1、向量存储的工作原理
在向量数据库中,查询与传统关系型数据库有所不同。向量库执行的是相似性搜索,而非精确匹配,具体流程我们在上一节教程中有了解,可以再复习下。
- 嵌入转换:当文档被添加到向量存储时,Spring AI 会使用嵌入模型(如 OpenAI 的text-embedding-ada-002)将文本转换为向量。
- 相似度计算:查询时,查询文本同样被转换为向量,然后系统计算此向量与存储中所有向量的相似度。
- 相似度度量:常用的相似度计算方法包括:①余弦相似度:计算两个向量的夹角余弦值,范围在-1到1之间;②欧氏距离:计算两个向量间的直线距离;③点积:两个向量的点积值
- 过滤与排序:根据相似度阈值过滤结果,并按相似度排序返回最相关的文档
2、基于 PGVector 实现向量存储
PGVector 是经典数据库 PostgreSQL 的扩展,为 PostgreSQL 提供了存储和检索高维向量数据的能力。
为什么选择它来实现向量存储呢?因为很多传统业务都会把数据存储在这种关系型数据库中,直接给原有的数据库安装扩展就能实现向量相似度搜索、而不需要额外搞一套向量数据库。
1、首先打开 阿里云 PostgreSQL 官网,开通 Serverless 版本
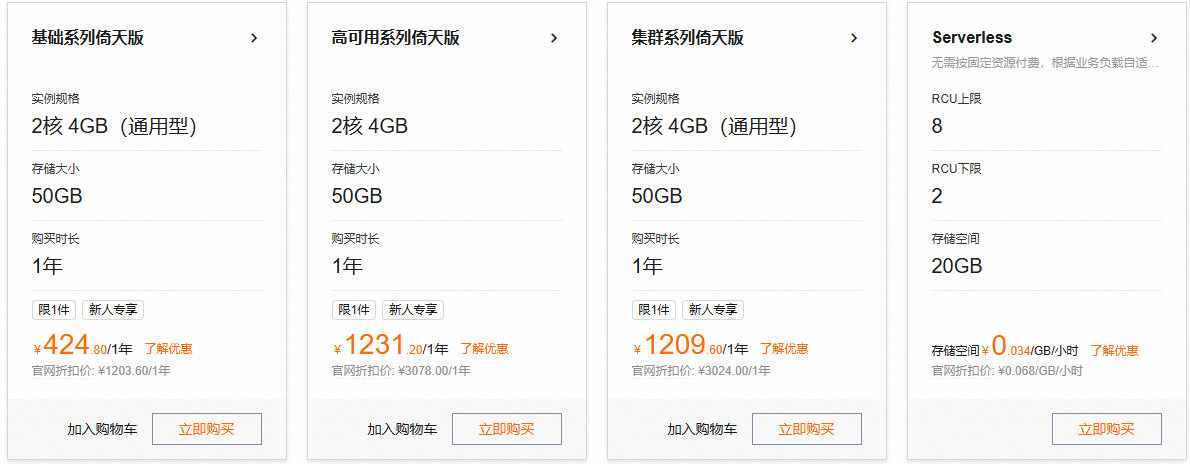
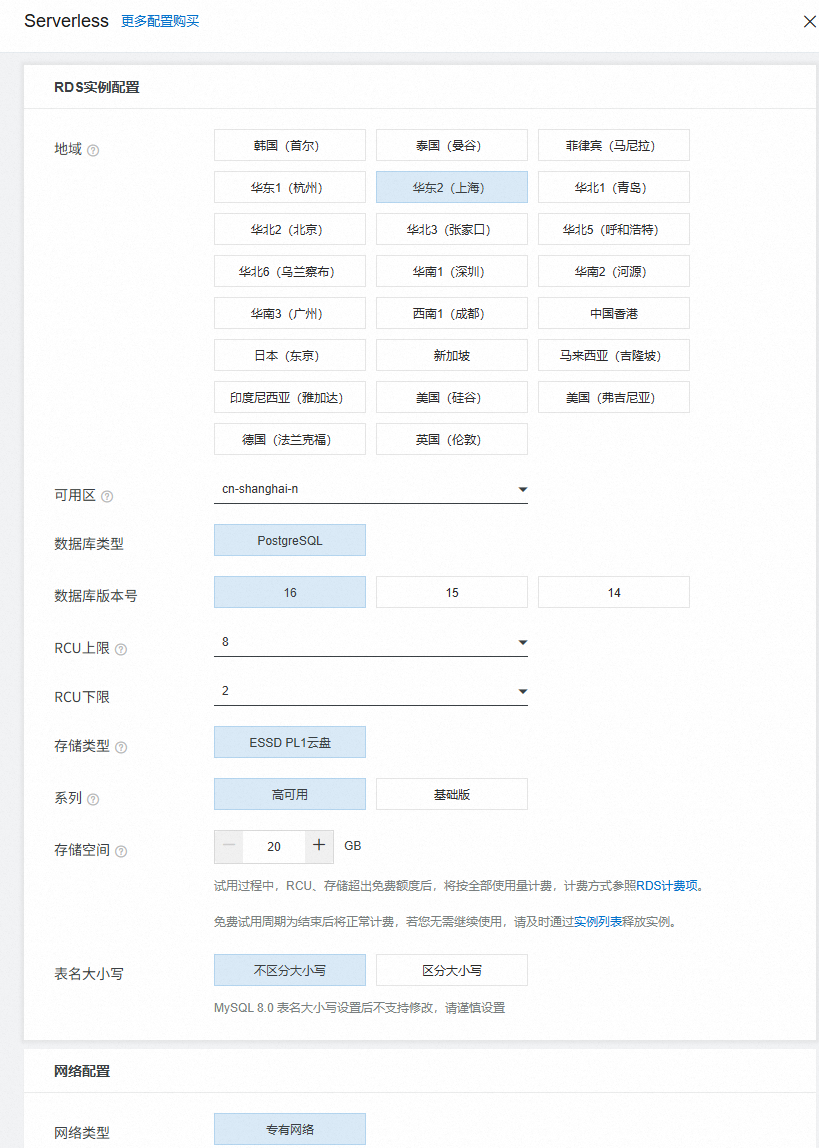
2、开通 Serverless 数据库服务,填写配置:
3、开通成功后,进入控制台,先创建账号:

4、然后创建数据库:

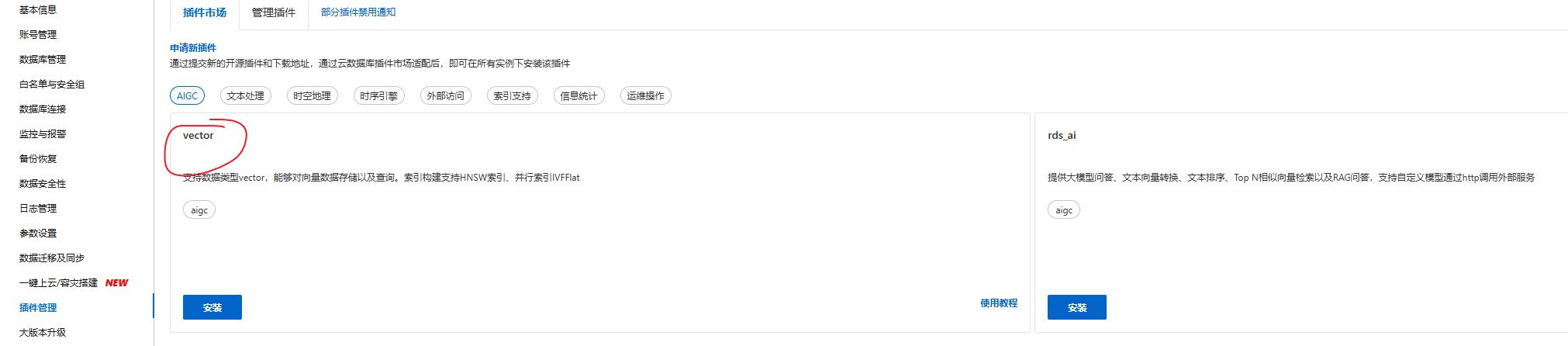
5、进入插件管理,安装 vector 插件:
6、进入数据库连接,开通公网访问地址:

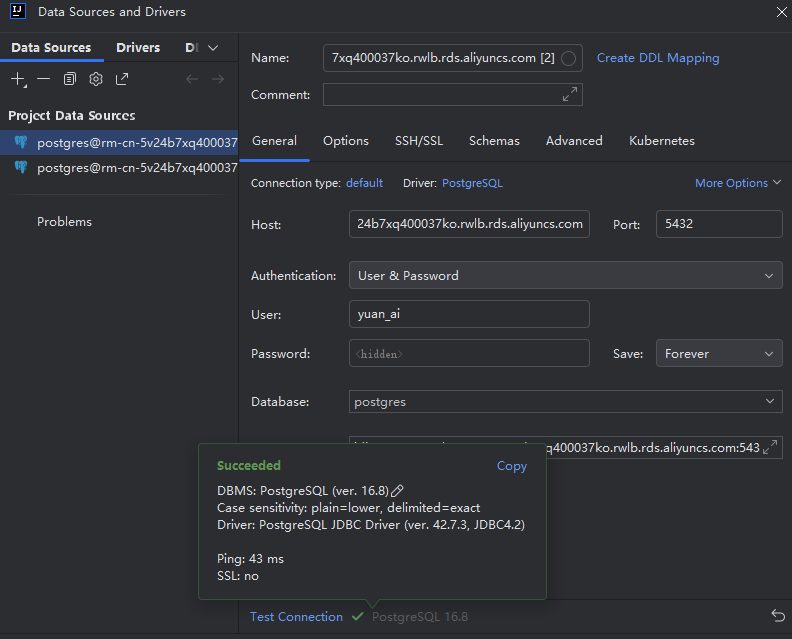
7、可以在本地使用 IDEA 自带的数据库管理工具,进行连接测试:
8、引入依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-pgvector</artifactId><version>1.0.0-M7</version>
</dependency>
9、编写配置,建立数据库连接:
spring:datasource:url: jdbc:postgresql://改为你的公网地址/yu_ai_agentusername: 改为你的用户名password: 改为你的密码ai:vectorstore:pgvector:index-type: HNSWdimensions: 1536distance-type: COSINE_DISTANCEmax-document-batch-size: 10000 # Optional: Maximum number of documents per batch
由于项目同时引入了 Ollama 和 阿里云 Dashscope 的依赖,有两个 EmbeddingModel 的 Bean,Spring 不知道注入哪个,就会报错误。
10、换一种更灵活的方式来初始化 VectorStore
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><scope>runtime</scope>
</dependency>
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pgvector-store</artifactId><version>1.0.0-M6</version>
</dependency>11、编写配置类自己构造 PgVectorStore
@Configuration
public class PgVectorVectorStoreConfig {@Beanpublic VectorStore pgVectorVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel dashscopeEmbeddingModel) {VectorStore vectorStore = PgVectorStore.builder(jdbcTemplate, dashscopeEmbeddingModel).dimensions(1536) // Optional: defaults to model dimensions or 1536.distanceType(COSINE_DISTANCE) // Optional: defaults to COSINE_DISTANCE.indexType(HNSW) // Optional: defaults to HNSW.initializeSchema(true) // Optional: defaults to false.schemaName("public") // Optional: defaults to "public".vectorTableName("vector_store") // Optional: defaults to "vector_store".maxDocumentBatchSize(10000) // Optional: defaults to 10000.build();return vectorStore;}
}12、并且启动类要排除掉自动加载
@SpringBootApplication(exclude = PgVectorStoreAutoConfiguration.class)
public class YuAiAgentApplication {public static void main(String[] args) {SpringApplication.run(YuAiAgentApplication.class, args);}}13、编写单元测试类,验证效果
@SpringBootTest
public class PgVectorVectorStoreConfigTest {@ResourceVectorStore pgVectorVectorStore;@Testvoid test() {List<Document> documents = List.of(new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", Map.of("meta1", "meta1")),new Document("The World is Big and Salvation Lurks Around the Corner"),new Document("Spring AI 改变了后端开发的思维方式。", Map.of("标签", "技术")),new Document("生活就像一盒巧克力,你永远不知道下一颗是什么味道。"),new Document("知足者常乐,善待自己,热爱生活。", Map.of("标签", "哲学")))new Document("You walk forward facing the past and you turn back toward the future.", Map.of("meta2", "meta2")));// 添加文档pgVectorVectorStore.add(documents);// 相似度查询List<Document> results = pgVectorVectorStore.similaritySearch(SearchRequest.builder().query("Spring").topK(5).build());Assertions.assertNotNull(results);}
}我们在控制台中查看
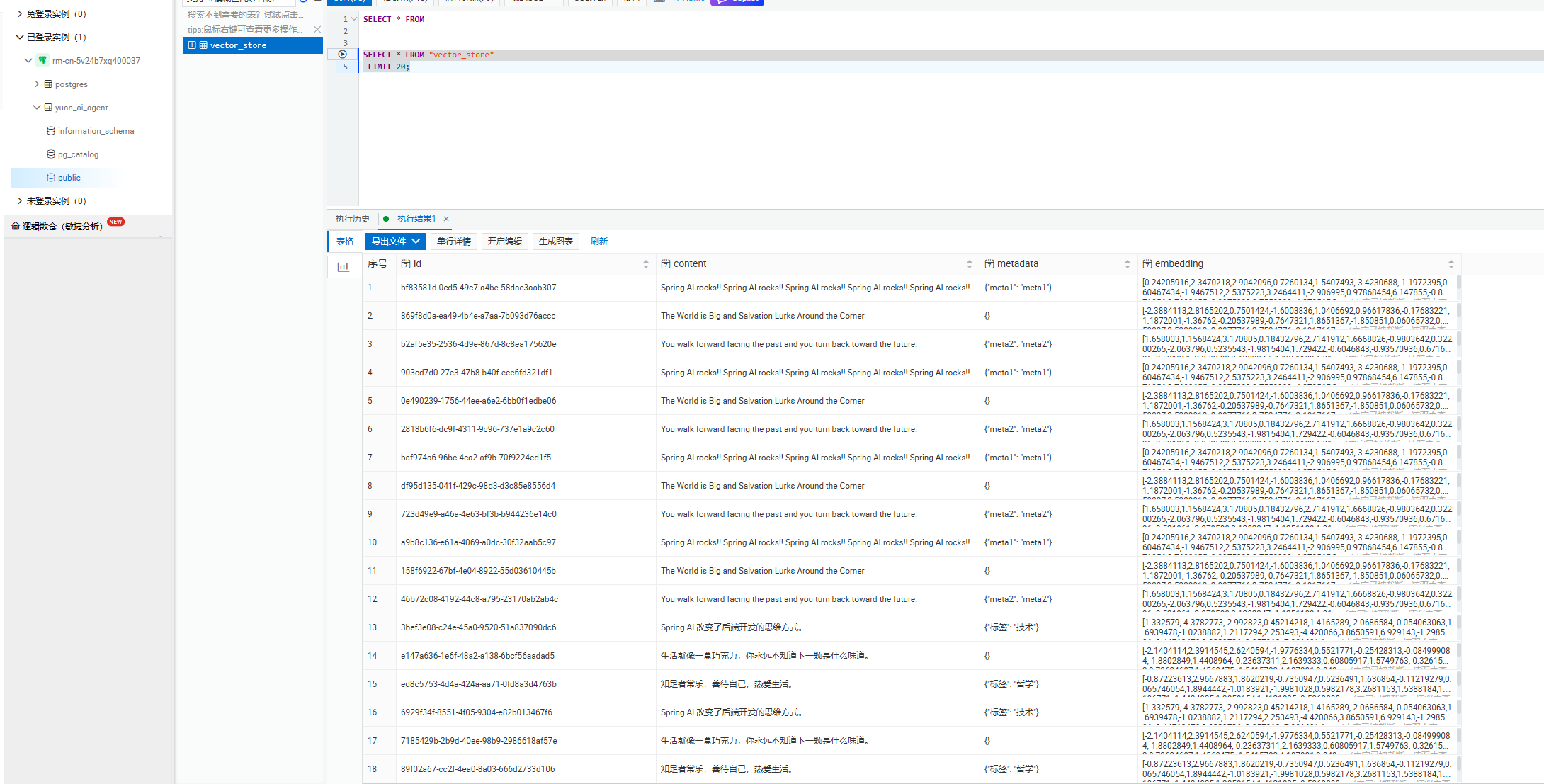
debug模式查看分数 score







