1、问题来源
在工业物联网领域,采集点位多,采集频率高,数据的顺序要求也很高。
这样在处理采集过滤的消息时高效的保证数据的不重就非常必要了。
就拿我手上的项目来说,峰值时每秒钟需要清洗2000+条物联网设备采集过来的各种指标数据。平均下来就是需要每0.5毫秒处理完一条数据。
2、可选的方案
做幂等性校验有很多方案,但是要满足上面的0.5毫秒内处理幂等性和业务逻辑的就不多了。
局域网内部1个ping包的平均耗时就有0.1毫秒左右,再加上业务中有排重、比较大小、生产消息到kafka、写日志、读写redis中的数据进行校验等。所以需要尽可能的使用本地缓存。
1) jdk本身的ConcurrentHashMap来做校验,key为消息的hashcode,值为此hashcode的消息内容列表,因为hashcode有碰撞的概率,无法做到完全唯一,这种方法有个比较大的问题,就是内存的使用量会一直升高,导致GC频繁,而业务上其实仅需要保证近10分钟内不重就行,适合单节点方案
2) 使用工具包中的 Caffeine的缓存方案,可以设置缓存的过期时间,用法上与ConcurrentHashMap差不多,适合单节点方案
3) 使用redis或者memcached来存储处理过的消息,每来一条都进行校验,此种方案有网络开销,比较耗时,只能作为重启应用是本地缓存清空了的兜底方案,适合分布式部署的情况
4) 使用布隆过滤器+本地缓存,尽可能使用本地校验,不确定的情况下再使用中心缓存进行校验,适合单节点部署的情况
3、最终方案
选择方案4,由于大部分消息内容是不会重复的,先使用本地的布隆过滤器校验,不存在直接返回不重复,布隆过滤器返回存在再用消息内容去和本地缓存比较,如存在则返回重复,如不存在则不重复。针对任务重启时布隆过滤器和本地缓存失效的问题,在开始处理业务逻辑前判断缓存是否为空,为空的情况下将数据库表中近最近时间往前推10分钟的数据查询出来加载到布隆过滤器和缓存中去,然后再进行业务逻辑处理。
这个方案的好处是充分利用本地缓存,有几极致的性能表现, 使用arthas监控校验方法,每条数据校验仅耗时0.02毫秒,加上写入布隆过滤器和本地缓存耗时0.04毫秒,那么幂等性校验功能总共耗时0.06毫秒。
幂等性校验
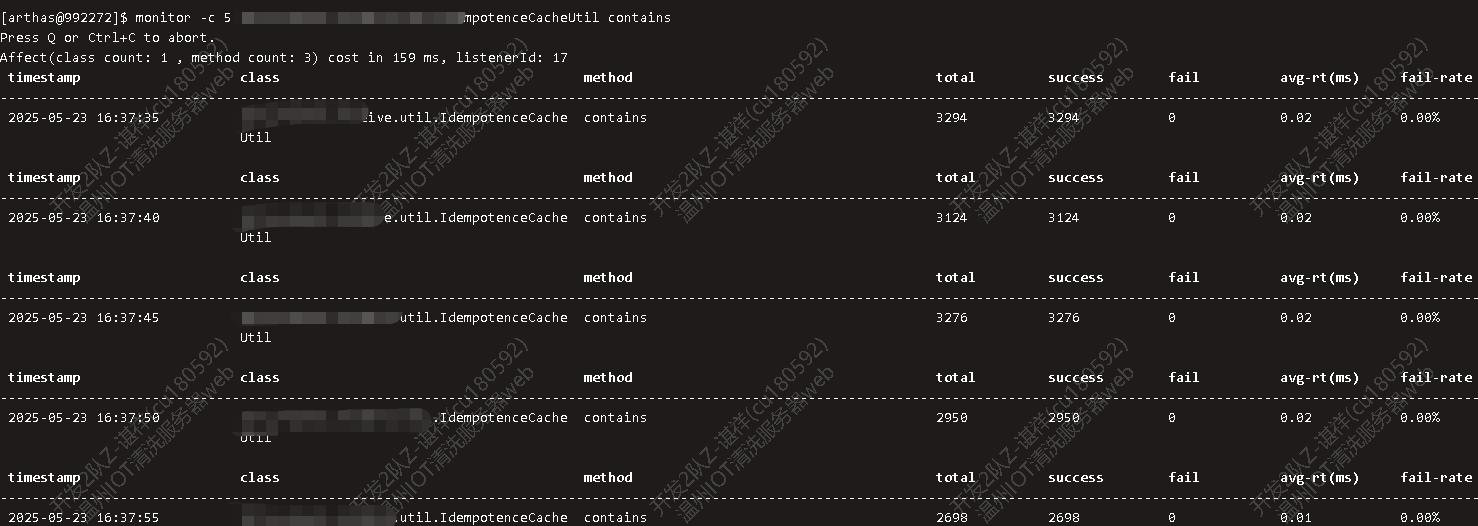
写入布隆过滤器和缓存

处理业务逻辑耗时
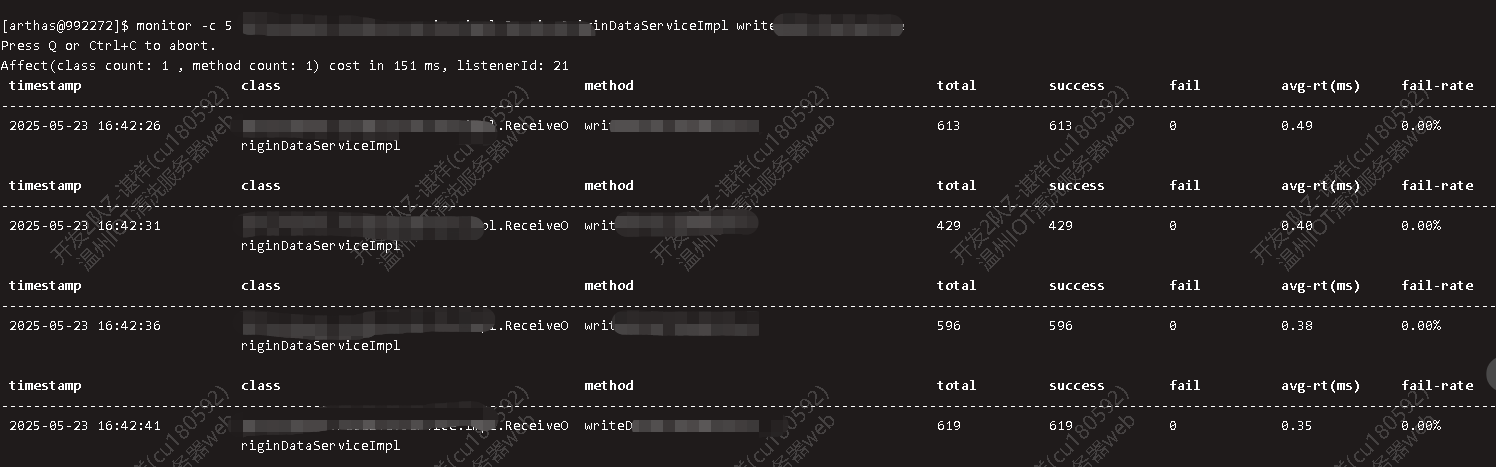
4、检查是否达到了预期效果
从上面的结果来看是达到了预期的效果,通过arthas的monitor命令每5秒钟统计一次,包含幂等性校验在内,整个业务逻辑平均0.4毫秒左右可以处理完成,符合预期/

)
感知机)


