数据库所能承载的连接数、I/O及网络的吞吐等都是有限的,当我们存在数据库里面的数据越来越多,此时的数据库就会产生瓶颈,出现资源报警、查询慢等场景,如果单表的数据量过大,查询的性能也会下降,数据越多B+树就越高,树越高则查询 I/O 的次数就越多,那么性能也就越差
数据拆分有两种方式:
垂直拆分: 根据业务的维度,将原本一个库中的表拆分多个表,每个库中表与原有的结构不同水平拆分: 根据分片算法,将一个库拆分成多个库,每个库依旧保留原有的结构
分库
分库将以前存在一个数据库实例里的数据拆分成多个数据库实例,部署在不同的服务器上,主要目的是为了解决服务器资源受单机限制,顶不住高并发访问的问题,把请求分配到多台服务器上,降低服务器压力
拆分策略
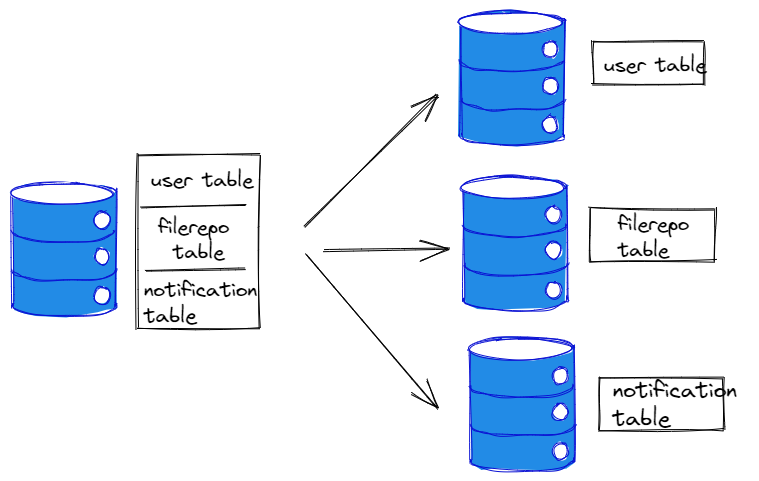
垂直拆分
依据业务的耦合性进行拆分,将关联度低的不同表拆分到不同库中,每个库的表结构都不一样,每个库的数据也不一样,所有库的并集是全量数据,就像我们的微服务,每个微服务就是一个独立业务功能
水平拆分
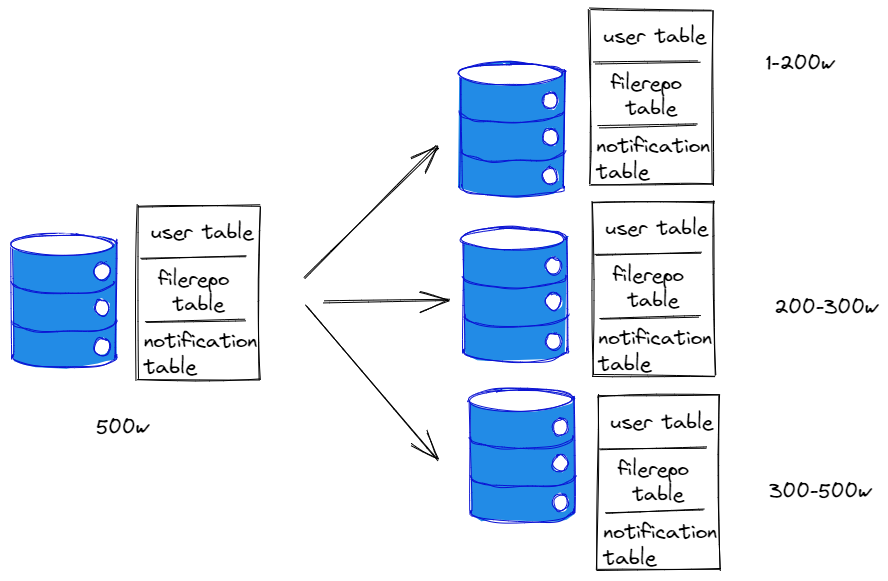
以字段为依据,按照一定策略,将一个库的数据拆分到多个库中,每个库的表结构都一样、每个库的数据都不一样、所有库的并集是全量数据,比如我们的user table,1到200w记录的放在第一个库,200-330w放到第二个库,以此类推
分库带来的问题
事务
分库之后单机事务就用不上了,必须使用分布式事务

)




