
笔记整理:王鑫达,浙江大学硕士,研究方向为大模型推理与知识图谱
论文链接:https://openreview.net/forum?id=oFBu7qaZpS
发表会议:ICLR 2025
1. 动机
在自然语言处理领域,大型语言模型(LLMs)在开放域问答等任务中表现出色,但当任务扩展到需要从多个文档中提取和整合信息的复杂知识推理任务时,现有方法面临新的挑战。传统的检索增强生成(RAG)方法主要依赖于文本内容的语义相似性检索,虽然能够捕捉文本间的表面关联,但难以挖掘深层次的结构化关系。此外,基于知识图谱(KG)的RAG方法虽然能够提供结构化的知识,但受限于知识图谱本身的不完整性和信息匮乏。知识图谱通常缺乏实体的详细上下文信息,难以支持复杂的推理任务。
为了克服这些局限,本文提出了Think-on-Graph 2.0(ToG-2),这是一种混合式RAG框架,通过紧密结合知识图谱和文本检索,实现深度和全面的推理。ToG-2利用知识图谱中的实体关系指导文本检索,并通过文本上下文优化知识图谱的检索,从而逐步挖掘与问题相关的深度线索。ToG-2不仅解决了文本检索的语义局限性,还弥补了知识图谱信息不足的问题,使LLMs能够更接近人类的推理方式:基于现有知识框架逐步探索和关联潜在实体,直到找到问题的答案。
2. 贡献
本文的主要贡献有:
(1)提出了一种新颖的混合式RAG框架(KG×Text RAG),通过知识图谱和文本的紧密结合,实现深度和全面的检索过程,提升了LLMs在复杂知识推理任务中的性能。该框架利用知识图谱的结构化关系来指导文本检索,确保检索过程能够捕捉到实体间的深层次关联,同时通过文本上下文优化知识图谱的检索,从而实现更精准和全面的知识发现。
(2)设计并实现了一个迭代式的检索流程,通过交替进行知识图谱检索和文本检索,逐步挖掘与问题相关的深度线索,增强了LLMs的推理能力和忠实度。这种迭代流程模仿了人类解决问题时的探索方式,即基于现有线索逐步扩展和深化对问题的理解,每次迭代都通过知识图谱和文本的交互作用来缩小检索范围,最终找到能够回答问题的关键信息。
3. 方法
这篇文章提出了一种名为Think-on-Graph 2.0(ToG-2)的混合式检索增强生成(RAG)框架,通过紧密结合知识图谱(KG)和文本检索,利用知识图谱的结构化关系指导文本检索过程,同时借助文本上下文优化知识图谱的检索,从而实现深度和全面的检索过程。
该方法的具体流程如下:
初始化(Initialization)
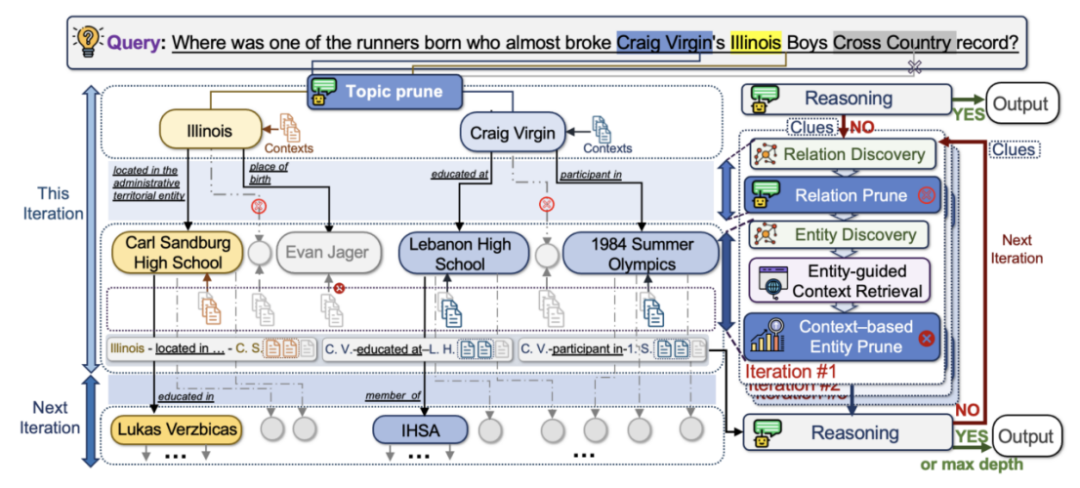
首先,从给定问题中识别实体,并通过实体链接方法将其与知识图谱中的实体相连,然后进行主题修剪(Topic Prune)从问题中提取出的关键实体中选择最适合作为知识图谱(KG)探索起点的实体。
在第一轮图谱检索前,使用密集检索模型(DRMs)从与初始主题实体相关的文档中提取前 k 个块,通过LLM评估初始检索结果是否足以回答问题,若足够则直接输出答案,否则进入迭代检索流程。。
混合知识探索(Hybrid Knowledge Exploration)
(1)知识引导的图谱搜索(Knowledge-Guided Graph Search)
关系发现(Relation Discovery):在每次迭代开始时,通过函数找到所有主题实体的关系。
关系修剪(Relation Prune):根据LLM对关系的评分,选择可能找到有用上下文信息的关系,修剪低得分关系。
实体发现(Entity Discovery):基于选定的关系找到主题实体的连接实体,随后通过上下文实体修剪步骤选择新的主题实体,完成图谱检索步骤。
(2)知识引导的上下文检索(Knowledge-Guided Context Retrieval)
实体引导的上下文检索(Entity-Guided Context Retrieval):收集与候选实体相关的文档,将候选实体的当前三元组转化为简短句子并附加到上下文中,使用 密集检索模型DRMs 计算段落相关性得分,选择得分最高的前 K 个块作为推理阶段的参考。
基于上下文的实体修剪(Context-Based Entity Prune):根据候选实体上下文块的排名得分计算其排名分数,选择排名靠前的候选实体作为下一次迭代的主题实体。
混合知识推理(Reasoning with Hybrid Knowledge)
在每次迭代结束时,用所有已找到的知识(包括线索、三元组路径、前 K 个实体及对应上下文块)提示大语言模型,判断知识是否足以回答问题。若足够,则直接输出答案;否则,让大语言模型输出有用线索并重构优化查询,继续下一轮检索,直到达到最大深度。
4. 实验
(1)性能比较实验:作者在多个知识密集型数据集(如WebQSP、AdvHotpotQA、QALD-10-en等)上比较了ToG-2与其他基线方法的性能。实验结果显示,ToG-2在多数数据集上取得了最佳性能,实验结果如表1所示
表1 不同基线方法在知识密集型数据集任务上的性能(%)

实验结果显示,ToG-2方法在多数指标上均优于其他方法,尤其在需要多步推理的数据集上表现突出。在WebQSP、AdvHotpotQA、QALD-10-en和Zero-Shot RE等数据集上,ToG-2取得了最佳性能,分别提升了4.93%、16.6%、3.85%和3%。特别是在ToG-FinQA数据集上,ToG-2的准确率达到了34.0%,远高于其他基线方法,这表明ToG-2在处理特定领域和复杂多跳推理问题时特别有效。此外,实验结果还证明了其在多种复杂知识推理任务中的泛化能力。ToG-2不仅显著提升了较小模型(如Llama-3-8B和Qwen2-7B)的推理能力,使其接近GPT-3.5的表现,还能进一步增强较强模型(如GPT-4o)的性能,表明其对不同规模的LLMs具有广泛的适用性。
(2)消融实验:LLM 骨干网络的影响:通过在 AdvHotPotQA 和 FEVER 数据集上的实验,分析不同能力的大语言模型在 ToG-2 框架下的性能提升情况,实验结果如表2所示。结果表明,ToG-2 能提升较弱模型(如 Llama-3-8B、Qwen2-7B)的推理能力至接近强大模型(如 GPT-3.5-turbo)的水平,同时强大模型(如 GPT-3.5-turbo 和 GPT-4o)也能受益于 ToG-2 进一步提升性能。在相关知识未在预训练中暴露且需要知识检索的场景(如 ToG-FinQA 数据集)中,强大模型(如 GPT-4o)能从 ToG-2 中获得更显著的提升
表2 直接推理和ToG-2在不同骨干模型上的性能比较

实体修剪工具的选择:在上下文实体修剪步骤中,比较了BGE-Embedding、BGE-reranker、Minilm、BM25 和基于大语言模型的生成式排名等不同方法在 AdvHotPotQA 数据集中的性能,结果如表3所示。其中,BGE-Reranker 性能最佳,其次是 Minilm,经典的 BM25 方法也能取得接近先进模型的效果。综合考虑运行时间和准确性,基于 DRM 的实体修剪方法(如 BGE-Reranker)在成本效益和泛化能力方面表现更优,因此选择该方法用于 ToG-2。
表3 实体修剪工具的比较分析

宽度和深度设置的影响:通过在AdvHotPotQA 数据集上分析不同最大宽度 W 和深度 D 设置对模型性能的影响,发现随着宽度从 2 增加,模型性能逐渐提升,但超过 3 后边际收益递减;深度超过 3 后模型性能趋于平稳。这表明较大的搜索范围并不总是更好,应根据任务难度进行调整。
表4 宽度和深度设置分析

5. 总结
本文提出的Think-on-Graph 2.0(ToG-2)方法通过紧密结合知识图谱和文本检索,显著提升了LLMs在复杂知识推理任务中的性能。ToG-2通过迭代式的检索流程,逐步挖掘与问题相关的深度线索,增强了LLMs的推理能力和忠实度。实验结果表明,ToG-2在多个知识密集型数据集上取得了新的最佳性能,并且能够显著提升较小模型的推理能力。此外,ToG-2的训练-free和即插即用特性使其能够广泛应用于各种LLMs和知识源。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

)




