nni_pruning_distillation_demo
使用NNI剪枝工具对VGG16网络进行剪枝,同时使用知识蒸馏对剪枝后结果进行优化。(以猫狗二分类为例)
Github代码:https://github.com/zhahoi/nni_pruning_distillation_demo
写在前面
一直以来,对于工程上用到的深度学习算法,我只是简单地训练、然后尝试部署模型,几乎没有从性能方面考虑如何对模型进行压缩,使模型可以在很有限的资源下部署和运行。曾经面试的时候有被问过会不会“模型的剪枝和量化”,我当时只说自己了解过,没有过相关的经验。
确实,光把模型训练部署起来是远远不够的,如果模型占用资源过大,可能会影响算法的实时性,也会影响其他算法或者设备正常工作。于是,决定痛定思痛,打算探究一下“模型压缩”相关的知识,该项目是本人学习"深度学习模型压缩"的首次尝试,这里仅作记录。
本项目以NNI提供的官方实例为基础,尝试自己在VGG16上实现剪枝和蒸馏过程。代码编写完成并进行实际测试后发现,确实可以实现“压缩模型大小"和”保持检测精度“的效果。本项目虽然十分简单,但对于理解模型压缩原理和流程来说,有一定的参考价值。
环境配置
本项目最主要的依赖库为nni,我在实际安装时发现和我本地的环境存在冲突,经过一顿查询,发现只要保证以下库的版本正确,就基本不会报错:
nni==3.0
numpy==1.26.0
torch==2.1.0
数据集准备
本项目测试所使用的数据集下载自kaggle,数据集下载链接如下:dog-vs-cat。选择该数据集的目的是因为该数据集比较小,同时相对简单,咱就主打一个简单易用就好。数据集下载完成之后,对其进行解压,将"animals"文件夹下的"dog"和"cat"文件夹拷贝到本项目的"animals"文件夹下。
之后,执行以下脚本对数据集进行7:3划分:
$ python .\split_dataset.py
模型训练
为了后续的剪枝和蒸馏,我们首先需要一个初始模型。本项目使用的分类模型为VGG16,选择该模型的原因之一是因为结构简单,确保可以剪枝成功;其次是因为VGG16参数量大,剪枝效果看起来也很明显。模型结构可以在"model.py"中看到。
执行以下脚本进行模型训练:
$ python .\train.py
模型设置30个训练的epoch,训练完成后可以在项目文件夹下看到"vgg16Net.pth"文件。该文件为训练好的分类模型权重。
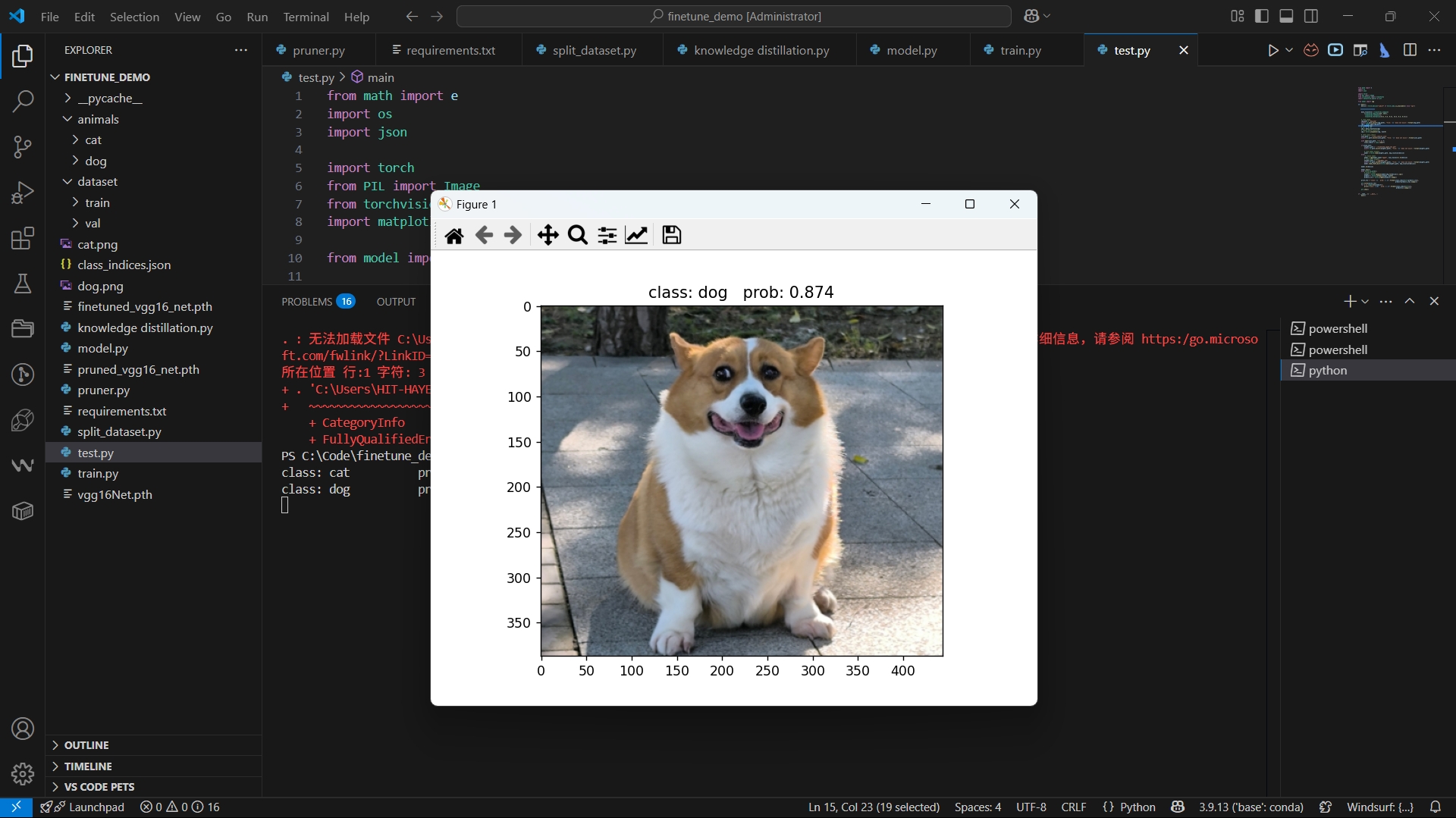
为了测试分类效果,需要确保**”test.py**"文件下的“ prune_test = False”,同时执行以下脚本既可进行分类预测:
$ python .\test.py
分类结果如下:
模型剪枝
模型剪枝(
Pruning)也叫模型稀疏化,不同于模型量化对每一个权重参数进行压缩,稀疏化方法是尝试直接“删除”部分权重参数。模型剪枝的原理是通过剔除模型中 “不重要” 的权重,使得模型减少参数量和计算量,同时尽量保证模型的精度不受影响。
模型剪枝会使用到微软的NNI库,同时会改变模型的参数结构,具体的实现细节,可以查阅"pruner.py"文件。
执行以下脚本可以完成对VGG16训练模型的剪枝:
$ python .\pruner.py
模型剪枝不需要进行训练,但是会改变训练好的权重参数结构。剪枝完成后,会生成一个权重文件"pruned_vgg16_net.pth",该权重文件的大小约为"vgg16Net.pth"的五分之一。
由此可见,剪枝会显著减小模型的结构。不过,剪枝有副作用,会显著地降低模型的预测精度,为了恢复精度,我们还需要对剪枝后的模型进行”知识蒸馏“。
知识蒸馏
知识蒸馏(Knowledge Distillation)作为一种有效的模型压缩和加速技术,应运而生。它通过将一个复杂的大模型(称为教师模型,Teacher Model)的知识转移到一个较小的模型(称为学生模型,Student Model)中,使得学生模型在保持较小规模的同时,能够尽可能地接近教师模型的性能。
简单来说,知识蒸馏就像是一场 “学习传承” 的过程。教师模型就如同一位知识渊博、经验丰富的老师,经过大量数据的训练,掌握了复杂的数据模式和特征知识。而学生模型则是一位努力学习的学生,它的结构相对简单,计算成本较低,但渴望从教师模型那里获取知识,提升自己的能力。在这个过程中,教师模型将自己学到的知识以一种特殊的方式传授给学生模型,让学生模型能够在资源受限的情况下,也能表现出良好的性能。
在本项目中,教师模型为最初训练得到的"vgg16Net.pth",学生模型为剪枝后的"pruned_vgg16_net.pth",我们需要让学生模型学习教师模型的能力,从而提升学生模型的检测精度。
执行以下脚本,对教师模型进行”知识蒸馏“:
$ python .\knowledge distillation.py
知识蒸馏需要对模型进行fine_tune训练,这里设置20个训练的epoch,训练完成后可以在项目文件夹下看到"finetuned_vgg16_net.pth"文件。该文件为蒸馏好的分类模型权重,该权重的模型大小和剪枝后的模型大小保持一致。
蒸馏结果测试
为了测试蒸馏效果,需要确保"test.py"文件下的“ prune_test = True”,同时执行以下脚本既可进行分类预测:
$ python .\test.py
分类结果如下:
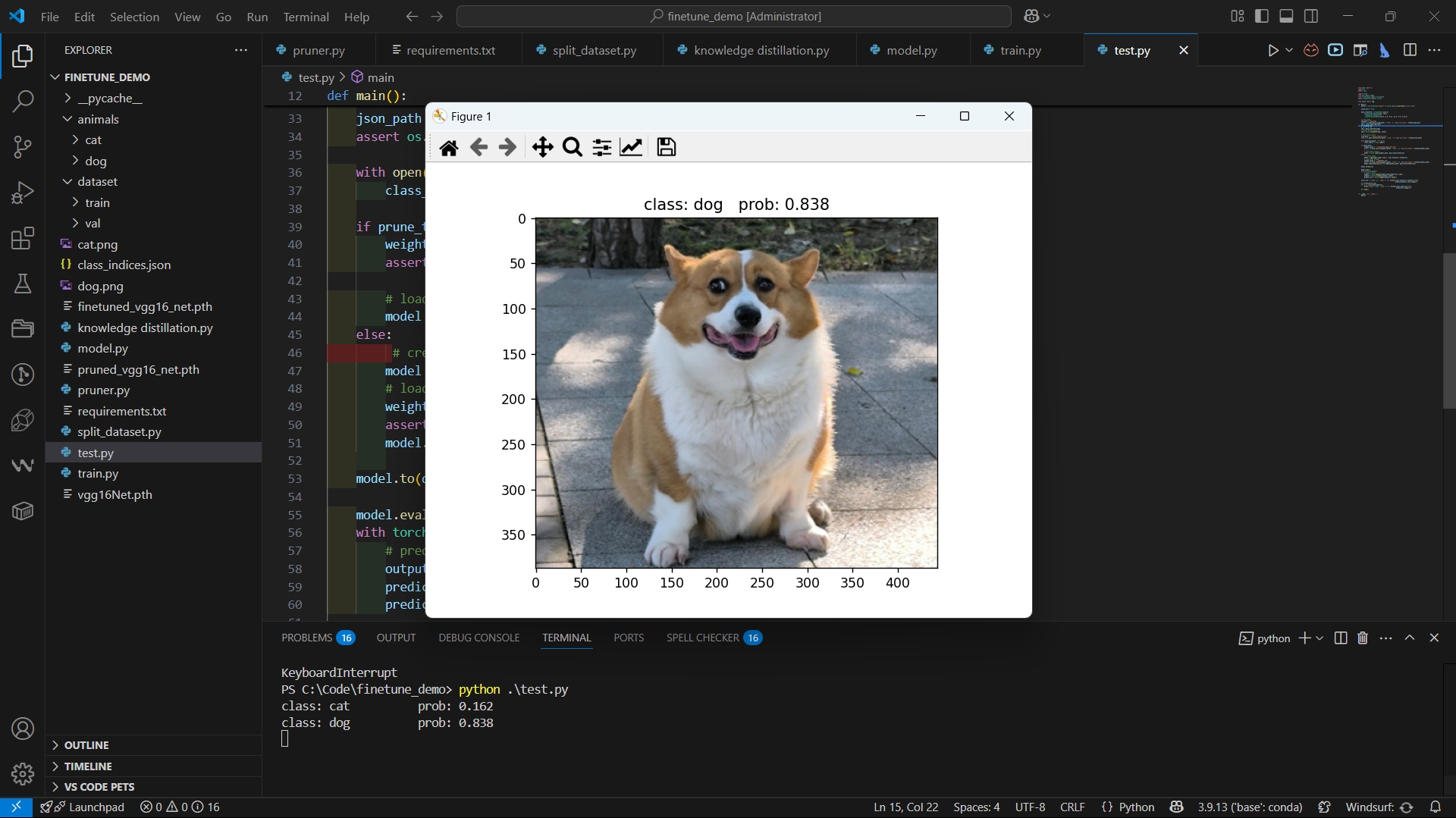
从结果来看,精度相比最原始的模型,有略微下降,但是模型的大小变成了原始模型的约五分之一。
由此说明,模型剪枝+知识蒸馏可以在稍微牺牲精度的情况下,显著减小模型的复杂度。
写在后面
创作不易,如果觉得这个仓库还可以的话,麻烦给一个star,这就是对我最大的鼓励。
Reference
-deep-learning-for-image-processing
-nni






