一、缓存与数据库的使用场景及性能差异
1. 缓存的适用场景
- 高频读、低频写场景:如商品详情页、用户信息等读多写少的数据,减少数据库压力。
- 实时性要求不高的数据:如首页推荐列表、统计数据(非实时更新),允许短时间内数据不一致。
- 高并发场景下的性能优化:通过缓存抗住流量峰值,避免数据库直接被击穿(如秒杀活动中的库存查询)。
2. 数据库的适用场景
- 数据持久化与强一致性场景:如用户交易记录、订单状态变更,需保证数据不丢失且事务完整。
- 复杂查询与业务逻辑:涉及多表关联、聚合统计(如SQL的JOIN、GROUP BY),数据库更擅长处理此类结构化查询。
- 数据一致性要求高的场景:如金融交易、库存扣减,需通过数据库事务(ACID)保证操作原子性。
3. 数据库读写慢于缓存的根本原因
- 存储介质差异:
-
- 缓存(如Redis)基于内存(RAM),读写速度可达纳秒级(10⁻⁹秒)。
- 数据库(如MySQL)依赖磁盘(SSD/HDD),随机读写延迟在毫秒级(10⁻³秒),比内存慢约百万倍。
- 数据结构与查询开销:
-
- 缓存使用哈希表、跳表等内存友好的数据结构,查询复杂度低(如O(1))。
- 数据库需维护索引(如B+树)、事务日志(redo/undo log),且涉及磁盘I/O寻址,开销更高。
二、MySQL核心问题
1. 事务隔离级别
MySQL支持4种隔离级别(由低到高):
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交 | 允许 | 允许 | 允许 |
| 读已提交 | 禁止 | 允许 | 允许 |
| 可重复读 | 禁止 | 禁止 | 部分禁止 |
| 串行化 | 禁止 | 禁止 | 禁止 |
不可重复读的场景:
在一个事务内,两次读取同一数据时结果不一致。例如:
- 事务A查询用户余额为100元(未提交)。
- 事务B修改余额为80元并提交。
- 事务A再次查询时,余额变为80元,导致前后结果不一致。
原因:读已提交和可重复读隔离级别下,普通查询(非快照读)会读取最新提交的数据,而可重复读通过MVCC(多版本并发控制)避免此问题。
2. 底层存储数据结构:B+树
- 为什么不用平衡二叉树?
平衡二叉树的树高为O(logN),当数据量大时,磁盘I/O次数多(每次I/O对应树的一层)。而B+树通过以下特性优化:
-
- 多叉树结构:每个节点可存储多个键值对,树高更低(如三层B+树可存储百万级数据)。
- 数据全在叶子节点:非叶子节点仅存索引,叶子节点存数据且有序连接,便于范围查询(如
WHERE age > 18)。
3. 三层B+树最大数据量计算
InnoDB的叶子节点存储的单位是页
mysql页默认存储的单位是 16384 个字节 16kb 也就是一个节点的大小 节点大小为16KB
非叶子节点存储的是索引键值和页指针
索引键值 BigInt 8字节
页指针 6字节
那么根节点有
16384 字节 / 14 字节 = 1170 个页指针
第二层有1170个子节点 每个子节点又指向1180个子节点
第三层都是叶子节点
每个叶子节点存16kb
那么总大小就是 1170 * 1170 * 16 =21902400 条
2200万kb的数据
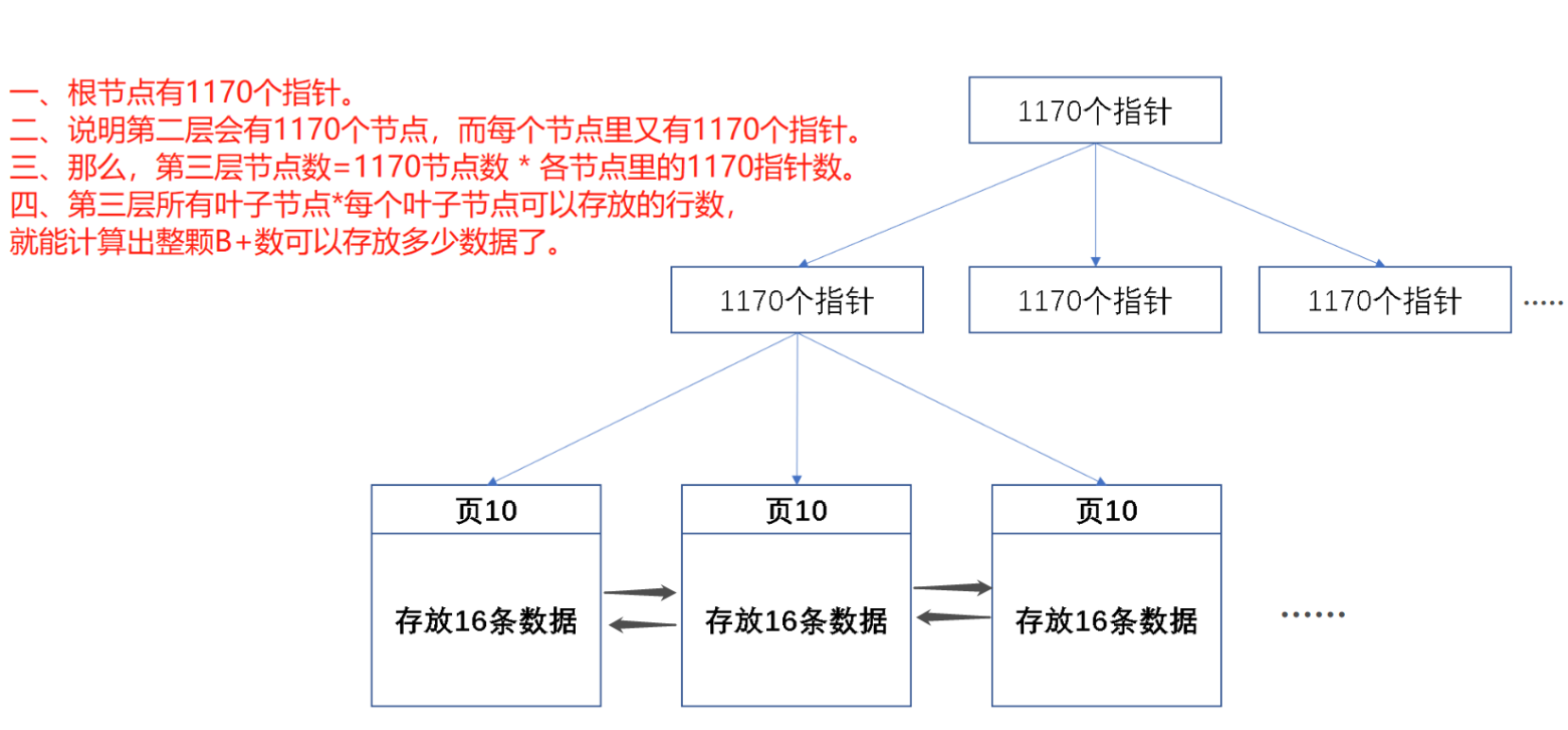
假设:
- 节点大小为16KB(MySQL默认页大小),键值(索引)为8字节(如BIGINT),指针为6字节(指向子节点或数据)。
- 非叶子节点:每个节点存储
16KB/(8+6B)≈1170个键值对。 - 叶子节点:每个节点存储数据(假设一行数据1KB),则每个叶子节点存16条数据。
- 三层B+树结构:
-
- 第一层(根节点):1个节点,1170个子节点。
- 第二层(中间层):1170个节点,每个节点1170个子节点,共
1170×1170个叶子节点。 - 第三层(叶子层):
1170×1170×16≈ 22 million(约2200万) 条数据。
三、HTTPS与HTTP的区别
| 特性 | HTTP | HTTPS |
| 端口 | 80 | 443 |
| 安全性 | 明文传输,无加密 | 基于TLS/SSL加密,防篡改、窃听 |
| 证书 | 无需证书 | 需要CA机构颁发的SSL证书 |
| 性能 | 低延迟,适合简单场景 | 需握手协商加密参数,延迟略高 |
| 信任机制 | 无 | 通过数字证书验证服务器身份 |
四、Redis持久化
1. 持久化方式
- RDB(快照):定期将内存数据全量写入磁盘,生成二进制文件(
.rdb)。 - AOF(日志):记录每条写命令,重启时重放命令恢复数据。
2. AOF快照形式
AOF文件以文本形式存储命令(如SET key value),可通过BGREWRITEAOF压缩日志(合并同类命令,如先INCR后DECR可合并为SET)。
3. RDB快照原理(BGSAVE)
- fork子进程:主进程执行
BGSAVE时,通过操作系统fork创建子进程,子进程共享主进程内存数据。 - 写入快照:子进程将内存数据按RDB格式写入磁盘,主进程继续处理请求,避免阻塞。
- 替换旧文件:写入完成后,用新快照文件替换旧文件,重启时通过加载
.rdb恢复数据。
五、虚拟内存与页表
1. 虚拟内存
- 概念:操作系统为每个进程分配的独立地址空间(如32位系统为4GB),通过内存与磁盘的换入换出(Swap),允许程序使用超过物理内存的空间。
- 作用:
-
- 隔离进程地址空间,避免内存冲突。
- 支持大程序运行,通过分页机制(Page)将不常用数据暂存磁盘。
2. 页表
- 概念:虚拟地址到物理地址的映射表,存储每个页(Page,如4KB)对应的物理内存地址或磁盘位置。
- 结构:
-
- 一级页表:适用于小内存系统,虚拟地址直接对应页表项。
- 多级页表:如二级页表,将虚拟地址分为目录和页号,减少页表内存占用(如x86的CR3寄存器指向页目录)。
- 查询过程:CPU通过MMU(内存管理单元)查询页表,若页不在内存中(缺页中断),则从磁盘加载到内存。
六、Redis内存占用比预期大的原因
- 数据结构额外开销:
-
- 例如,存储字符串
"a"时,Redis使用sdshdr结构体(包含长度、容量、标志位等),实际占用内存大于1字节。 - 哈希表、列表等复杂结构需存储指针、长度等元数据。
- 例如,存储字符串
- 内存对齐与分配策略:
-
- Redis按2的幂次分配内存(如存储10字节数据,分配16字节空间),避免频繁申请小块内存导致的碎片。
- 操作系统分配内存时的对齐要求(如8字节对齐)也会增加占用。
- 持久化与复制机制:
-
- RDB/AOF文件生成时的临时内存开销,主从复制时的缓冲区等。
七、分库分表的适用场景
- 单表数据量过大:如单表超过500万条,查询性能显著下降(索引效率降低,磁盘I/O增加)。
- 高并发导致性能瓶颈:单机数据库连接数、CPU/内存资源不足,无法支撑请求量。
- 数据热点问题:某部分数据被频繁访问(如社交APP的用户消息表),需分散到不同库表。
- 业务垂直拆分:按功能模块分库(如用户库、订单库),降低耦合度,便于扩展。
- 跨地域/多租户需求:数据需按区域或租户隔离存储(如多商户SaaS系统)。
注意:分库分表会引入分布式事务、跨库查询等复杂性,需权衡使用(如优先优化索引、读写分离,再考虑分库分表)。

)




