local Interpreter→Conda Enviroment配置解释器
选择你刚才用conda创建的虚拟环境
加载项目需要的库
1、打开Pycharm中的Terminal终端
2、输入 pip install -r requirements.txt
[注意]使用pip命令的时候不能使用科技,不然会pip失败
到此,项目前期的环境配置就已经完成了
2、测试运行
测试命令(一些参数可以自己修改),在Terminal里运行
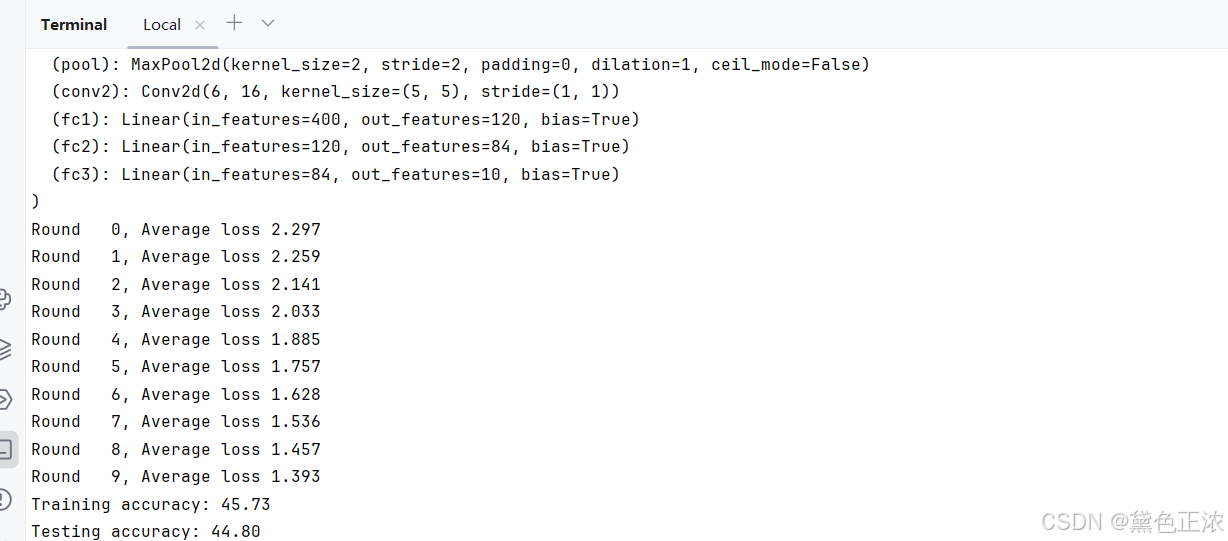
python main_fed.py --dataset mnist --iid --num_channels 1 --model cnn --epochs 50 --gpu 0
数据集使用MNIST(灰度图像所以channels为1),模型使用CNN,独立同分布(IID)形式划分用户
python main_fed.py --dataset cifar --iid --num_channel 3 --model cnn --epochs 10 --gpu 0
数据集使用CIFAR-10,模型使用CNN,独立同分布形式划分用户(CIFAR源码只提供独立同分布形式划分)
[注意]损失函数的图像存在save文件夹里
如果提示某某某库不存在,建议用pip重新下载
3、源码解析
main_fed.py
基本流程
#1、 build model,根据数据集选择建立模型if args.model == 'cnn' and args.dataset == 'cifar':
#2、 copy weights,复制当前全局模型net_glob的权重w_glob = net_glob.state_dict()
#3、 进行本地更新,w_locals和loss_locals分别存储本地权重和本地损失local = LocalUpdate(args=args, dataset=dataset_train, idxs=dict_users[idx])
#4、 update global weights,进行联邦平均,更新全局模型权重w_glob = FedAvg(w_locals)
#5、 copy weight to net_glob,保存权重net_glob.load_state_dict(w_glob)
#6、 print loss,打印损失曲线,测试准确率loss_avg = sum(loss_locals) / len(loss_locals)
逐行注解
# parse args-传入参数加载指定数据集(MNIST或CIFAR-1O),划分用户(IID/NON-IID),获取选练集中第一个样本的图像大小args = args_parser()args.device = torch.device('cuda:{}'.format(args.gpu) if torch.cuda.is_available() and args.gpu != -1 else 'cpu')#进入MNIST数据集处理流程if args.dataset == 'mnist':#图像预处理# ToTensor()将输入图像转换成Pytorch中[C,H,W]格式的tensor的张量,C是通道数,H是高度,W是宽度;将像素值从[0,255]范围转换到[0.0,1.0]范围# Normalize((0.1307,)归一化处理,Normalize(mean, std)将图像的每个通道进行归一化,灰度图像就是单通道的情况,mean-均值,std-标准差,先减mean再除stdtrans_mnist = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])#加载训练集dataset_train = datasets.MNIST('../data/mnist/', train=True, download=True, transform=trans_mnist)#加载测试机dataset_test = datasets.MNIST('../data/mnist/', train=False, download=True, transform=trans_mnist)# sample users#iid-采用独立同分布方式划分用户if args.iid:dict_users = mnist_iid(dataset_train, args.num_users)#采用非独立同分布方式划分用户else:dict_users = mnist_noniid(dataset_train, args.num_users)#数据集使用CIFAR-10elif args.dataset == 'cifar':trans_cifar = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])dataset_train = datasets.CIFAR10('../data/cifar', train=True, download=True, transform=trans_cifar)dataset_test = datasets.CIFAR10('../data/cifar', train=False, download=True, transform=trans_cifar)if args.iid:dict_users = cifar_iid(dataset_train, args.num_users)else:exit('Error: only consider IID setting in CIFAR10')else:exit('Error: unrecognized dataset')#获取训练集中第一个样本的图像大小,赋值给img_sizeimg_size = dataset_train[0][0].shape
# 1、build model,根据数据集选择构建模型net_glob,设置训练模式(模型初始化阶段-确定合适的模型结构和参数设置)if args.model == 'cnn' and args.dataset == 'cifar':net_glob = CNNCifar(args=args).to(args.device)elif args.model == 'cnn' and args.dataset == 'mnist':net_glob = CNNMnist(args=args).to(args.device)elif args.model == 'mlp':len_in = 1for x in img_size:len_in *= xnet_glob = MLP(dim_in=len_in, dim_hidden=200, dim_out=args.num_classes).to(args.device)else:exit('Error: unrecognized model')print(net_glob)#启动模型训练模式net_glob.train() #2、 copy weights,复制当前全局模型net_glob的权重w_glob = net_glob.state_dict()# training#训练过程的损失函数列表loss_train = []#存储交叉验证的损失和准略率列表cv_loss, cv_acc = [], []#存储上一次迭代的验证集损失值和计数器-用途:早停策略,在验证集损失不在下降是停止训练,防止过拟合val_loss_pre, counter = 0, 0#存储最佳模型和对应的验证集损失net_best = Nonebest_loss = None#验证集准确率和模型权重,常用于跟赵总验证集上的性能变化和保存模型的快照val_acc_list, net_list = [], []#对所有客户端聚合if args.all_clients: print("Aggregation over all clients")w_locals = [w_glob for i in range(args.num_users)]for iter in range(args.epochs):#客户端的局部损失值loss_locals = []#非全部客户端-创建w_locals存储每个客户端的局部权重if not args.all_clients:w_locals = []#确定本轮参与训练的客户端数量m,args.frac用户比例,args.num_users总用户数量,总用户数 * 用户比例=m,1确保选用的用户数量至少为1m = max(int(args.frac * args.num_users), 1)#随机选用m个客户的索引,存储idxs_users = np.random.choice(range(args.num_users), m, replace=False)for idx in idxs_users:#本地更新local = LocalUpdate(args=args, dataset=dataset_train, idxs=dict_users[idx])#传入当前的全局模型net_glob的副本,并获取更新后的权重w和局部损失lossw, loss = local.train(net=copy.deepcopy(net_glob).to(args.device))#所有客户端,将更新后的权重w赋值给w_locals的对应索引位置if args.all_clients:#深拷贝w_locals[idx] = copy.deepcopy(w)else:#否则,将权重w添加到w_locals列表中w_locals.append(copy.deepcopy(w))#局部损失loss添加到loss_locals列表中loss_locals.append(copy.deepcopy(loss))#4、 update global weights,进行联邦平均,更新全局模型权重w_globw_glob = FedAvg(w_locals)#5、 copy weight to net_glob,将更新后的权重w_glob加载搭配net_glob中,在下一轮迭代中使用net_glob.load_state_dict(w_glob)#6、 print loss,打印损失曲线,测试准确率#计算本的平均损失,添加到loss_train列表loss_avg = sum(loss_locals) / len(loss_locals)print('Round {:3d}, Average loss {:.3f}'.format(iter, loss_avg))loss_train.append(loss_avg)# plot loss curveplt.figure()plt.plot(range(len(loss_train)), loss_train)plt.ylabel('train_loss')plt.savefig('./save/fed_{}_{}_{}_C{}_iid{}.png'.format(args.dataset, args.model, args.epochs, args.frac, args.iid))# testing,在训练集和测试集上对模型进行测试,计算准确率和损失net_glob.eval()acc_train, loss_train = test_img(net_glob, dataset_train, args)acc_test, loss_test = test_img(net_glob, dataset_test, args)print("Training accuracy: {:.2f}".format(acc_train))print("Testing accuracy: {:.2f}".format(acc_test))
model包
Fed.py
#在main_fed。py中调用的FedAvg函数
#w-所有参与训练客户端的局部权重列表
def FedAvg(w):#初始化为w[0]的深拷贝w_avg = copy.deepcopy(w[0])for k in w_avg.keys():#遍历参数列表w的剩余元素,从第二个元素开始for i in range(1, len(w)):#将参数列表中的每个元素的键k对应的值加到w_avg[k]上,在每个键上累计所有参数的值w_avg[k] += w[i][k]#对累加值平均,除参数列表的长度,torch.div()执行元素级的除法w_avg[k] = torch.div(w_avg[k], len(w))return w_avg
Nets.py
定义了三个神经网络模型:MLP,CNNMnist,CNNCifar
test.py
对给定的测试数据集进行模型评估
通过迭代数据加载器,对每个批量的数据进行前向传播和损失计算,然后累加损失和正确分类的样本数。最后计算平均测试损失和准确率,并将其返回
def test_img(net_g, datatest, args):net_g.eval()# testing# 计算测试损失和正确分类的样本数test_loss = 0correct = 0data_loader = DataLoader(datatest, batch_size=args.bs)l = len(data_loader)# 对数据加载器进行迭代,每次迭代获取一个批量的数据和对应的目标标签for idx, (data, target) in enumerate(data_loader):if args.gpu != -1:data, target = data.cuda(), target.cuda()# 调用net_g模型对数据进行前向传播log_probs = net_g(data)# sum up batch loss# 使用交叉熵损失函数F.cross_entropy计算损失并累加到test_loss中test_loss += F.cross_entropy(log_probs, target, reduction='sum').item()# get the index of the max log-probability# 利用预测的对数概率计算预测的类别,并与目标标签进行比较,统计正确分类的样本数y_pred = log_probs.data.max(1, keepdim=True)[1]correct += y_pred.eq(target.data.view_as(y_pred)).long().cpu().sum()# 计算平均测试损失和准确率test_loss /= len(data_loader.dataset)accuracy = 100.00 * correct / len(data_loader.dataset)if args.verbose:print('\nTest set: Average loss: {:.4f} \nAccuracy: {}/{} ({:.2f}%)\n'.format(test_loss, correct, len(data_loader.dataset), accuracy))return accuracy, test_loss
Update.py
class LocalUpdate(object):def __init__(self, args, dataset=None, idxs=None):# 保存传入的参数,用于配置训练过程中的超参数self.args = args#交叉熵损失函数的实例-计算悬链过程中的损失self.loss_func = nn.CrossEntropyLoss()#保存选中的客户端self.selected_clients = []#创建数据加载器,加载子数据集self.ldr_train = DataLoader(DatasetSplit(dataset, idxs), batch_size=self.args.local_bs, shuffle=True)def train(self, net):net.train()# train and update#创建SGD优化器optimizer = torch.optim.SGD(net.parameters(), lr=self.args.lr, momentum=self.args.momentum)#保存每个周期的损失epoch_loss = []for iter in range(self.args.local_ep):#保存每个批次的损失batch_loss = []for batch_idx, (images, labels) in enumerate(self.ldr_train):images, labels = images.to(self.args.device), labels.to(self.args.device)#清零模型参数的梯度net.zero_grad()#通过模型前向川博,获取预测的对数概率log_probs = net(images)#损失函数计算损失loss = self.loss_func(log_probs, labels)#损失进行反向传播,参数更新loss.backward()optimizer.step()#打印当前训练进度和损失if self.args.verbose and batch_idx % 10 == 0:print('Update Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(iter, batch_idx * len(images), len(self.ldr_train.dataset),100. * batch_idx / len(self.ldr_train), loss.item()))#计算每个训练周期的平均损失,添加到epoch_loss中batch_loss.append(loss.item())epoch_loss.append(sum(batch_loss)/len(batch_loss))#返回模型的状态字典和所有训练周期的平均损失return net.state_dict(), sum(epoch_loss) / len(epoch_loss)
utils包
太累了明天补充



