大家读完觉得有帮助记得关注和点赞!!!
抽象
深度神经网络 (DNN) 容易受到后门攻击,攻击者在训练期间植入隐藏的触发器,以恶意控制模型行为。 拓扑进化动力学 (TED) 最近成为检测 DNN 中后门攻击的强大工具。但是, TED 可能容易受到后门攻击,这些攻击会自适应地扭曲跨网络层的拓扑表示分布。 为了解决这一限制,我们提出了 TED-LaST(拓扑进化动力学针对洛杉矶未干燥,Slow release 和Target mapping 攻击策略),这是一种新颖的防御策略,可增强 TED 对自适应攻击的鲁棒性。TED-LaST 引入了两项关键创新:标签监督动态跟踪和自适应层强调。这些增强功能能够识别逃避传统基于 TED 的防御的隐蔽威胁,即使在拓扑空间不可分离和微妙的拓扑扰动的情况下也是如此。 我们对最先进的自适应攻击中的数据中毒技巧进行了审查和分类,并提出了带有目标映射的增强自适应攻击,它可以动态转移恶意任务并充分利用自适应攻击所具有的隐蔽性。 我们对多个数据集(CIFAR-10、GTSRB 和 ImageNet100)和模型架构(ResNet20、ResNet101)的综合实验表明,TED-LaST 有效地抵消了复杂的后门,如 Adap-Blend、Adapt-Patch 和拟议的增强型自适应攻击。 TED-LaST 为强大的后门检测设定了新的基准,大大增强了 DNN 安全性,以抵御不断演变的威胁。
索引术语:
后门攻击、后门检测、防御机制、深度神经网络。第一介绍
深度神经网络 (DNN) 模型彻底改变了计算机视觉等领域[1]语音识别[2]和自动驾驶[3]凭借其令人印象深刻的能力。尽管取得了这些进步,但它们对扩展数据集和复杂训练程序的依赖带来了重大漏洞,特别是通过后门攻击。后门攻击在 DNN 模型中植入隐藏的行为,这些行为可以由特定触发器激活。值得注意的是,这些后门不会影响模型在干净数据上的性能,这使得它们特别隐蔽和具有破坏性。
在分类任务中,这些攻击通常涉及毒害训练数据集,其中只有一小部分训练数据是使用攻击者指定的触发器纵的。一旦模型了解到这些触发器,它就会将它们与攻击者定义的特定类相关联。 后门攻击的发展已经有了很大的发展,BadNets 的开创性工作证明了这一点[4]以及随后的发展[5,6,7,8,9,10,11,12,13,14,15,16,17,18,19],它们在数据中毒时间和策略的复杂性上有所不同。
鉴于后门攻击的隐蔽性和潜在危害,开发强大的后门检测方法变得至关重要。 后门防御通常根据其分析目标分为三大类:模型级[20]、标签级[21,22,23,24]和样本级[25,26,10,27,28].其中,样本级防御通过将单个恶意样本识别为异常来提供最精细的检测。这些防御方法之所以有效,特别是由于关键的观察结果:后门模型通常会在潜在空间内学习到过强的触发器信号[29],掩盖了其他语义特征,并有助于将中毒样本与干净样本明确分离。
但是,恶意输入和正常输入之间的可区分性本身并不能得到保证。当恶意输入表示与潜在空间中正常输入的可分离性被故意抑制时,防御可能会失败[29].现有后门检测方法的这一漏洞促使攻击者通过修改训练过程来设计自适应攻击[30,31]或实施一袋数据中毒技巧[28,10].此外,由于数据中毒的多功能性和更广泛的适用性,其潜在危害要大得多。 这个包里最常用的一些技巧包括 Laundry [29,10,9,28,17,32],其中包含触发的样本,但具有正确的标记,Slow Release [33,34],它在训练期间使用触发器的一部分,同时在推理过程中保持其完整,以及 Target Mapping,它包含一个共享触发器,但针对不同的类别[35,34]. 值得注意的是,对于自适应攻击,这些数据中毒技巧与数据无关:相同的技巧可以应用于各种类型的中毒数据,并且可以在一个数据中毒攻击中组合多个技巧。
随着后门攻击的适应性越来越强,防御者正在不断增强其检测能力。例如,为了对抗特定的单一技巧,已经专门为 Laundry 开发了防御方法[10,28]和 Slow Release[36].其中,我们之前的研究证明了使用拓扑进化动力学 (TED) 在输入级别检测 Laundry 后门攻击的有效性[28].TED 分析了输入样本在网络中传播时拓扑表示的演变,利用了中毒样本和干净样本在拓扑空间中通常表现出不同的进化行为的观察结果。
当面对组合技巧时,例如在一次中毒攻击中结合使用 Laundry 和 Slow Release,这会导致恶意样本和干净样本在度量空间中的潜在不可分割性[26,36,10,27]或在拓扑空间中。 在仔细研究这个可分性问题后,我们观察到 TED 使用的全局拓扑特征无法提供足够的清晰度。此外,对于在多个层中传播的恶意样本,所有层的相同权重变得无效,这些样本具有类似于干净样本的细微扰动。 基于这些观察,我们提出了两个关键见解: (1) 与目标类本身的样本相比,恶意样本通常从其原始类到目标类的遍历轨迹更长。特征空间中的这种扩展轨迹可能为检测提供一个显著的特征。(2) 并非所有图层都是相等的。恶意样本和干净样本之间的拓扑表示差异可能因层而异。因此,我们需要在异常值检测过程中动态识别关键层,并为不同的层分配不同的权重。 这些见解促使我们开发一种更精细、更强大的方法来检测拓扑空间中的自适应攻击样本甚至细微扰动样本。
作为回应,我们提出了 TED-LaST(拓扑进化动力学洛杉矶未干燥,Slow Release 和Target Mapping 攻击策略),一种基于拓扑的新型后门检测器,扩展了我们之前的工作[28]实现抵御适应性攻击的稳健性。TED-LaST 利用监督标签信息和基于模块化的自适应层强调来提高检测稳健性,并在极端情况下检测具有细微扰动的恶意样本,即使良性和恶意样本之间的拓扑可分离性受到严重损害。 我们的主要贡献可以总结如下:
- •
本研究仔细回顾和分类了 SOTA 自适应后门攻击(第 II 节)中的数据中毒技巧,揭示了现有后门检测器的缺点,这些检测器旨在分离度量空间(第 II 部分)或拓扑空间(第 III 部分)中的良性和恶意样本。我们表明,自适应攻击和我们提出的增强型自适应攻击可以通过掩盖样本特征来使 SOTA 检测器失效。
- •
本研究提出了 TED-LaST,它通过量化恶意样本扰动来解决拓扑空间中恶意样本和良性样本之间的不可分割性,并优先考虑信息拓扑特征以解决对细微扰动的不敏感问题,从而显着增强了基于拓扑的后门检测器对自适应攻击的鲁棒性(第 IV 节)。
- •
本研究在各种场景中广泛验证了 TED-LaST,证明它对所有 SOTA 自适应攻击和增强型自适应攻击的准确率高于 90%,F1 分数高于 85%(第 IV 节)。我们的结果一致表明,TED-LaST 的性能优于 SOTA 防御。
第二深度神经网络中的后门
DNN 模型,表示为f,由一系列层组成{fl:l∈[1,N]},其中每个层都用作一个转换。对于输入x,神经网络的输出f由组合计算:

遵循以前的研究[4,31,26,9,10,28,29],本文重点介绍应用于分类任务的 DNN 模型。 具体来说,我们解决了一个分类问题,其中输入空间表示为𝒳将所有类的集合设置为𝒴.每个 ground-truth input-output 对(x,y)是一个样本,其中x∈𝒳和y∈𝒴. 训练数据集,表示为𝒟={(x我,y我)},由数据点组成(x我,y我)和模型f∗经过训练以最小化损失函数L(⋅,⋅)多𝒟如:

II-A 型后门攻击
后门攻击将恶意功能嵌入到神经网络中,仅对携带触发器的输入造成异常行为。虽然有些攻击会直接修改模型参数[37]或模型结构[38],最常见的方法涉及脏标签数据中毒。这通常涉及将触发器嵌入到源标签中的训练样本子集中,并将其标签更改为目标标签。工作[4]首先演示了这项技术,表明用小的固定图案(例如,白色方块)标记图像可以成功创建后门。 这些改变的样本,表示为一个(x)对于原始输入x标记有攻击者选择的目标类c目标、创建中毒数据集𝒟p={(一个(x),c目标)∣(x,y)∈𝒟}哪里𝒟是原始的干净数据集。在组合数据集上训练时𝒟∪𝒟p、模型f学习对触发样本进行分类一个(x)作为目标c目标同时在清洁样品上仍保持高精度𝒟 [4,11,6,12].
增加后门攻击隐蔽性的一种常见方法是修改训练过程本身,此外,还可以通过在样本中嵌入触发器来毒害数据。 示例包括使用生成网络创建动态触发器[14,15],并合并专门的损失函数[31]. 然而,攻击者也在寻求简单而有效的方法,即使在只能在不改变训练过程的情况下修改样本和相关标签的约束下,也能有效地规避防御。
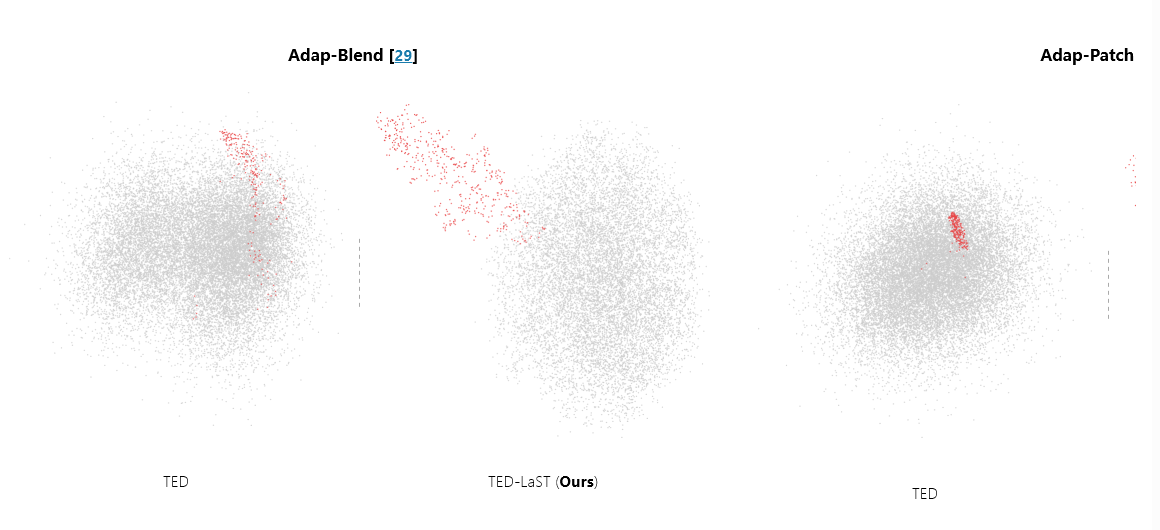
图 1:在 Adap-Blend(左)和 Adap-Patch(右)攻击下,后门 CIFAR-10 模型上 TED 和 TED-LaST 的样本特征向量可分离性的 T-SNE 可视化。对于每次攻击,左侧子图显示 TED 的结果,而右侧子图显示 TED-LaST 的结果。红点表示恶意样本,灰点表示干净的样本。这些图表明,与 TED 相比,TED-LaST 实现了恶意样本和干净样本之间的分离。
II-B 型用于自适应攻击的数据中毒技巧袋
II-B1洗衣店
洗衣店,首先学习[10]是一种技巧,它将训练样本与触发器相结合,同时保留其正确的标签,从而允许攻击逃避防御[32,28].这种方法可以防止后门模型为触发器学习一个压倒性的强信号(在防御中更容易检测到),该信号总是会导致目标类[29]. 在训练期间,使用两种类型的触发样本:1) 将触发器标记为目标类的中毒样本c目标,以及 2) 具有保持其原始标签的触发器的样本。这个技巧可以表述为:
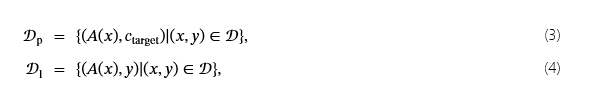
哪里𝒟p表示中毒数据集,𝒟l表示 Laundry 数据集。这两个数据集共同构成了模型的训练集。
II-B2 号缓释
Slow Release,首次研究于[33]是一种技巧,它在训练期间将训练样本与部分触发器相结合,同时在推理期间使用完整触发器来激活后门[33,34].这种方法逐渐引入了后门,削弱了模型学习的触发器的强信号。训练期间的各种部分触发器会阻止模型在触发器和目标类之间突然创建易于检测的相关性[36].
例如,在训练期间,仅应用触发模式的一部分(例如,仅使用四个补丁触发器中的两个补丁),而在推理/攻击阶段恢复完整的触发模式。更正式地说,在训练期间,我们使用一组参数ℛt(完整参数空间的子集ℛ) 控制触发器强度或几何属性βt,而在推理过程中,我们使用 Map 函数g(βt)将 training-phase 参数转换为其全强度推理参数。中毒的数据集可以表述为:
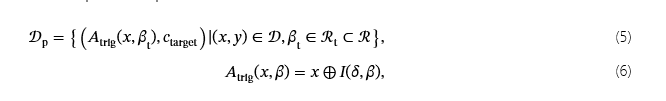
哪里一个三角是将 trigger 与 input sample 相结合的 trigger application 函数,我(δ,β)是生成触发模式的函数δ基于参数β,它控制触发器的强度(例如不透明度)或几何属性(例如大小、间隙、位置)。
表 I:后门攻击表示法。
| 术语 | 描述 |
|---|---|
| T(⋅) | Target Mapping 功能 |
| 一个(x) | 创建新样本的函数x |
| 一个三角(x,β) | 功能修改x扳机控制β |
| 一个三角(x) | 为特定于源的目标映射应用触发器的函数 |
| c目标 | 攻击者选择的目标类 |
| 𝒟p,𝒟l | Backdoor 中毒和 Laundry 数据集 |
| 我(δ,β) | 函数调制触发器δ跟β |
| ℛ | trigger 属性参数集,β∈ℛ |
| ℛt | 的子集ℛ用于慢释训练阶段 |
| g(β) | 函数将训练映射到推理时间参数 |
| 𝒮 | 源类集 |
| ⊕ | 带输入的混合触发器的作 |
II-B3 号目标映射
Target Mapping,首次研究于[34]是一种数据中毒技巧,它使用单个共享触发器创建到多个目标类的不同映射[39,35,34,31]. Target Mapping 不是创建一对一的关系(例如,一个触发器到目标类 A),而是建立一对多的后门映射(例如,一个触发器到目标类 A、B 和 C)。因此,后门的恶意行为变得取决于触发器以外的因素。虽然触发器充当一个元素,但输入数据中其他看似良性的特征(例如特定像素组合或特定范围内的值)可以指示模型激活哪个恶意任务。 目标映射函数定义为:

哪里𝒮表示源类的集合。 对于仅关注源类(称为源特定 (SS) 目标映射)的方案,中毒数据集为:
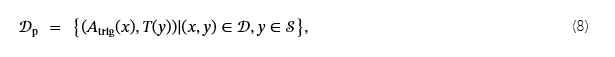
哪里一个三角(x)=x⊕δ.SS 统一应用触发器,而不区分触发器属性β. 与SS不同,源特定和触发属性(SS&TA)目标映射同时考虑了源类和触发器属性:
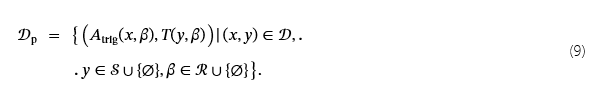
II-B4 号组合技巧
随着后门检测方法的进步,单招攻击越来越容易受到检测。作为回应,攻击者开发了更具适应性的攻击,例如 Adap-Blend 和 Adap-Patch,它们结合了 Laundry 和 Slow Release[29]. Adap-Blend 攻击使用分区的低不透明度触发器进行训练,使用完整的、高不透明度的触发器进行攻击。Adap-Patch 攻击利用多个小型不同的补丁作为触发器,在攻击过程中采用完全不透明的补丁组合。 为了实现 Laundry,Adap-Blend 和 Adap-Patch 都会在训练期间将触发器注入到一部分干净的样本中,同时保持其真实标签不变。这种自适应攻击不仅逃避了依赖于度量空间中潜在特征可分离性的 SOTA 检测方法,而且还规避了利用拓扑空间中特征可分离性的 TED,如图 1 所示。1.
II-B5 号增强型自适应攻击
在这些高级组合的基础上,我们建议进一步将 bag 中更多与数据无关的技巧集成到自适应攻击框架中。特别是,受 Target Mapping 攻击入侵的模型可以根据攻击者选择的后门特征在多个恶意任务之间交替。重要的是,即使攻击具有共同的触发模式,这种任务切换功能仍然存在[9,34,35,31],这意味着相同的触发器不再始终导致静态的恶意结果。
与使用静态目标类实现的 Adap-Blend 和 Adap-Patch 不同,我们引入了增强型自适应攻击,它结合了洗衣 (L)、缓释 (SR) 和目标映射(SS 或 SS&TA)来创建动态目标自适应攻击。关键思想是根据方程 (6) 修改触发器,从而扩展中毒数据集𝒟p(如方程 (9) 中所定义)和 Laundry 数据集𝒟l(如方程 (4) 中所定义)。具体来说,为了使用 SS&TA+L+SR 攻击对模型进行后门作,我们通过最小化由三个部分组成的损失函数来训练模型:清理损失 (Lc)、洗衣损失 (Ll) 和中毒损失 (Lp).基于方程 (2),我们的完全损失函数为:
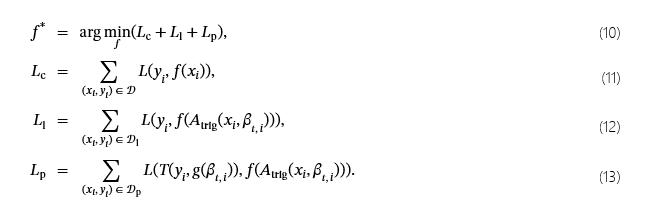
附录 A 中详细介绍了增强型自适应攻击的其他配置,包括 SS+L+SR。
II-C 型针对自适应攻击的现有防御措施
后门防御通常根据其分析目标分为三大类:模型级、标签级和样本级。 模型级防御侧重于分析模型本身。例如,可以在一组干净的模型和带木马的模型上训练元分类器,以识别受损的模型[20]. 标签级防御旨在对潜在触发因素进行逆向工程并移除插入的后门[21,22,24],或分析学习表示中的异常[23,40].然而,对于模型和标签级防御,了解模型为何被标记为受损可能特别具有挑战性,尤其是在巧妙改变模型行为的自适应攻击下。相比之下,样本级防御提供了一种更精细的方法。
样本级防御分析输入数据表示和模型行为。例如,SCAn[10]使用稳健的统计数据来分析跨类的表示分布,并采用双分量模型来理清类的标识和变化。带[26]通过将输入图像叠加在随机样本上并分析输出标签中的熵变化来检测触发器。TeCo 公司[27]评估模型的损坏稳健性,识别各种图像损坏下触发样本的不同模式,并随着损坏严重程度的增加量化模型响应的一致性。
尽管如此,这些样本级防御并非不受适应性攻击的影响。具体来说,自适应攻击可以通过抑制干净和中毒表示之间的潜在分离来降低 SCAan 的有效性。虽然 STRIP 对标准攻击有效,但自适应技术可以纵触发输入的熵分布,从而模糊它们与良性数据的区别。此外,适应性攻击可以通过设计跨腐败级别的一致行为来规避 TeCo。针对各种自适应攻击的样本级防御的详细结果可以在我们在第 V 节的实验分析中找到。
第三原始 TED 遭遇自适应攻击:案例研究
拓扑进化动力学 (TED) 利用拓扑空间中神经网络激活的演变来对恶意样本进行离群。TED 特征向量是一种度量,用于捕获样本的激活值如何与整个网络中的预测类别保持一致。 具体来说,TED 特征向量通过跟踪样本在激活拓扑空间中的相对位置来量化样本特征表示在不同层中的演变。 在每一层,它对样本的激活与其预测类别的激活的接近程度进行排名。通过跨层跟踪这些排名,TED 通过网络映射每个样本的进化路径。
TED 采用拓扑方法来对特征空间进行建模,关注相对接近度,而不仅仅是矢量距离。这涉及定义度量空间(𝒱,d)哪里𝒱是一组向量或矩阵,而d是一个度量函数,映射𝒱设置为非负实数。每个输入x在图层处l表示为hl(x)=v∈𝒱(l).在这个空间中,一个以v带半径r,表示为ℬ(v,r),包括所有点v′为了d(v,v′)<r.这些开放的球形成基于邻域接近度的拓扑。 对于良性样本xu带标签yu在图层上l,则存在另一个样本x′, 也标记了yu, 在最小半径内rl使得hl(x′)属于ℬ(vu(l),rl).此最小半径rl(默认为 1)捕获样本周围的局部邻域结构xu在图层处l.这个假设意味着同一类的良性样本在一定范围内将表现出相似的激活模式。
对于每个输入样本,TED 根据其与来自同一预测类的其他样本的接近程度,在每个网络层生成一个排名列表。输入的 TED 特征向量x定义为:
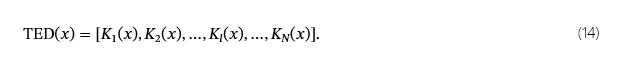
此序列捕获x的拓扑演变N网络层。这里Kl(x)表示x的 layer 中预测类的最近邻l,通常使用欧几里得距离计算。此顺序数据揭示了x始终与其职业的典型激活模式一致或发散,可能表示异常。然后,在来自所有类别的良性样本的 TED 特征向量上训练异常值检测器。此检测器将 TED 轨迹明显不同的输入标记为潜在的异常值(恶意)。
III-A 系列TED 的局限性
III-A1 号拓扑空间异常值检测中的不可分离性
没有自适应方法的传统攻击通常会产生恶意数据,这些数据与拓扑空间中的干净数据表现出截然不同的特征。因此,TED 假设与来自所有类别的干净数据相比,恶意数据在拓扑演变方面具有显着差异,并通过异常值检测来识别恶意数据。
但是,这种假设在对抗适应性攻击时变得不那么可靠。这种自适应攻击纵特征空间并在学习表示的拓扑空间中诱导不可分离性,如图 2 所示。1. 这种诱导的不可分离性破坏了 TED 区分良性和恶意样本的能力。
核心漏洞在于 TED 对其异常值检测器的训练程序。通过在训练期间使用来自所有类的良性样本,检测器学习了更广泛的 ?正常?行为,包含所有类的变化。因此,自适应攻击可以制作属于这个更广泛的可接受正常变体范围内的恶意样本,同时仍能实现其恶意目标。
此类漏洞特别容易受到自适应攻击的利用,因为自适应攻击者可以构建足够接近任何类(不一定是目标类)的恶意样本,以逃避检测,从而使 TED 失效。在异常值检测器训练期间平等地考虑所有类别这一基本限制强调了需要更有针对性的方法。
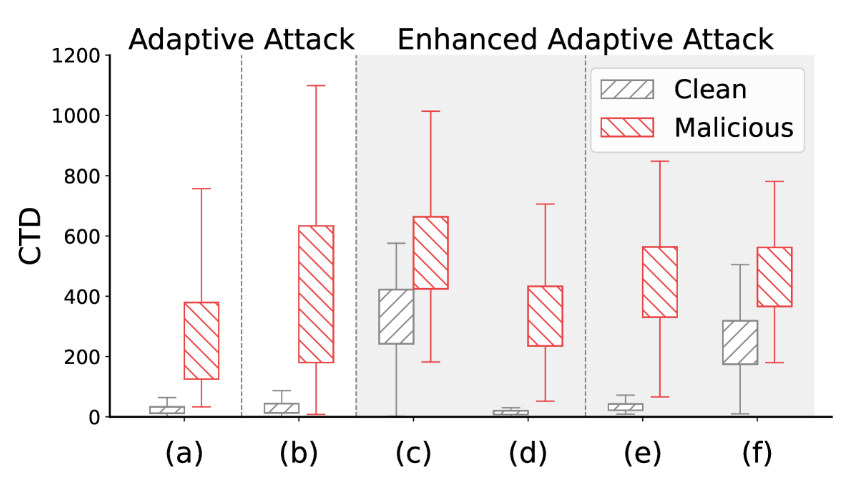
图 2:CIFAR-10 上的累积拓扑距离 (CTD) 或不同的攻击场景。(a) Adap-Blend,(b) Adap-Patch,(c) SS+L+SR 目标类 A,(d) SS+L+SR 目标类 B,(e) SS&TA+L+SR 目标类 A,(f) SS&TA+L+SR 目标类 B。场景 (a) 和 (b) 代表适应性攻击,而 (c)-(f) 代表增强型自适应攻击。
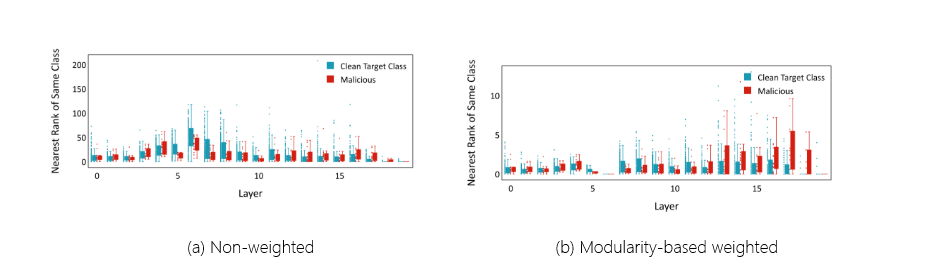
图 3:(a) Adap-Patch 下 ResNet20 上拓扑特征向量的箱形图。该图揭示了具有微妙扰动的 CIFAR-10 恶意样本,这些扰动对于类级 TED 来说太小了,无法有效地识别为异常。(b) 应用基于模块化的自适应层加权后的箱形图,显示干净样本和恶意样本之间的分离得到改善。
III-A2 号对细微的扰动不敏感
在自适应攻击中,恶意样本密切模拟目标类的拓扑演变,有效地 ?影子?通过跨多个层保持与目标类邻居的最小距离来合法样本的轨迹。因此,TED 的特征向量在区分这些样本时表现出有限的分辨率。 核心挑战在于 TED 的灵敏度不足,无法检测到与真实阶级轨迹的细微但持续的偏差。虽然 TED 有效地识别了显著的拓扑偏移,但它很难标记在各层拓扑空间中仅表现出轻微偏移的样本。此限制可能导致 TED 特征向量落在目标类的误差范围内的示例错误分类。
这种漏洞特别容易受到适应性攻击的利用,适应性攻击可以通过最大限度地减少扰动并针对 TED 敏感度较低的层,设计恶意样本,使其在网络层中始终保持在 TED 的检测范围内。
III-B 型对 TED 的见解和建议的增强功能
III-B1 号标签监督动态跟踪
关键的见解是,与目标类本身中的良性样本相比,源自不同源类的恶意样本遍历的拓扑距离更大。为了根据经验量化遍历距离的这种差异,我们引入了累积拓扑距离 (CTD) 指标:
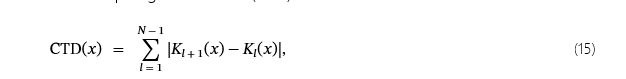
哪里𝒳表示所有样本的集合。这里N是网络层的总数,而Kl(x)表示样本的排名x在图层处l. 如图 1 所示。2,与在所有攻击的目标类别中预测的干净样本相比,恶意样本始终表现出更高的 CTD 值。这种观察到的遍历距离的差异表明,纵样本的拓扑特征可能存在差异,这促使我们采用标签监督动力学跟踪方法来检测它们。
然后,我们从全局视角转向特定类的视角。我们假设防御者可以访问一小组具有正确标签的干净样本。 具体来说,我们的方法采用特定于类的基于 PCA 的异常值检测模型。 该模型使用 reject 参数计算特定于类的阈值α.设置此阈值是为了保留(1−α)该特定类别的良性样本分布中由主成分解释的方差的百分比。超过此阈值的样本将被标记为潜在异常值。 利用这些标签信息,我们可以精细地了解每个类中的预期数据模式。这使我们能够检测出偏差,否则这些偏差会被自适应攻击引起的全局拓扑模糊所掩盖。通过关注每个类的独特特征,我们可以识别恶意样本,即使它们与全局拓扑空间中的目标类无缝混合。
III-B2 号自适应图层强调
虽然结合标签监督动力学跟踪缓解了原始 TED 的全局不可分性问题,但检测与拓扑空间中的目标类别非常相似的恶意样本仍然具有挑战性,尤其是对于具有细微扰动的样本。这些细微的扰动会导致恶意样本的 CTD 值较低,这表明跨网络层遍历的拓扑距离较小。因此,它们的特征表示与目标类中良性样本的特征表示更加相似,从而使其更难检测为异常值。实证观察表明,恶意样本的排名分布,特别是那些 CTD 值在其分布的下四分位数的样本,与 TED 中大多数层的目标类别中良性样本的排名分布显示出相当大的交集(图 D)。3a)。
以前的研究表明,为关键层(通常是最后几层)分配更大的权重可以改进后门恶意检测[41,42].但是,仅更改层数并不能有效地提高 TED 性能[28].因此,除了识别网络端的关键层外,我们还必须考虑来自前层和中间层的干净样品的固有可变性。为了解决这个问题,我们提出了一种方法来动态识别和强调整个网络中的关键层。
我们采用模块化概念,因为它在量化集群分离方面很有效[43].我们提出的基于模块化的方法量化了每层特征空间的可变性,并相应地自适应地调整了不同层的权重。 具体来说,模块化量化了网络可以划分为不同社区或集群的程度[44].我们将这个概念应用于特征空间,将数据点视为节点,将它们的相似性视为边缘权重。模块化分数的计算方法是将集群内的连接密度与连接随机分布时的预期密度进行比较。较高的模块化分数表示类之间的分离越明显,这意味着存在定义明确的集群。
在我们的方法中,具有较低可变性级别(较高模块化度)的层在特征向量的最终计算中被赋予了更大的权重,从而强调了它们对整个检测过程的贡献。相反,具有较高可变性级别(较低模块化度)的层被分配较小的权重,从而减少它们的贡献。通过选择性地强调具有不同类区别的层,如图 1 所示。3b,我们增强了该方法对自适应攻击引入的细微差异的弹性。除了解决静态目标自适应攻击外,我们还在附录 B 中提供了可视化,比较了动态目标增强自适应攻击下的非加权和基于模块化的加权方法。
四国防设计
在本节中,我们将详细介绍我们的方法 到检测后门攻击。TED-LaST 的框架如图 2 所示。4
IV-A 型国防设计
Ol(x)表示 layer 的输出l用于输入x和Kl(x)的等级为x的 layer 中预测类的最近邻l.对于权重计算,我们首先考虑所有可能的类别。对于每个类c∈𝒴和每一层l∈{1,…,N},我们计算权重wl,c使用第 IV-B 节中描述的方法之一。
接下来,给定一个示例x及其预测的类y^中,我们计算 TED-LaST 的自适应特征向量泰德∗(x),基于原始 TED 特征向量(方程 (14)):
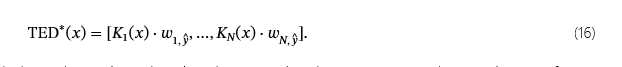
对于每个类c∈𝒴,我们训练一个专用的基于 PCA 的异常值检测器。该检测器使用一组 TED* 特征进行训练,该特征集根据预测为 Class 的训练数据子集计算得出c:{泰德∗(x)∣x∈𝒳,和预测的类x是c}.检测器使用到所选特征向量的加权欧几里得距离之和作为异常的度量[45].对于示例x,我们计算异常分数s(x)作为样本(投影到 PCA 空间上)与 PCA 模型对应于其预测类别的每个特征向量之间的加权欧几里得距离之和y^.阈值τc设置为α- 预测为 class 的训练样本集中的异常分数的分位数c.
在推理阶段,对于新样本x使用预测类y^,我们首先计算泰德∗(x).然后我们计算异常分数s(x)使用基于 PCA 的异常值检测器y^.如果样本的分数超过相应的阈值,则将其归类为异常τy^.算法 1 提供了基于模块化的 TED-LaST 流程的详细信息。
IV-B 型重量计算
我们首先构造一个图𝒢l对于每个图层l在层的激活中使用 k 最近邻 (KNN){Ol(x)∣x∈𝒳},并且相邻节点数设置为|𝒳|.然后我们分配标签Cc(x)=0如果y^=c,否则为 1。 对于每个图层l和类c∈𝒴,我们计算模块化Ql,c上𝒢l用Cc(x):

哪里nc是社区数(在本例中为 2),m是 中的边总数𝒢l,E我是社区中的边数我,k我是社区中节点度数的总和我和γ是 resolution 参数(默认值为 1)。 然后,我们标准化每个类的所有层的权重:

哪里Q分钟,c和Q麦克斯,c是类的所有层的最小和最大模数值c.
12 输入:样本集𝒳使用预测标签y^对于每个x∈𝒳、类集𝒴、分位数α对于 Threshold(阈值),表示层总数N、层的输出l用于输入x如Ol(x)/* 预处理 */3 为 每一层l∈{1,…,N} 做4 构造图𝒢l使用 KNN (k=|𝒳|) 打开{Ol(x)∣x∈𝒳}5 计算Kl(x): 等级x的 layer 中预测类的最近邻l/* 训练阶段 */6 为 每个类c∈𝒴 做7 分配标签:Cc(x)={0如果y^=c1否则8 为 每一层l∈1,…,N 做9 计算模块化Ql,c上𝒢l用Cc(x)根据方程 ( 17)1011 标准化权重:wl,c=Ql,c−Q分钟,cQ麦克斯,c−Q分钟,c为了所有人l12 计算泰德∗(x)=[K1(x)⋅w1,c,…,KN(x)⋅wN,c]13 为 class 训练基于 PCA 的异常值检测器c上{泰德∗(x)∣x∈𝒳,y^=c}14 设置阈值τc作为α-quantile 的{s(x)∣x∈𝒳,y^=c}15/* 推理阶段 */16 功能 检测(x,y^) :17 计算泰德∗(x)=[K1(x)⋅w1,y^,…,KN(x)⋅wN,y^]计算异常分数s(x)使用基于 PCA 的异常值检测器进行类y^18 返回 s(x)>τy^?异常 : 正常19算法 1 基于模块化的 TED-LaST
IV-C 型样本级后门检测的评估指标
在我们的评估中,我们主要采用两个常见的指标作为我们以前的工作[28]:精度和 F1 分数。对于防御者来说,恶意数据被认为是积极的,而干净的数据被认为是消极的。 精度衡量正确识别的恶意输入在标记为恶意的所有输入中的比例。此指标反映了检测系统的准确性,尤其是其减少误报的能力。 F1 分数通过结合精度和真阳性率 (TPR,也称为召回率) 来提供模型性能的平衡度量。
为了确定检测阈值,我们分析了每个类的正常输入的排名序列。特定于类的阈值τ我使用 reject 参数确定α通过对正常输入样本进行基于 PCA 的异常值检测。我们设置α=0.05实现 5% 的假阳性率 (FPR),这意味着在主成分上投影最偏差的 5% 样本被标记为潜在异常值。这个 FPR 水平在实际应用中被认为是可以接受的。 此外,为了在不同的 FPR 阈值上提供更完整的性能评估,我们将 AUROC 作为消融研究的补充指标。
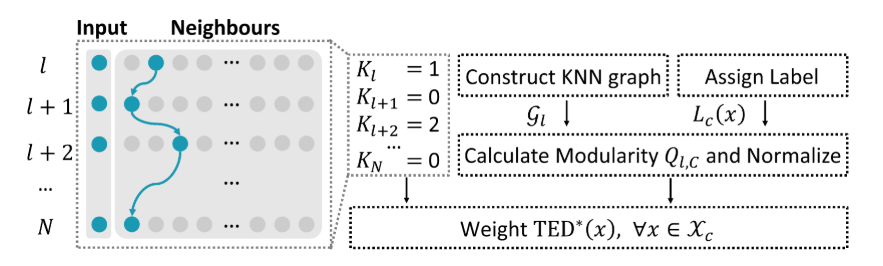
图 4:TED-LaST 自适应特征向量计算结构概述。
V实验
在本节中,我们将对各种自适应攻击场景进行实验,包括我们提出的增强型自适应攻击。附录 C 中介绍了 TED-LaST 针对另外两种非自适应后门攻击的结果。 遵循与我们之前工作相同的设置[28],TED-LaST 使用 CIFAR-10 和 GTSRB 数据集中每个类的 200 个干净样本,并利用 Conv2D 和 Linear 层的所有输出。为了实现,我们使用开源 Python 异常值检测 (PyOD) 库[45].
V-A抵御自适应攻击的稳健性
为了评估 TED-LaST 对自适应攻击的抵抗力,我们遵循[29],在 Adap-Blend 和 Adap-Patch 场景下在 CIFAR-10 和 GTSRB 数据集上训练 ResNet-20 模型。我们的评估使用来自每个数据集的 1000 个中毒样本和 1000 个干净样本。如表 II 和表 III 所示,TED-LaST 保持了强大的检测能力和精度≥94.0% 和 F1 分数≥所有配置为 92.9%。与 TED 相比,TED-LaST 表现出卓越的性能,CIFAR-10 上的 Adap-Blend 攻击的 F1 分数高出 35%,GTSRB 上的 Adap-Patch 攻击的 F1 分数高出 63%。
表 II:针对 CIFAR-10 上 Adap-Blend 和 Adap-Patch 攻击的不同防御措施的检测比较(精度和 F1 分数,以 % 为单位)。
| 带 | 扫描 | TeCo 公司 | 泰德 | TED-LaST 系列 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | |
| Adap-混合 | 47.4 | 8.2 | 0 | 零 | 90.8 | 64.6 | 87.6 | 69.4 | 94.0 | 93.7 |
| Adap-补丁 | 16.7 | 1.9 | 0 | 零 | 22.1 | 2.5 | 91.4 | 79.3 | 94.8 | 92.9 |
表 III:针对 GTSRB 上的 Adap-Blend 和 Adap-Patch 攻击的不同防御措施的检测(精度和 F1 分数,以 % 为单位)的比较。
| 带 | 扫描 | TeCo 公司 | 泰德 | TED-LaST 系列 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | |
| Adap-混合 | 56.9 | 11.8 | 30.3 | 1.9 | 16.8 | 1.9 | 95.0 | 95.4 | 96.1 | 96.7 |
| Adap-补丁 | 42.5 | 6.8 | 88.6 | 50.8 | 50.6 | 8.9 | 92.5 | 60.1 | 96.2 | 98.0 |
V-B增强型自适应攻击评估
除了 SS+L+SR 和 SS&TA+L+SR 作为增强型自适应攻击之外,我们的目标是了解 TED-LaST 在不同自适应中毒技巧组合下的稳健性。我们研究了三种不同的触发器到目标映射场景:Basic、Source-Specific Target Mapping (SS) 和 Source-Specific&Trigger Attribute Target Mapping (SS&TA),其中 Basic 是指触发器的目标保持静态的情况,而不管源类或触发器属性如何。
V-B1 号设置
对于我们的基线攻击配置,我们实现了一个 6×输入图像右下角的 6 个方形触发器[34],中毒率为 0.01。 对于 Laundry 的实施,我们遵循以前研究的方法[28,10,29],从非受害者类别中选择训练样本,应用触发器,并使用真实标签标记它们。Laundry 样本的数量与中毒样本的数量相匹配。 对于 Slow Release 实现,由于方形触发器太小,无法进一步分区,我们遵循[29]并使用 ?Hello Kitty?trigger 大小等于 input。以后[29,33,34],触发器分为 16 个段,随机部分集成到训练样本中,其中每个中毒样本随机应用这些段的一半,而完整的触发器用于测试。 对于 Target Mapping 实施,我们遵循[34],其中为 SS 方案选择了两个源类和两个不同的目标类。对于 SS&TA 场景,为了在考虑不同触发强度的情况下平衡不同类别的 ASR,使用两种中毒率(例如 0.1 和 0.08)来中毒具有不同触发密度的单个类别(例如,方形触发器为 0.4 和 0.6,?Hello Kitty?trigger 中),根据[34]和[29]分别。这些不同的触发强度确保中毒样品分别达到其预期的目标类别。
这些后门攻击是在 CIFAR-10 和 GTSRB 数据集上训练的。CIFAR-10[46]由 60,000 个32×3210 个类的彩色图像,而 GTSRB[47]功能超过 50,000 个32×3243 个类别的交通标志图像。两个实验均采用 ResNet-20 模型[48],按照[29]. 表 IV 说明了我们提出的增强型自适应攻击(包括 SS&TA+L+SR 和 SS+L+SR)在 CIFAR-10 和 GTSRB 数据集上的性能,展示了在测试配置中足够的攻击成功率 (ASR) 和干净准确性 (Clean ACC)。
表 IV:CIFAR-10 和 GTSRB 数据集上各种自适应攻击的技巧性能。 设置:B(基本)、L(洗衣)、SR(缓释)、SS(特定于源)、TA(触发器属性)
| 设置 | 目标映射 | 洗衣店 | 缓释 | CIFAR-10 | GTSRB | ||
|---|---|---|---|---|---|---|---|
| ASR (%) | 清洁 ACC (%) | ASR (%) | 清洁 ACC (%) | ||||
| B | - | - | - | 99.8 | 86.4 | 100 | 92.9 |
| L | - | ✓ | - | 100 | 80.2 | 100 | 94.9 |
| 锶 | - | - | ✓ | 100 | 83.0 | 100 | 96.2 |
| L+SR | - | ✓ | ✓ | 69.7 | 82.6 | 100 | 97.2 |
| 不锈钢 | 不锈钢 | - | - | 97.5 | 77.9 | 100 | 95.7 |
| SS+L | 不锈钢 | ✓ | - | 99.8 | 80.7 | 100 | 100 |
| SS+SR | 不锈钢 | - | ✓ | 76.9 | 83.3 | 100 | 96.8 |
| SS+L+SR | 不锈钢 | ✓ | ✓ | 79.0 | 79.1 | 100 | 96.9 |
| SS&TA | SS&TA | - | - | 100 | 81.0 | 100 | 95.7 |
| SS&TA+L | SS&TA | ✓ | - | 100 | 80.3 | 100 | 100 |
| SS&TA+SR | SS&TA | - | ✓ | 78.3 | 83.2 | 100 | 97.7 |
| SS&TA+L+SR | SS&TA | ✓ | ✓ | 84.1 | 78.8 | 100 | 99.8 |
表 V:使用 ResNet-20 在 CIFAR-10 上对攻击的不同防御的性能(精度和 F1 分数,以 % 为单位)基本目标映射。 设置:B(基本)、L(洗衣)、SR(缓释)
| 设置 | 带 | 扫描 | TeCo 公司 | 泰德 | TED-LaST 系列 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | |
| B | 95.3 | 97.3 | 94.1 | 86.5 | 74.5 | 29.1 | 94.8 | 93.1 | 96.7 | 98.0 |
| L | 63.6 | 7.9 | 91.0 | 64.8 | 87.1 | 47.9 | 94.1 | 88.2 | 92.7 | 90.3 |
| 锶 | 20.0 | 3.0 | 89.3 | 58.2 | 16.7 | 1.9 | 96.3 | 97.4 | 98.9 | 99.5 |
| L+SR | 50.9 | 10.4 | 91.0 | 64.8 | 70.3 | 20.6 | 93.0 | 92.2 | 96.1 | 97.8 |
表 VI:使用 ResNet-20 在 CIFAR-10 上使用 SS(源特定)目标映射对攻击进行不同防御的性能(精度和 F1 分数,以 % 为单位)。 设置: SS(特定于来源)、L(洗衣)、SR(缓释)
| 设置 | 带 | 扫描 | TeCo 公司 | 泰德 | TED-LaST 系列 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | |
| 不锈钢 | 46.2 | 8.7 | 85.5 | 44.0 | 20.0 | 1.9 | 95.4 | 93.9 | 94.1 | 95.5 |
| SS+L | 94.4 | 94.6 | 83.3 | 38.5 | 18.1 | 1.9 | 90.8 | 83.3 | 93.3 | 94.6 |
| SS+SR | 28.6 | 4.6 | 83.2 | 38.1 | 18.1 | 1.8 | 94.7 | 75.3 | 92.9 | 88.0 |
| SS+L+SR | 58.7 | 13.1 | 82.9 | 37.5 | 16.7 | 1.9 | 88.0 | 67.1 | 93.1 | 91.0 |
表 VII:在 ResNet-20 下,在 CIFAR-10 上使用 SS&TA (Source-Specific&Trigger Attribute) 目标映射对攻击的不同防御性能(精度和 F1 分数,以 % 为单位)。 设置:SS&TA(源特定&触发器属性)、L(洗衣)、SR(缓释)
| 设置 | 带 | 扫描 | TeCo 公司 | 泰德 | TED-LaST 系列 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | |
| SS&TA | 83.3 | 17.9 | 85.3 | 42.7 | 10.2 | 1.7 | 96.5 | 90.7 | 94.0 | 92.8 |
| SS&TA+L | 84.4 | 44.7 | 81.3 | 34.4 | 25.0 | 4.9 | 91.2 | 86.5 | 93.4 | 89.9 |
| SS&TA+SR | 12.1 | 1.5 | 81.9 | 35.4 | 16.4 | 1.9 | 89.4 | 58.7 | 92.0 | 85.6 |
| SS&TA+L+SR | 46.6 | 11.9 | 85.2 | 43.0 | 16.7 | 1.9 | 89.5 | 76.4 | 91.5 | 87.9 |
表 VIII:在 ResNet-20 下对 GTSRB 上的基本目标映射攻击的不同防御性能(精度和 F1 分数,以 % 为单位)。 设置:B(基本)、L(洗衣)、SR(缓释)
| 设置 | 带 | 扫描 | TeCo 公司 | 泰德 | TED-LaST 系列 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | |
| B | 91.6 | 87.3 | 90.9 | 79.3 | 89.9 | 57.7 | 95.1 | 97.0 | 95.1 | 97.0 |
| L | 79.7 | 21.8 | 89.2 | 56.7 | 63.2 | 15.1 | 95.5 | 97.7 | 95.5 | 97.7 |
| 锶 | 3.3 | 0.4 | 91.0 | 64.9 | 88.0 | 51.8 | 94.6 | 97.2 | 95.5 | 97.7 |
| L+SR | 5.3 | 0.4 | 89.8 | 59.1 | 78.0 | 29.4 | 94.6 | 97.2 | 95.5 | 97.7 |
表 IX:在 ResNet-20 下,在 GTSRB 上使用 SS(源特定)目标映射对攻击进行不同防御的性能(精度和 F1 分数,以 % 为单位)。 设置: SS(特定于来源)、L(洗衣)、SR(缓释)
| 设置 | 带 | 扫描 | TeCo 公司 | 泰德 | TED-LaST 系列 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | |
| 不锈钢 | 45.7 | 11.2 | 84.6 | 41.5 | 65.0 | 13.6 | 94.7 | 97.3 | 94.9 | 97.4 |
| SS+L | 15.6 | 1.9 | 94.8 | 93.1 | 78.0 | 29.4 | 94.5 | 97.2 | 94.9 | 97.4 |
| SS+SR | 3.3 | 0.4 | 79.1 | 30.5 | 87.4 | 49.7 | 95.9 | 95.2 | 96.0 | 96.6 |
| SS+L+SR | 3.2 | 0.4 | 95.0 | 95.2 | 56.3 | 12.0 | 94.6 | 95.1 | 94.8 | 97.2 |
表 X:在ResNet-20下的GTSRB上使用SS&TA(源特定和触发器属性)目标映射对攻击的不同防御性能(精度和F1分数)以%为单位)。 设置:SS&TA(源特定&触发器属性)、L(洗衣)、SR(缓释)
| 设置 | 带 | 扫描 | TeCo 公司 | 泰德 | TED-LaST 系列 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | 精度 | F1 分数 | |
| SS&TA | 4.5 | 0.4 | 74.5 | 24.4 | 87.4 | 49.7 | 94.3 | 97.1 | 94.3 | 97.1 |
| SS&TA+L | 67.1 | 16.5 | 95.0 | 95.3 | 16.9 | 1.9 | 94.9 | 96.7 | 95.9 | 97.9 |
| SS&TA+SR | 31.0 | 6.5 | 84.3 | 40.7 | 16.7 | 1.9 | 95.3 | 97.6 | 95.7 | 97.8 |
| SS&TA+L+SR | 2.9 | 0.4 | 94.9 | 94.7 | 17.5 | 1.9 | 95.4 | 95.6 | 95.7 | 97.7 |
表 XI:ImageNet100 上的攻击性能和 TED-LaST 有效性
| 攻击性能 | TED-Last 性能 | |||
|---|---|---|---|---|
| 设置 | ASR (%) | 清洁 ACC (%) | 精度 (%) | F1 分数 (%) |
| B | 100 | 83.2 | 93.0 | 92.5 |
| L | 100 | 82.4 | 95.4 | 93.1 |
| 锶 | 100 | 83.4 | 95.0 | 95.0 |
| L+SR | 87.0 | 78.5 | 94.2 | 87.1 |
| 不锈钢 | 99.8 | 82.4 | 95.8 | 95.5 |
| SS+L | 100 | 82.7 | 94.4 | 95.4 |
| SS+SR | 81.3 | 84.2 | 95.0 | 97.2 |
| SS+L+SR | 88.8 | 82.3 | 94.8 | 95.5 |
| SS&TA | 100 | 80.1 | 96.2 | 98.1 |
| SS&TA+L | 100 | 81.1 | 94.7 | 95.1 |
| SS&TA+SR | 94.8 | 84.1 | 91.9 | 89.9 |
| SS&TA+L+SR | 88.8 | 83.6 | 94.8 | 97.2 |
V-B2 号结果
表 V、VI 和 VII 显示了 TED-LaST 对 CIFAR-10 上各种后门攻击的稳健性。TED-LaST 始终优于包括 STRIP、SCAn、TeCo 和 TED 在内的现有防御措施,尤其是针对增强型自适应攻击,验证了我们在 II-C 部分中的分析。
对于 SCAn,它在 Adap-Blend 攻击时的性能会显著降低,在这种攻击中,攻击者故意最小化干净样本和中毒样本之间的特征表示差异,从而挑战其基于分布的检测机制。 STRIP 显示出对自适应攻击的固有局限性,尤其是 Adap-Patch,攻击者通过削弱后门触发器和目标标签之间的相关性来成功逃避基于熵的检测。 同样,当攻击者故意将恶意样本与潜在空间中的干净样本混合时,TeCo 的有效性会降低,这与[27].
随着攻击复杂性的增加,TED-LaST 的有效性变得更加明显,主要是由于:(1) 潜在空间不可分离性:自适应攻击诱导特征空间不可分离性,挑战依赖于明确的良性-恶意分离的防御;(2) 目标映射复杂性:复杂的映射模式降低了作为恶意指标的触发可靠性,特别是影响了 TED 的拓扑分析。TED-LaST 的受监管标签动态跟踪和自适应加权机制有效地应对了这些挑战。这种强大的性能源于 TED-LaST 通过监督标签动态跟踪捕获细微的类特异性异常的能力,特别有效地对抗了在全球拓扑空间中模糊良性-恶意区别的攻击。
GTSRB 的结果(表 VIII 、 IX 和 X)进一步证明了 TED-LaST 的优越性。虽然防御效果通常会随着目标映射复杂性从 Basic 增加到 SS&TA 而下降,但 TED-LaST 的性能下降最小。例如,在 GTSRB 的 SS+SR 场景中,TED-LaST 保持 96.6% 的 F1 分数,而 TED 的 F1 分数为 95.2%。即使在 CIFAR-10 上最复杂的 SS&TA+L+SR 攻击下,TED-LaST 也能达到 87.9% 的 F1 分数,大大优于 TED 的 76.4%。
V-CTED-LaST 对大规模数据集上增强自适应攻击的有效性
为了验证 TED-LaST 的可扩展性和有效性,我们在 ImageNet100(ImageNet 的一个子集)上对其进行了评估[49]包括 100 个类。我们的实验使用 224x224 像素的图像,即 ResNet101 模型[48]和调整大小的 ?Hello Kitty?触发器覆盖整个图像。 ImageNet100 的类多样性增加,在拓扑空间中引入了更高的复杂性。良性样本通过更复杂的流形导航,与较小的数据集相比,遍历更大的拓扑距离。这给我们的防御系统带来了挑战,要求它区分较大的自然变化和攻击引起的细微变化。 尽管存在这些挑战,如表 XI 所示,TED-LaST 在各种增强型自适应攻击配置中表现出强大的性能。它在不同的攻击设置中始终保持高准确率(通常超过 94%)和强大的 F1 分数(大多高于 90%)。 即使在最复杂的攻击场景 (SS&TA+L+SR) 中,TED-LaST 也能达到 97.2% 的 F1 分数,展示了其适应复杂攻击模式的能力。 这种性能凸显了 TED-LaST 在更大规模、更复杂的图像任务和实际应用中的强大可扩展性。
六消融研究
VI-A 型离群值检测中的标签信息
这项消融研究考察了特定于类的信息在增强对自适应攻击的防御稳健性方面的重要性。无花果。图 6 显示了不同的训练数据组成对 Adap-Blend 异常值检测性能的影响(图 D)。6a) 和 Adap-Patch (图 .6b) 攻击。
仅对来自预测类的干净样本进行训练可产生最高的 AUROC 分数。包含其他随机类会降低性能,第一个不相关的类会导致最显著的下降。进一步添加导致 AUROC 评分持续下降,下降速度下降。
这种退化来自训练数据中特定于类的拓扑特征的稀释。随着不相关类的引入,检测器识别攻击引起的与预期类模式的偏差的能力会减弱。这一观察结果与拓扑空间中的不可分离性分析(第 III-A1 节)一致,其中自适应攻击模糊了干净样本和中毒样本之间的区别。
VI-B 型不同 CTD 阈值下的自适应加权
我们研究了基于模块化的加权方法与非加权方法在各种累积拓扑距离 (CTD) 阈值上的有效性。CTD 度量(方程 (15))量化了样本遍历网络图层时的拓扑距离变化。如图 1 所示。2a 和图 .2b,Adap-Blend 和 Adap-Patch 攻击都会生成具有不同 CTD 值的恶意样本。CTD 值较低的样本(代表更细微的扰动)通常更难检测。
我们将 CTD 阈值比率定义为 CTD 中位数除以实际 CTD 值。较高的比率对应于较低的 CTD 值,表示更细微的扰动。我们的实验使用具有相同数量的恶意样本和干净样本的数据集,并根据不同的 CTD 阈值进行筛选。 无花果。7 说明了 CTD 阈值比率中模块化加权和非加权方法之间的性能差异。
结果揭示了一个明显的趋势:随着 CTD 阈值比率的增加(即,当我们关注 CTD 值较低的恶意样本时),基于模块化的加权方法始终优于非加权方法。当 CTD 阈值比率较高时,这种性能差距会变得更加明显。
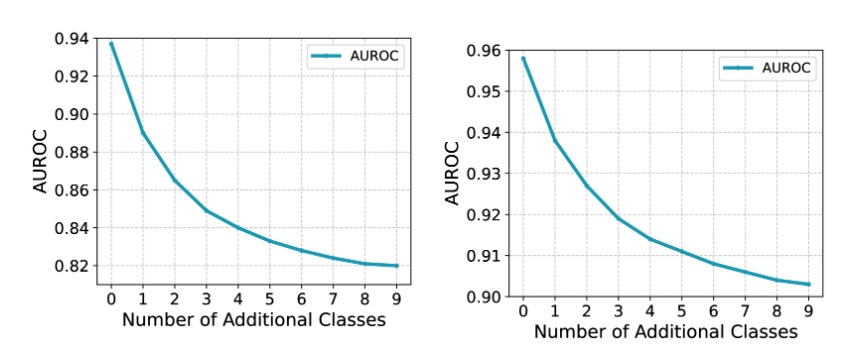
图 6:AUROC 用于异常值检测,在 (a) Adap-Blend 和 (b) CIFAR-10 上的 Adap-Patch 攻击下具有不同数量的附加类。x 轴表示训练数据中包含的其他随机类的数量,而 y 轴显示相应的 AUROC 分数。

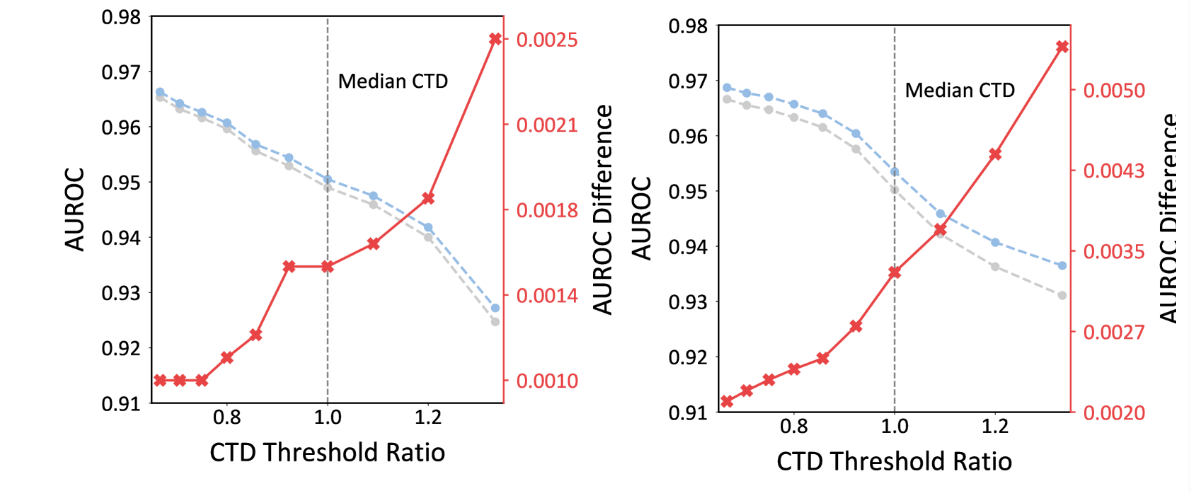
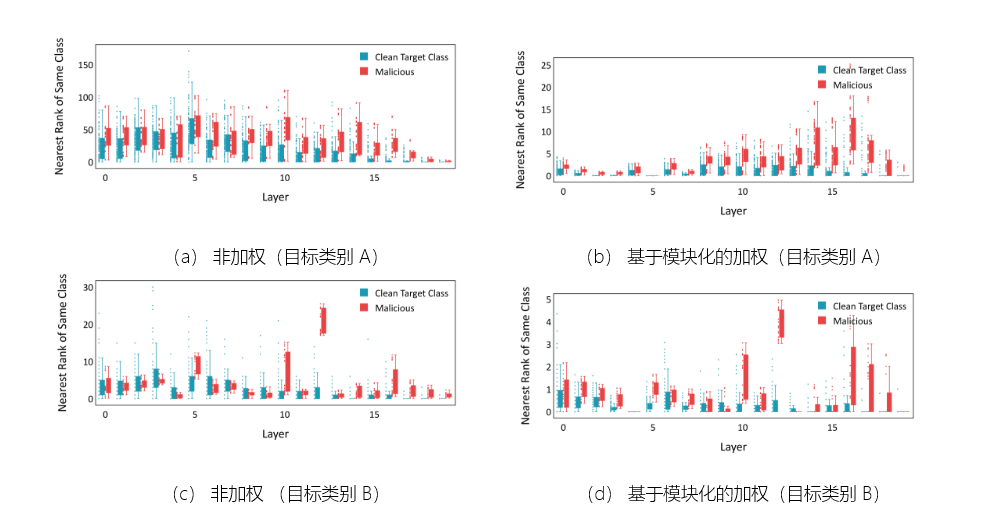
图 8:具有动态目标的拓扑特征向量与 SS&TA+L+SR 的箱形图。(a) 和 (c) 显示了两个不同目标类别的未加权特征,揭示了限制区分的细微扰动。(b) 和 (d) 表明,在对各自的目标类别应用基于模块化的自适应层强调后,干净样本和恶意样本之间的分离有所改善。
VI-C 型TED-LaST 抵御自适应攻击的直觉
自适应后门攻击通过将中毒数据隐藏在神经网络的复杂拓扑空间中,带来了重大挑战。如图 1 所示。1a 和图 .1b,这些攻击模糊了干净样品和中毒样品之间的界限。
为了应对这些挑战,我们的防御策略从全局分析转向更精细的方法。此策略基于这样一个前提,即即使是细微的作也会留下可检测的类跟踪。具体来说,适应性攻击不可避免地会导致目标类别内偏离良性行为(在第 III-B1 节中讨论)。这些偏差虽然很微妙,但为我们的检测方法提供了关键指标。我们还发现,额外的类增强并不能增强检测能力(在第 VI-A 节中讨论)。
我们基于模块化的加权方法始终优于非加权方法,特别是对于具有细微扰动的恶意样本(第 VI-B 节)。这种灵敏度的提高源于加权方案对信息量最大的拓扑特征的强调,从而能够精细区分良性样本和恶意样本。
重要的是,即使面对增强型自适应攻击,我们的自适应加权方法仍然有效。这些高级攻击使用动态目标类和共享触发器,将恶意样本与拓扑空间中的良性表示深度混合。尽管进行了这种复杂的混合,我们的方法仍然可以检测到这些攻击引入的细微扰动(如附录 B 所示)。
七结论
本研究介绍了 TED-LaST,这是一种针对 DNN 中自适应后门攻击的新型防御策略。TED-LaST 利用目标类别的持续拓扑扰动,并使用监督标签信息来增强中毒样本和干净样本之间的区别。我们实现了自适应层强调,以解决这些攻击引起的细微扰动。 在对抗 SOTA 自适应攻击和我们提出的增强型自适应攻击方面,我们的方法优于几种最先进的防御措施。未来的工作可能包括进一步提高防御效果,同时探索 TED-LaST 在联邦学习或多模态学习场景中的应用。这些扩展将有助于增强强大的机器学习的安全性。






