库操作
数据库的编码
查看默认的字符集以及校验规则
字符集本质
本质:字符集定义了字符与字节之间的映射规则,即:一个字符在数据库中是如何编码存储的
字符集用途
| 用途 | 说明 |
|---|---|
| ✅ 存储和读取字符串 | 决定了字符串在磁盘或内存中用什么样的二进制编码格式表示。例如:utf8 编码一个字符可能占用 13 个字节,utf8mb4 可占用 14 个字节。 |
| ✅ 字符兼容性 | 不同字符集支持的语言/字符范围不同。例如:latin1 适合英语;utf8 适合大部分语言;utf8mb4 支持 Emoji 等 4 字节字符。 |
| ✅ 数据传输正确性 | 客户端和服务器使用不同字符集可能导致乱码,设置统一字符集可以避免编码/解码失败。 |
查看默认字符集
show variables like 'character_set_database';
校验规则的本质
校验规则定义了字符串之间如何进行比较和排序,即:两个字符串在“逻辑上”是否相等、哪个在前哪个在后。
校验规则的用途
| 用途 | 说明 |
|---|---|
| ✅ 字符串比较 | 决定 =、<>、LIKE 等操作的行为。例如,'a' = 'A' 在区分大小写规则下为 false,但在不区分大小写规则下可能为 true。 |
| ✅ 排序(ORDER BY) | 校验规则决定排序的先后顺序。例如,utf8_general_ci 会把 'a' 和 'A' 视为相同,utf8_bin 会严格按照二进制排序(区分大小写)。 |
| ✅ 索引命中效率 | 某些规则对比较性能优化(如 _general_ci 相比 _unicode_ci 更快但不够精细),对 LIKE 查询和索引的使用有影响。 |
| ✅ 多语言支持 | 不同语言的排序规则不同,比如德语的 ß 是否等于 ss,这些都由校验规则决定。 |
查看默认的校验规则
show variables like 'character_set_database';
查看数据库支持的字符集和校验规则
查看数据库支持的字符集
show charset;查看数据库支持的校验规则
show collation;校验规则对数据库的影响
创建数据库案例
字符集和校验规则mysql采取就近原则,如果没有显示进行声明的话,采用配置文件中的方式进行。
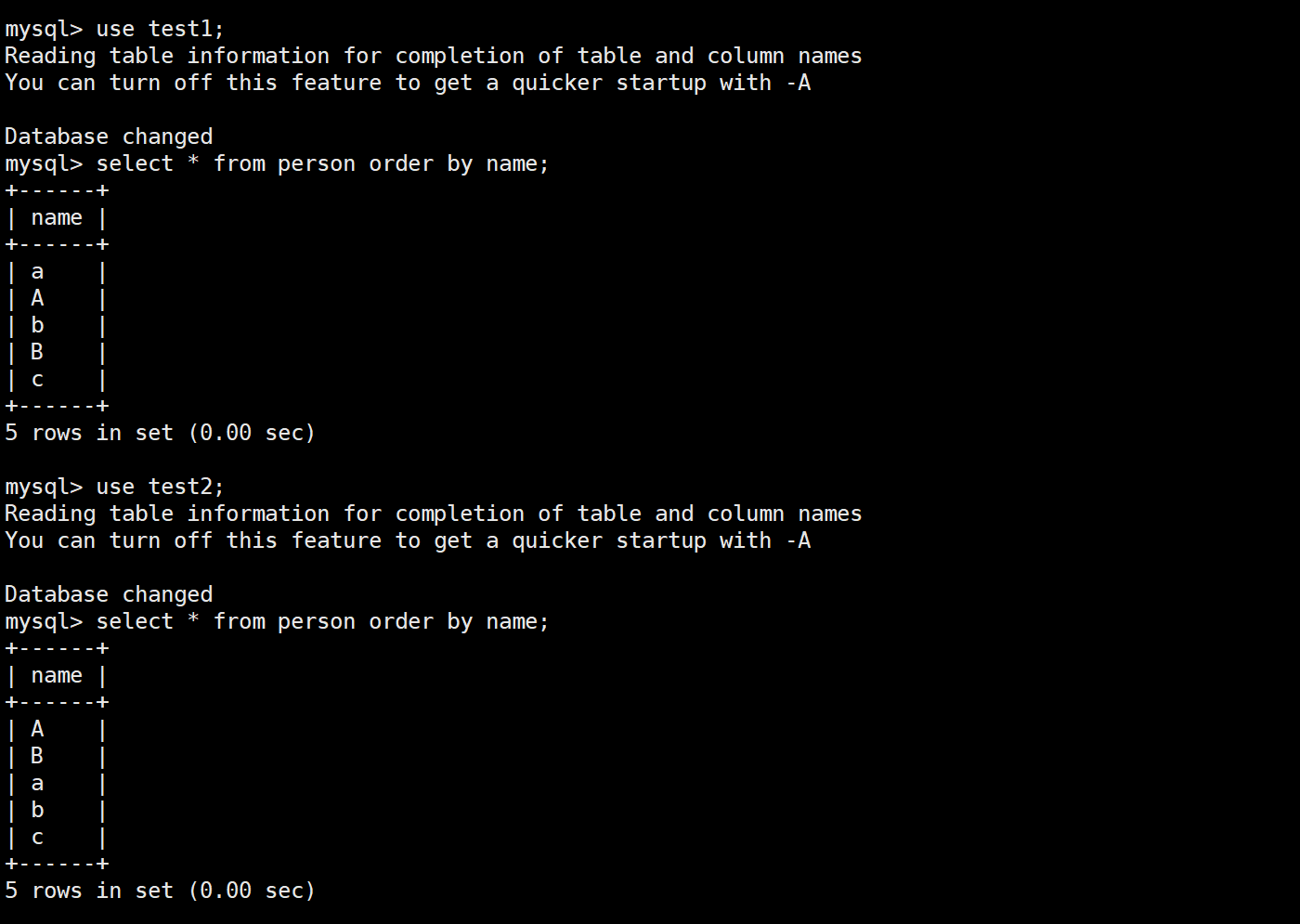
进行创建两个校验规则不同的表
其中utf8mb4_general_ci是不区分大小写,utf8mb4_bin 区分大小写

在两个数据库的表中进行插入相同地方数据

进行查找a验证是否区分大小写

利用排序进行观察是否区分大小写
数据库的操作
增删改查
注:db_name:代表数据库名称
创建数据库
create database db_name;删除数据库
drap database 数据库名称;修改数据库
对数据库的修改主要指的是修改数据库的字符集,校验规则
alter database db_file charset= ;alter database db_file collate= ;或者通过一行命令进行
alter database db_file charset= collate= ;查看数据库
查看已将创建完成的数据库
show databases;查看创建数据库时的语句
show create database db_name;
数据库的备份和恢复
提到对数据库进行备份,相信大多数人想到的是直接将数据库文件进行拷贝一份在指定的目录下不就可以了吗
| 对比维度 | 直接拷贝数据库文件 | 使用 mysqldump 工具 |
|---|---|---|
| 类型 | 物理备份(文件级) | 逻辑备份(SQL语句级) |
| 操作方式 | 拷贝 .ibd、.frm、.ibdata1 等文件 | 导出为 .sql 文件(可读) |
| 数据一致性 | ❌ 极易不一致(运行中拷贝有风险) | ✅ 支持事务一致性(--single-transaction) |
| 是否需要停机 | ✅ 通常需关闭 MySQL 服务 | ❌ 可在线执行备份(推荐用于 InnoDB) |
| 还原方式 | 较复杂,需要文件结构完整 | 简单:mysql < xxx.sql 即可 |
| 可读性 | ❌ 二进制不可读 | ✅ SQL 文本,可查看、编辑 |
| 可移植性 | ❌ 与系统/版本/存储引擎强相关 | ✅ 跨版本/跨系统迁移灵活 |
| 粒度控制 | ❌ 拷贝整个数据库目录 | ✅ 可指定库、表、数据、结构等 |
进行备份
mysqldump -P port -u user -p -B db_name > 备份存储的路径 

通过cat 进行打印进行备份的信息发现备份的信息中不仅有数据还有执行的操作,把我们整个创建数据库,建表,导入数据的语句都装载这个文 件中。
注:
如果备份的不是整个数据库,而是其中的一张表,怎么做?
mysqldump -u root -p 数据库名 表名1 表名2 > 路径文件同时备份多个数据库 # mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径
ysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径 进行恢复数据
mysql> source 路径文件;如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用 source来还原
表操作
表的操作就是传统意义上的增删改查
创建表
create table table_name(field1 datatype,field2 datatype,field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;说明:
- field:表示列名
- datatype:表示列的类型
- character set: 字符集如果没有指定字符集则以所在数据可的字符集为准
- collate 校验规则:如果没有指定校验规则,则以所在的数据库的校验规则为准
注意事项:
创建表的时候只有最后一个列的后面不需要使用 逗号 ,其他的列名的后面需要 逗号。
创建实例

32位的 MD5 值,指的是 MD5(Message Digest Algorithm 5) 摘要算法生成的标准输出 —— 一个 128 位(16 字节) 的哈希值,通常以 32 个十六进制字符 表示。
查看表
desc 表名;
修改表
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型,表的存储引擎 等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。但是修改表结构是一个高危操作,非常容易影响上层的业务逻辑和接口兼容性。
最好的方式就是在初期就进行敲定表的结构。
修改内容及对应的结果分析
| 修改内容 | 影响分析 |
|---|---|
| 字段名称(列名) | 上层代码通常直接使用字段名,修改会导致 SQL 报错、ORM 映射失败,接口崩溃 |
| 字段类型(如 INT 改为 VARCHAR) | 会导致数据格式转换错误、数据丢失、业务逻辑判断失败 |
| 字段顺序 | 虽然表面上无影响,但某些旧系统、ORM 或序列化方式可能依赖字段顺序 |
| 字段是否为主键或唯一约束 | 改动会影响主键约束逻辑、数据唯一性验证、业务识别机制,如用户ID等 |
| 字段是否为非空(NOT NULL) | 若已有 NULL 值,设置为非空会报错;反之则可能破坏原有的数据完整性约束 |
| 删除字段 | 上层如果还有代码读取该字段,会直接出错(SELECT 出现 Unknown column) |
| 修改或删除默认值 | 可能影响数据插入时的默认行为,进而改变程序逻辑,尤其是表单中未提供字段的情况 |
| 修改表名或库名 | 会影响所有引用该表的 SQL、代码、存储过程、视图、权限配置等 |
| 改动索引(删除/改类型) | 可能影响查询性能,导致原本毫秒级的查询变成慢查询,从而拖垮业务 |
修改表的操作
1.添加字段
ALTER TABLE 表名 ADD 列名 数据类型 [约束条件] [AFTER 某列名];2. 修改字段类型或约束
ALTER TABLE 表名 MODIFY 列名 新数据类型 [新的约束];
3. 重命名字段(修改列名 + 类型)
ALTER TABLE 表名 CHANGE 旧列名 新列名 新数据类型;
重命名表明后新字段需要完整定义。
4. 删除字段
ALTER TABLE 表名 DROP COLUMN 列名;
5. 重命名表名
RENAME TABLE 原表名 TO 新表名;
或
ALTER TABLE 原表名 RENAME TO 新表名;
删除表
drop table table_name;



