Idea中编写Spark程序
一、修改pom.xml文件
-
<build> -
<sourceDirectory>src/main/scala</sourceDirectory> -
<testSourceDirectory>src/test/scala</testSourceDirectory> -
<!-- 添加必要的插件以打包scala程序--> -
<plugins> -
<plugin> -
<groupId>net.alchim31.maven</groupId> -
<artifactId>scala-maven-plugin</artifactId> -
<version>3.4.6</version> -
<executions> -
<execution> -
<goals> -
<goal>compile</goal> -
<goal>testCompile</goal> -
</goals> -
</execution> -
</executions> -
<configuration> -
<args> -
<arg>-dependencyfile</arg> -
<arg>${project.build.directory}/.scala_dependencies</arg> -
</args> -
</configuration> -
</plugin> -
<plugin> -
<groupId>org.apache.maven.plugins</groupId> -
<artifactId>maven-shade-plugin</artifactId> -
<version>2.4.3</version> -
<executions> -
<execution> -
<phase>package</phase> -
<goals><goal>shade</goal></goals> -
</execution> -
</executions> -
<configuration> -
<filters> -
<filter> -
<artifact>*:*</artifact> -
<excludes> -
<exclude>META-INF/*.SF</exclude> -
<exclude>META-INF/*.DSA</exclude> -
<exclude>META-INF/*.RSA</exclude> -
</excludes> -
</filter> -
</filters> -
<transformers> -
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> -
<mainClass></mainClass> -
</transformer> -
</transformers> -
</configuration> -
</plugin> -
</plugins> -
</build>
二、修改代码
修改两个地方:输入目录改成args(0), 输出的目录改成args(1)。
-
import org.apache.spark.{SparkConf, SparkContext} -
object WordCount_online { -
// 写一个spark程序,统计input目录下所有文本文件中单词的词频 -
// 把结果保存在output下 -
def main(args: Array[String]): Unit = { -
// println("hello spark!") -
// 配置 Spark 应用程序 -
val conf = new SparkConf().setAppName("WordCount_online") -
// 创建 SparkContext 对象 -
val sc = new SparkContext(conf) -
// 读取目录下的所有文本文件 -
val textFiles = sc.wholeTextFiles(args(0)) -
// 提取文本内容并执行 WordCount 操作 -
val counts = textFiles -
.flatMap { case (_, content) => content.split("\\s+") } -
.map(word => (word, 1)) -
.reduceByKey(_ + _) -
// 将所有分区的数据合并成一个分区 -
val singlePartitionCounts = counts.coalesce(1) -
// 保存结果到文件 -
singlePartitionCounts.saveAsTextFile(args(1)) -
// 停止 SparkContext -
sc.stop() -
} -
}
三、打包
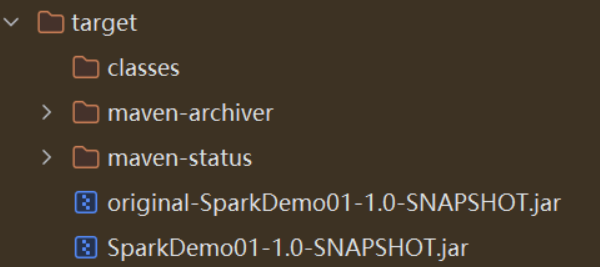
四、上传到集群
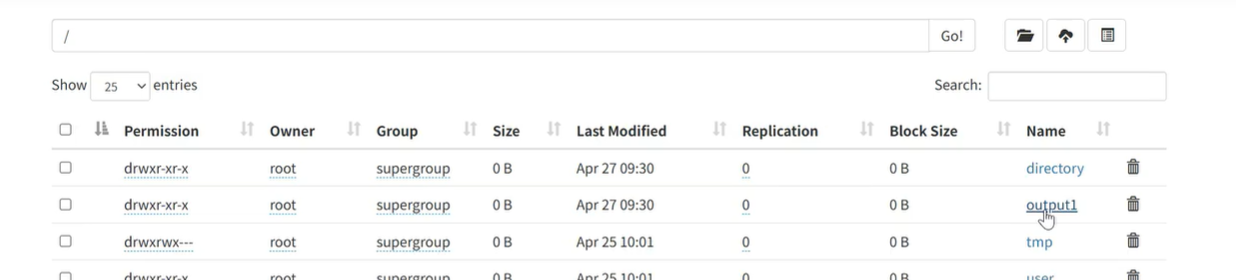
命令为:[root@hadoop100 sbin]# spark-submit --class WordCount_online --master yarn /opt/module/original-untitled-1.0-SNAPSHOT.jar /wcinput /output1
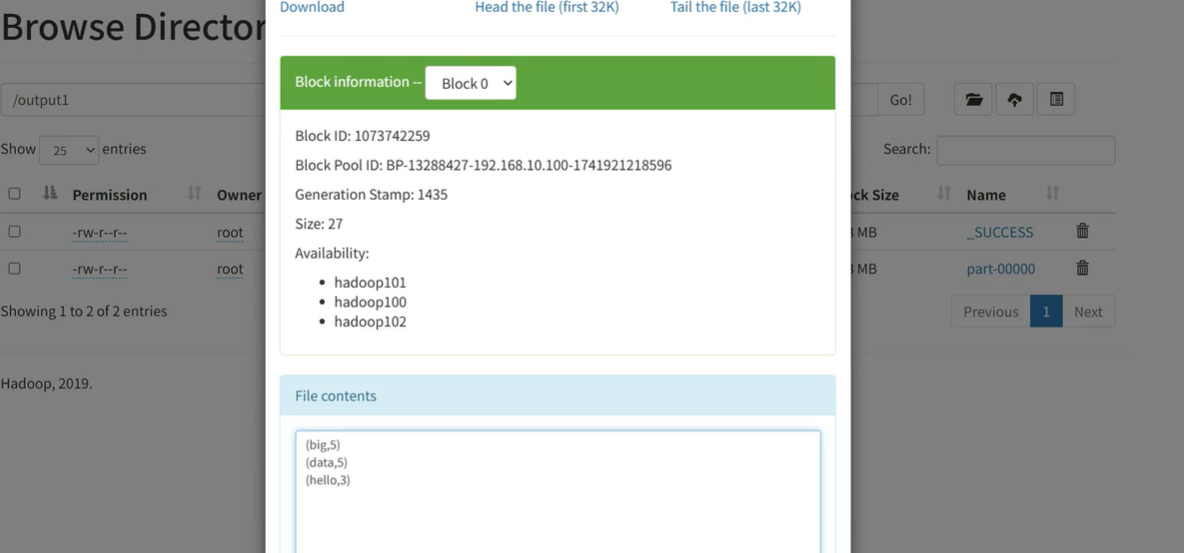
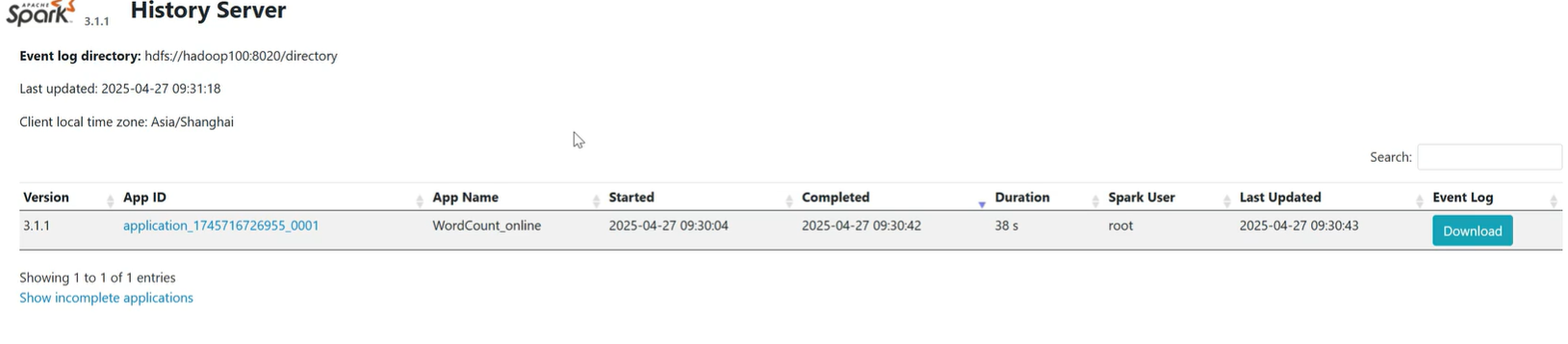
出现结果如下即为运行成功

、地图打印(webprinting)等服务)

——日期类和const成员函数)


