【强化学习】——04Model-Based RL
一、基于模型的强化学习
\quad\quad 强化学习算法一般有两个评价指标:
\quad\quad \quad\quad 一是,算法收敛后的策略在初始状态下的期望回报
\quad\quad \quad\quad 二是,算法达到收敛结果需要的样本数量
\quad\quad 基于模型的算法得益于这个环境模型,Agent对真实环境中的样本量的需求往往会减少
\quad\quad 通常具备较低的样本复杂度,但由于环境模型不可能完全准确,因此其期望回报通常较低
- 简介:
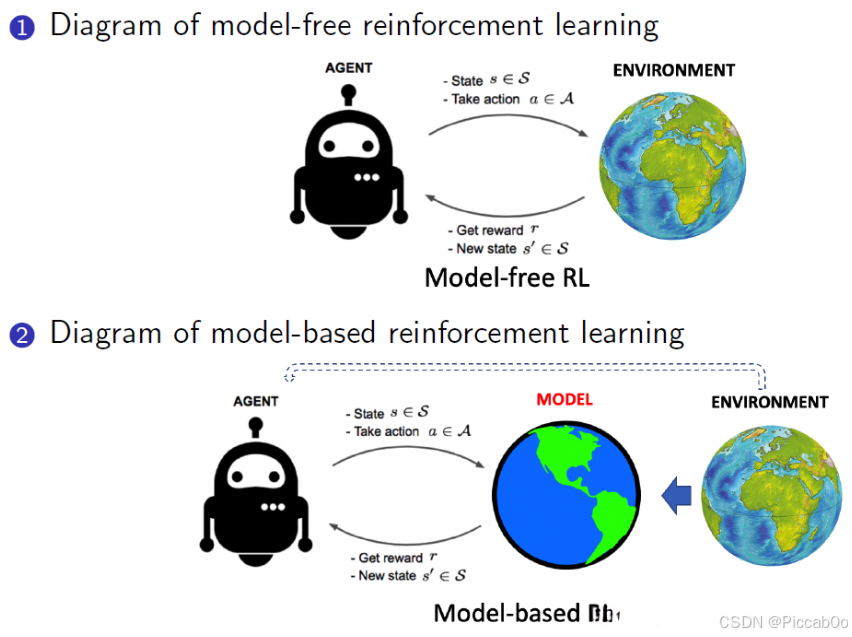
\quad\quad 之前的Model-Free RL中,Agent只可以与环境进行交互
\quad\quad 如果环境模型已知,那么Agent可以与模型进行交互,基于模型来规划或决策
\quad\quad 这个模型的作用在于提供环境状态转移概率和预测生成的奖励,以产生或优化策略
- 环境模型 M ( P , R ) M(P,R) M(P,R)的组成:
\quad\quad 状态转移函数 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a)
\quad\quad 奖励函数 R ( s , a ) R(s,a) R(s,a)
- 核心思路:
\quad\quad 模型学习:学习或构建环境的动态模型和奖励函数
\quad\quad \quad\quad 基于数据驱动的方法:监督学习,通过收集到的数据对模型进行训练
\quad\quad \quad\quad 基于物理规律的方法:基于机器人的动力学方程建立模型
\quad\quad 规划:基于模型进行推理,找到最优策略
\quad\quad \quad\quad MPC
\quad\quad \quad\quad DP
\quad\quad




