Linux的非连续内存分配,介绍vmalloc机制,阐述内核如何管理vmalloc地址空间,以及在此空间内进行内存分配与释放的流程。

描述虚拟内存区
- 管理机制与数据结构:
vmalloc地址空间由资源映射分配器管理,struct vm_struct负责存储基地址、大小等键值对信息 。其字段包括flags(如VM_ALLOC、VM_IOREMAP)、addr(内存块起始地址 )、size(内存块大小 )、next(指向下一个vm_struct的指针 ),所有vm_struct以地址为序,由vmlist_lock锁保护的链表链接 。 - 内存区域链接与查找:内存区域通过
next字段链接,以地址排序,为防止溢出,区域间至少隔一个页面 。内核分配新内存时,get_vm_area()线性查找vm_struct链表,kmalloc()分配结构体空间;进行I/O重映射时,直接调用函数完成请求区域映射。
分配非连续区域
- API 函数:Linux提供
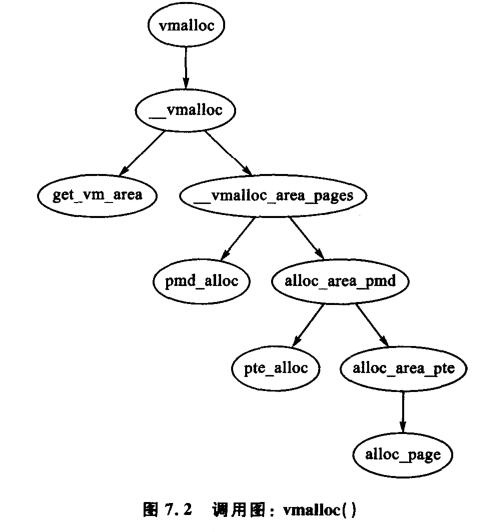
vmalloc()、vmalloc_dma()、vmalloc_32()在连续虚拟地址空间分配内存,仅size一个参数(值为下一页边距向上取整 ),返回新分配区域线性地址 。 - 分配步骤:第一步,
get_vm_area()查找vm_struct线性链表,返回描述区域的新结构体 ;第二步,vmalloc_area_pages()分配所需PGD记录,alloc_area_pmd()分配PMD记录,alloc_area_pte()分配PTE记录,alloc_page()分配页面 。vmalloc()更新的页表不属于当前进程,进程访问vmalloc区域会发生缺页中断异常,中断处理代码利用主页表信息更新当前进程页表 。
本质总结
- vmalloc() 的内存分配机制:
-
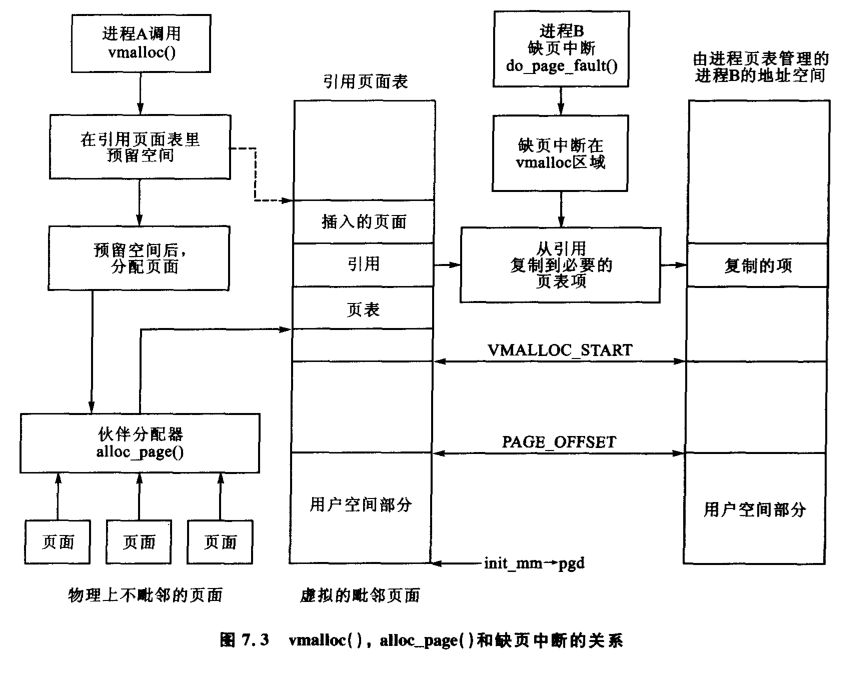
- 本质:vmalloc() 通过在虚拟地址空间中预留连续的虚拟内存,并结合伙伴分配器(alloc_page())分配物理上可能不连续的页面,构建虚拟连续的内存区域。
- 核心流程:
-
-
- 在引用页面表中预留虚拟地址空间。
- 使用伙伴分配器分配物理页面(可能不连续)。
- 将分配的物理页面映射到预留的虚拟地址,形成虚拟连续的内存。
-
-
- 意义:vmalloc() 提供了一种灵活分配大块虚拟连续内存的方式,适用于需要动态分配非连续物理内存的场景,体现了 Linux 虚拟内存管理的解耦特性。
- 缺页中断处理(vmalloc 区域):
-
- 本质:当进程访问 vmalloc 区域的页面时,若发生缺页中断,系统通过复制引用页面表中的页表项到进程的页表中,动态建立虚拟地址到物理页面的映射,确保访问的正确性。
- 核心流程:
-
-
- 进程 B 访问 vmalloc 区域引发缺页中断(do_page_fault())。
- 系统从引用页面表复制相关页表项到进程 B 的页表。
- 完成映射后,进程 B 可正常访问该页面。
-
-
- 意义:通过延迟映射(按需分配),Linux 高效管理虚拟内存,减少初始内存分配开销,同时保证多进程共享和访问 vmalloc 区域的正确性。
总体本质
vmalloc() 和缺页中断处理体现了 Linux 虚拟内存管理的核心思想:虚拟与物理分离、按需分配、动态映射。vmalloc() 提供虚拟连续内存的抽象,物理页面通过伙伴分配器灵活分配;缺页中断则通过动态页表映射实现按需加载,优化内存使用效率并支持多进程协作访问。
7.3 释放非连续内存
- 释放函数:
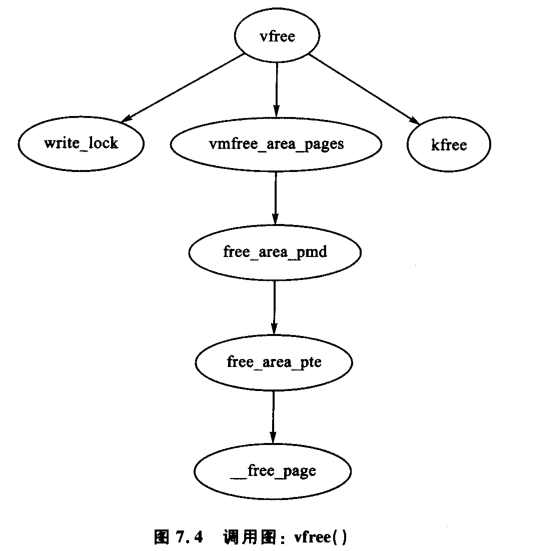
vfree()负责释放虚拟内存区域,先线性查找vm_struct链表,找到目标区域后调用vmfree_area_pages()。 - 释放操作:
vmfree_area_pages()与vmalloc_area_pages()相反,遍历页表,清除该区域页表记录和相应页面 。
7.4 2.6内核新特性
- 分配页面API变化:2.6内核中非连续内存分配基本与2.4内核保持一致,但分配页面内部API有细微差别。2.4内核中
vmalloc_area_pages()遍历页表并调用alloc_area_pte()分配PTE及页表;2.6内核中页表由vmalloc()预先分配,存储在数组中传给map_vm_area(),由其向内核页表插入页面 。 get_vm_area()函数变化:get_vm_area()也有细微改变,调用时仍遍历vmalloc虚拟地址空间寻找空闲区域,调用者可直接调用__get_vm_area()并指明范围,以只遍历vmalloc地址空间一部分,还适用于高级RISC机器(ARM)装载模块 。- 新接口引入:引入新接口
vmap(),负责向vmalloc地址空间插入页面数组,仅用于声音子系统内核,具有向后兼容性,可减轻特定供应商补丁应用负担 。
🌍 思考:什么是非连续内存分配?非连续内存分配和 伙伴系统有什么关系?
什么是非连续内存的分配和释放?
- 非连续内存分配:
-
- 非连续内存分配是指在 虚拟地址空间 中分配一块 连续的虚拟地址,但这些虚拟地址映射到的 物理页面 可以是 非连续的。
- 这与伙伴系统(Buddy System)的连续内存分配不同,后者分配的页面在物理内存中是连续的(以 2 的幂次方页面块为单位)。
- 非连续内存分配适用于需要大块虚拟地址空间但不要求物理连续性的场景,例如内核模块加载、驱动程序的缓冲区分配或 I/O 映射。
- 释放非连续内存:
-
- 释放非连续内存是将之前分配的虚拟地址空间及其关联的物理页面归还给系统。
- 释放过程需要清理页表(解除虚拟地址到物理页面的映射)并将物理页面归还给伙伴系统,以便重新分配。
- 为什么需要非连续内存分配?
-
- 物理内存可能因碎片化而无法提供大块连续页面,但虚拟地址空间是连续的,vmalloc 通过页表映射实现虚拟地址连续性。
- 适合内核中需要大块内存但对物理连续性要求不高的场景,如内核模块、设备驱动或文件系统缓存。
vmalloc 机制概述
vmalloc 是 Linux 内核中用于分配非连续内存的主要机制,运行在内核虚拟地址空间的一个专用区域(称为 vmalloc 地址空间)。它通过页表将连续的虚拟地址映射到可能非连续的物理页面,解决了物理内存碎片问题。
- vmalloc 地址空间:
-
- 在 32 位系统中,vmalloc 地址空间通常位于内核地址空间的高地址区域(例如 3GB~4GB 之间的某个范围)。
- 在 64 位系统中,vmalloc 地址空间更大,位于内核地址空间的特定区域(由架构定义,例如 x86_64 的
VMALLOC_START到VMALLOC_END)。 - 这一区域专门用于非连续内存分配,独立于直接映射区域(内核通过直接映射访问物理内存)和用户空间。
- 核心功能:
-
- 提供连续的虚拟地址,映射到非连续的物理页面。
- 支持动态分配和释放,适用于内核模块、驱动程序等场景。
- 通过页表管理虚拟到物理的映射,分配时可能触发缺页中断。
描述虚拟内存区
管理机制与数据结构
管理机制:
- vmalloc 地址空间由 资源映射分配器 管理,负责跟踪分配的虚拟内存区域。
- 每个分配的区域由
struct vm_struct描述,存储在全局链表中。
数据结构:struct vm_struct
- 核心字段:
-
-
addr:内存块的起始虚拟地址。size:内存块的大小(包括保护页面,向上取整到页面边界)。flags:标志位,例如VM_ALLOC(普通 vmalloc 分配)、VM_IOREMAP(I/O 重映射)。next:指向下一个vm_struct的指针,构成链表。
-
-
- 所有
vm_struct实例组成一个全局链表,按虚拟地址排序,由vmlist_lock(自旋锁)保护,防止并发访问导致不一致。
- 所有
内存区域链接与查找:
-
- 内存区域通过
next字段链接成单向链表,按地址顺序排列。 - 为防止溢出,区域之间至少间隔一个页面(称为 保护页面,guard page),避免分配区域相互干扰。
- 分配时:
- 内存区域通过
-
-
get_vm_area()线性遍历vm_struct链表,查找适合的空闲虚拟地址范围。- 使用
kmalloc()分配vm_struct结构体的内存。
-
-
- I/O 重映射:
-
-
- 对于 I/O 映射(如设备驱动的内存映射),内核直接调用
ioremap()或相关函数,创建vm_struct并映射到设备物理地址。
- 对于 I/O 映射(如设备驱动的内存映射),内核直接调用
-
2. 分配非连续区域
API 函数
- Linux 提供以下 vmalloc 相关 API,用于在 vmalloc 地址空间分配连续虚拟地址:
-
vmalloc(size):分配指定大小的虚拟内存,适合通用场景。vmalloc_dma():分配适合 DMA(直接内存访问)的内存(可能限制在特定物理地址范围)。vmalloc_32():分配 32 位地址范围内的内存(适用于 32 位设备在 64 位系统中的兼容性)。
- 参数:
-
- 所有 API 只需一个
size参数,实际分配大小会向上取整到页面边界(例如 4KB)。
- 所有 API 只需一个
- 返回值:
-
- 返回分配区域的起始虚拟地址(连续的),或 NULL(分配失败)。
分配步骤
- 查找虚拟地址范围:
-
- 调用
get_vm_area(),线性遍历vm_struct链表,找到一块未使用的虚拟地址范围(考虑保护页面)。 - 创建新的
vm_struct实例(通过kmalloc()分配),记录分配的地址和大小。
- 调用
- 分配页面并更新页表:
-
- 调用
vmalloc_area_pages(),为分配的虚拟地址范围建立页表映射:
- 调用
-
-
alloc_area_pgd():分配或更新页面全局目录(PGD,Page Global Directory)。alloc_area_pmd():分配页面中间目录(PMD,Page Middle Directory)。alloc_area_pte():分配页面表项(PTE,Page Table Entry)。alloc_page():通过伙伴系统分配物理页面(可能非连续)。
-
-
- 每个虚拟页面映射到一个物理页面,完成虚拟到物理的映射。
- 缺页中断处理:
-
- vmalloc 分配的页表不直接绑定到当前进程的页表。
- 当进程首次访问 vmalloc 分配的虚拟地址时,会触发 缺页中断(page fault)。
- 中断处理程序根据内核的主页表(
init_mm)信息更新当前进程的页表,确保访问有效。
3. 释放非连续内存
释放函数
- vfree():
-
- 负责释放 vmalloc 分配的虚拟内存区域。
- 输入参数为虚拟地址(
void *addr),由调用者提供。
释放操作
- 查找目标区域:
-
vfree()线性遍历vm_struct链表,找到与输入地址匹配的vm_struct实例。
- 清理页表和页面:
-
- 调用
vmfree_area_pages(),与分配过程相反:
- 调用
-
-
- 遍历相关页表(PGD、PMD、PTE),清除虚拟地址到物理页面的映射。
- 释放关联的物理页面(通过
__free_pages()放回伙伴系统)。
-
-
- 删除对应的
vm_struct实例(通过kfree()释放),并更新vm_struct链表。
- 删除对应的
- 同步页表:
-
- 如果当前进程的页表引用了被释放的 vmalloc 区域,内核会同步更新页表(例如通过 TLB 刷新)。
vmalloc 机制的核心特点
- 虚拟地址连续,物理地址非连续:
-
- vmalloc 通过页表映射实现虚拟地址连续性,物理页面可来自伙伴系统的任意空闲页面。
- 开销较高:
-
- 相比伙伴系统的连续内存分配,vmalloc 需要管理页表,分配和释放涉及多次页面操作,性能开销较大。
- 适用场景:
-
- 内核模块加载(需要大块虚拟地址空间)。
- 设备驱动的缓冲区分配(尤其是 I/O 映射)。
- 某些文件系统或网络协议栈的临时缓冲区。
- 限制:
-
- vmalloc 区域的内存不能直接用于 DMA(除非使用
vmalloc_dma())。 - 分配和释放的开销较高,不适合高频分配场景。
- vmalloc 区域的内存不能直接用于 DMA(除非使用
- 非连续内存分配与释放:
-
- 非连续内存分配通过 vmalloc 在虚拟地址空间分配连续地址,映射到非连续物理页面,适用于物理内存碎片化场景。
- 释放过程通过
vfree()清理页表映射并归还物理页面到伙伴系统。
- vmalloc 机制:
-
- 管理:通过
vm_struct链表和vmlist_lock管理 vmalloc 地址空间。 - 分配:
get_vm_area()查找虚拟地址,vmalloc_area_pages()分配页面并更新页表,触发缺页中断动态更新进程页表。 - 释放:
vfree()查找目标区域,vmfree_area_pages()清理页表并释放页面。
- 管理:通过
- 与伙伴系统的关系:
-
- vmalloc 依赖伙伴系统分配物理页面(通过
alloc_page())。 - 释放时,物理页面通过
__free_pages()归还给伙伴系统。
- vmalloc 依赖伙伴系统分配物理页面(通过
Artifact:vmalloc 分配流程伪代码
/* 分配非连续内存 */
void *vmalloc(size_t size) {// 1. 查找可用虚拟地址范围struct vm_struct *area = get_vm_area(size);if (!area)return NULL;
//2. 分配物理页面并建立页表映射
if (vmalloc_area_pages(area) < 0) {kfree(area);return NULL;
}
// 3. 返回虚拟地址
return area->addr;
}
/* 查找虚拟地址范围 */
struct vm_struct *get_vm_area(size_t size) {struct vm_struct *area = kmalloc(sizeof(struct vm_struct));if (!area)return NULL;
// 线性查找 vm_struct 链表,找到合适地址
spin_lock(&vmlist_lock);
area->addr = find_free_vaddr(size); // 确保地址连续且有保护页面
area->size = roundup(size, PAGE_SIZE);
insert_vmlist(area); // 插入链表,按地址排序
spin_unlock(&vmlist_lock);return area;
}
/* 分配页面并更新页表 */
int vmalloc_area_pages(struct vm_struct *area) {for (vaddr = area->addr; vaddr < area->addr + area->size; vaddr += PAGE_SIZE) {struct page *page = alloc_page(GFP_KERNEL); // 通过伙伴系统分配页面if (!page)return -ENOMEM;map_page_to_vaddr(vaddr, page); // 更新 PGD/PMD/PTE}return 0;
}
/* 释放非连续内存 */
void vfree(void *addr) {// 1. 查找 vm_structspin_lock(&vmlist_lock);struct vm_struct *area = find_vm_struct(addr);if (!area) {spin_unlock(&vmlist_lock);return;}remove_vmlist(area); // 从链表移除spin_unlock(&vmlist_lock);
// 2. 清理页表并释放页面
vmfree_area_pages(area);// 3. 释放 vm_struct
kfree(area);
}
/* 清理页表和页面 */
void vmfree_area_pages(struct vm_struct *area) {for (vaddr = area->addr; vaddr < area->addr + area->size; vaddr += PAGE_SIZE) {struct page *page = vaddr_to_page(vaddr);unmap_page(vaddr); // 清除页表映射__free_pages(page, 0); // 归还页面到伙伴系统}
}
🌍 思考:vmalloc 和 kmalloc 有什么区别?分配的连续虚拟地址和物理页面 是通过页表对应起来的吗?
vmalloc 和 kmalloc 的区别
内存分配方式:
- kmalloc:分配物理连续的内存,适用于较小的内存块(通常不超过几页),直接从内核的页面分配器获取连续的物理页面。效率高,适合高性能场景(如设备驱动程序)。
- vmalloc:分配虚拟连续但物理上可能不连续的内存,适合需要较大内存块的场景。vmalloc 通过在虚拟地址空间中预留连续区域,并通过页表映射到可能不连续的物理页面。
内存大小限制:
- kmalloc:受限于物理内存的连续性,分配大小通常较小(一般不超过 4MB,具体取决于系统配置)。
- vmalloc:可以分配较大的内存块(通常用于几十 KB 到几 MB 的分配),但分配和访问效率低于 kmalloc,因为需要额外的页表操作。
性能与开销:
- kmalloc:物理连续内存访问效率高,页表映射简单,开销小。
- vmalloc:由于物理页面可能不连续,需要通过页表进行虚拟到物理的映射,访问时可能引发 TLB(Translation Lookaside Buffer)缓存未命中,导致性能开销较大。
使用场景:
- kmalloc:适用于内核中需要高性能、小块内存的场景,如设备驱动、缓冲区等。
- vmalloc:适用于需要大块内存但不要求物理连续的场景,如模块加载、大型数据结构分配等。
连续虚拟地址与物理页面的页表对应关系
vmalloc 分配的连续虚拟地址与物理页面是通过页表对应起来的。
- 工作原理:
-
- vmalloc 在虚拟地址空间中预留一块连续的虚拟地址范围。
- 通过伙伴分配器(alloc_page())获取物理页面,这些页面在物理内存中可能不连续。
- 内核为这些物理页面在页表中创建映射,将虚拟地址映射到对应的物理页面。
- 页表存储在内核的引用页面表中,必要时(例如缺页中断)会将页表项复制到访问该内存的进程的页表中。
- 页表的作用:
-
- 页表维护虚拟地址到物理地址的映射关系,确保进程访问 vmalloc 分配的虚拟地址时,能够正确找到对应的物理页面。
- 对于 vmalloc 区域,页表映射是动态的,可能在缺页中断(do_page_fault())时按需建立,以减少初始分配开销。
- 与 kmalloc 的区别:
-
- kmalloc 分配的内存物理连续,通常只需要单一的页表项或简单的线性映射。
- vmalloc 的物理页面可能分散,页表需要为每个页面单独建立映射,增加了复杂性和开销。
总结
- vmalloc vs kmalloc:
-
- vmalloc 提供虚拟连续、物理可能不连续的大块内存,适合需要较大内存的场景,但性能开销较高。
- kmalloc 提供物理连续的小块内存,性能更高,适合小规模、高效内存分配。
- 页表对应:
-
- vmalloc 的连续虚拟地址通过页表映射到可能不连续的物理页面,页表动态管理映射关系。
- kmalloc 的物理连续性简化了页表映射,通常是直接的线性映射。
体现Linux 虚拟内存管理的灵活性:vmalloc 强调虚拟地址的连续性和大块分配,kmalloc 强调物理连续性和高性能,页表则是两者连接虚拟与物理内存的关键机制。
🌍 思考:为什么 vmalloc 即使有页表的映射也会发生缺页中断?页表项有映射直接去物理地址访问内容不就好了?为什么会缺页呢?
页表映射的建立时机和实际物理内存分配的时机:
vmalloc的延迟分配机制
vmalloc采用的是 延迟分配(lazy allocation)策略:
vmalloc()调用时:
- 只是在vmalloc区域分配了虚拟地址空间
- 建立了VMA(Virtual Memory Area)结构
- 并没有立即分配物理页面。也没有建立完整的页表映射
首次访问时:
- CPU访问虚拟地址时发现页表项为空或无效。
- 触发缺页中断(page fault)。
- 内核在缺页处理函数中才真正分配物理页面。
- 建立虚拟地址到物理地址的页表映射。
为什么这样设计?
内存效率考虑:
- 很多时候分配的内存并不会立即全部使用。
- 延迟分配可以避免浪费物理内存。
- 只有真正访问的页面才会占用物理内存。
性能优化:
- vmalloc()调用可以很快返回。
- 避免在分配时进行大量的页表操作。
- kmalloc:立即分配物理内存和建立映射。
- 用户空间malloc:也采用延迟分配,通过缺页中断按需分配。
- vmalloc:延迟分配,通过缺页中断按需分配。
vmalloc的缺页中断是其设计的核心特性,而不是bug,这种机制实现了内存的按需分配。
🌍 思考: kmalloc 为什么采样立即分配物理内存?kmalloc 建立的映射是页表映射吗?如果是的话, kmalloc 运行在内核态为什么会有页表呢?
kmalloc为什么立即分配物理内存?
设计目的不同:
- kmalloc主要用于内核数据结构的分配(如task_struct、文件描述符等)
- 这些数据结构通常需要立即使用,延迟分配反而会增加开销
- 内核代码路径要求确定性和低延迟,不能容忍缺页中断
使用场景特点:
- 分配的内存块通常较小(几十字节到几KB)
- 分配后立即访问的概率很高
- 内核中断处理、系统调用等关键路径不能被缺页中断打断
kmalloc的映射机制
kmalloc建立的不是页表映射,而是线性映射!
线性映射 vs 页表映射
线性映射(Linear Mapping):
// 简化的线性映射关系
virtual_addr = physical_addr + PAGE_OFFSET
// 例如:物理地址0x1000 -> 虚拟地址0xC0001000(32位系统)特点:
- 虚拟地址和物理地址有固定的偏移关系
- 不需要页表查找,MMU直接通过偏移计算
- 访问速度最快,没有TLB miss的风险
内核态为什么有页表?
内核态确实有页表,但用途不同:
内核虚拟地址空间布局
高地址
┌─────────────────┐
│ 固定映射区 │ (fixmap)├─────────────────┤
│ vmalloc区域 │ ← 需要页表映射
├─────────────────┤
│ 线性映射区 │ ← kmalloc在这里,线性映射
├─────────────────┤
│ 内核代码/数据 │ ← 线性映射
└─────────────────┘
低地址 (PAGE_OFFSET)为什么内核需要页表?
- 线性映射区:直接映射,不需要复杂页表
- vmalloc区:动态映射,需要页表
- 用户空间访问:内核需要访问用户态内存
- 设备内存映射:ioremap等需要页表
// 内核访问用户空间数据
copy_from_user(kernel_buf, user_ptr, size);
// 这时内核需要通过页表访问用户虚拟地址| 特性 | kmalloc | vmalloc |
| 映射方式 | 线性映射 | 页表映射 |
| 分配时机 | 立即分配 | 延迟分配 |
| 物理内存 | 连续 | 可以不连续 |
| 访问速度 | 最快 | 较慢(需要页表查找) |
| 缺页中断 | 不会发生 | 首次访问会发生 |
| 使用场景 | 内核数据结构 | 大块内存、驱动缓冲区 |
所以kmalloc和vmalloc是为不同场景设计的两套内存分配机制,各有其合理性。内核态确实有页表,但kmalloc使用的是更高效的线性映射机制。
🌍 思考:内核虚拟地址空间 是内核进程的虚拟地址空间吗?
内核虚拟地址空间 ≠ 内核进程的虚拟地址空间
内核虚拟地址空间:
- 是全局共享的地址空间
- 所有进程在内核态时都使用同一套内核虚拟地址空间
- 不属于任何特定进程
进程的虚拟地址空间:
- 每个进程有自己独立的用户态虚拟地址空间
- 进程切换时用户态地址空间会切换
- 但内核态地址空间保持不变
完整的虚拟地址空间布局(以32位为例):
4GB ┌─────────────────┐│ ││ 内核虚拟地址空间 │ ← 所有进程共享│ │ (内核代码、kmalloc、vmalloc等)
3GB ├─────────────────┤│ ││ 用户虚拟地址空间 │ ← 每个进程独有│ │ (进程切换时会变化)
0GB └─────────────────┘
为什么这样设计?
内核代码共享:
- 内核代码和数据结构需要被所有进程共享
- 如果每个进程都有独立的内核地址空间,会造成巨大浪费
系统调用一致性:
- 无论哪个进程调用系统调用,内核函数的地址都是一样的
sys_open()函数的虚拟地址对所有进程都相同
实际例子:
// 进程A在内核态
kmalloc(1024); // 返回地址 0xc1234000
// 进程B在内核态
kmalloc(1024); // 返回地址 0xc1235000
// 两个进程看到的内核虚拟地址空间是完全相同的!
// 0xc1234000 对进程A和进程B都指向同一个物理地址内核虚拟地址空间应该理解为:
- 操作系统全局的内核态地址空间
- 被所有进程共享的地址空间
- 包含内核代码、内核数据结构、内核堆等
- 不属于任何特定进程
所以更准确的说法是:内核虚拟地址空间是系统级别的共享地址空间,而不是某个内核进程的私有地址空间。
🌍 思考:内核虚拟地址空间layout从高到底是固定映射区,vmalloc区域,线性映射区和内核代码吗?
是的。
固定映射区 (Fixmap Area):
- 位于最高地址范围。
- 用于特定的固定虚拟地址映射,通常是为了一些特殊用途(如硬件寄存器访问或临时映射)。
- 地址是固定的,映射关系在内核初始化时确定。
vmalloc 区域 (vmalloc Area):
- 位于固定映射区下方。
- 用于动态分配非连续物理内存的虚拟地址空间(通过
vmalloc()函数分配)。 - 适合需要大块虚拟地址但不要求物理连续的场景。
线性映射区 (Direct Mapping Area):
- 也称为低端内存映射区,位于 vmalloc 区域下方。
- 这是内核虚拟地址空间中最大的部分,用于直接映射物理内存(通常是 1:1 映射,虚拟地址与物理地址通过固定偏移关联)。
- 物理内存的绝大部分通过这个区域访问。
内核代码区 (Kernel Code/Text Area):
- 位于最低地址范围。
- 包含内核的可执行代码、数据段(如全局变量)、只读数据等。
- 通常是固定的、连续的虚拟地址空间,直接映射到物理内存的特定区域。
补充说明:
- 架构差异:上述布局以 64 位 x86_64 架构为例,不同架构(如 ARM64、RISC-V)可能有细微差异。例如,ARM64 可能有额外的区域(如模块映射区)或不同的地址划分。
- 地址范围:具体地址范围取决于内核配置(如
CONFIG_VMSPLIT或CONFIG_PAGE_OFFSET)和系统架构。例如,在 x86_64 上,内核虚拟地址通常从0xffff800000000000开始(负地址空间)。 - 内核模块:内核模块的代码和数据通常分配在 vmalloc 区域或专门的模块映射区(视架构而定)。
- 安全性:现代内核可能启用 KASLR(Kernel Address Space Layout Randomization),导致内核代码区和部分映射区的基地址在启动时随机化。
🌍 思考:为什么内核虚拟空间也有 vmalloc 区域?vmlloc 不是用于分配一段连续的虚拟地址吗?但是内核分配空间为什么会用到这个功能?
内核虚拟地址空间中设置 vmalloc 区域 的主要目的是为了满足内核在某些场景下需要分配虚拟地址连续但物理地址可以不连续的内存需求。
1. 为什么内核需要 vmalloc 区域?
在内核中,内存分配通常通过两种主要机制:直接映射区(线性映射区)和 vmalloc 区域。直接映射区通过固定偏移直接映射到物理内存,适合大多数内核内存需求(如 kmalloc 分配的内存)。然而,直接映射区要求物理内存是连续的,而在以下场景中,内核可能需要分配虚拟地址连续但物理地址不连续的内存:
- 大块内存分配:当需要分配较大的内存块时,物理内存可能已经碎片化,无法提供足够大的连续物理页面。此时,vmalloc 可以通过映射不连续的物理页面到连续的虚拟地址空间来满足需求。
- 动态内存需求:某些内核子系统(如文件系统、驱动程序、内核模块)可能需要动态分配较大的内存块,但不要求物理地址连续。vmalloc 提供了这种灵活性。
- 内核模块:加载内核模块时,模块的代码和数据需要分配在虚拟地址空间中。由于模块加载是动态的,vmalloc 区域可以提供连续的虚拟地址空间来映射模块的物理页面。
- 特殊用途:一些内核功能(如大块缓冲区、某些设备驱动的内存映射)可能需要虚拟地址连续的内存,但物理内存可以分散,vmalloc 适合这种场景。
2. vmalloc 的作用:分配连续的虚拟地址
- vmalloc 的核心功能是分配一段虚拟地址连续的内存,而对应的物理页面可以是不连续的。它通过修改内核页表,将不连续的物理页面映射到一段连续的虚拟地址空间。
- 相比之下,
kmalloc(基于 slab 分配器)分配的内存既是虚拟地址连续的,也是物理地址连续的,但受限于物理内存的碎片化,kmalloc通常只适合分配较小的内存块(一般不超过几页)。 - vmalloc 的优势在于它突破了物理内存连续性的限制,适合分配较大或动态的内存块。
3. 内核为什么需要这种功能?
内核使用 vmalloc 的原因可以归纳为以下几点:
- 内存碎片化问题:
-
- 在系统长时间运行后,物理内存可能会变得碎片化,即使有足够的空闲内存,也可能无法找到足够大的连续物理页面。
- vmalloc 通过映射不连续的物理页面到连续的虚拟地址空间,解决了物理内存碎片化的问题。
- 动态性和灵活性:
-
- 内核模块、文件系统缓存(如 VFS 的 dentry 或 inode 缓存)、设备驱动等可能需要动态分配内存,vmalloc 提供了一种灵活的方式来满足这些需求。
- 例如,加载一个内核模块时,模块的代码和数据需要分配在虚拟地址空间中,而 vmalloc 区域可以快速分配连续的虚拟地址。
- 大块内存需求:
-
- 某些场景(如网络堆栈的缓冲区、某些驱动程序的 DMA 缓冲区)需要较大的内存块,而直接映射区的连续物理内存可能不足以满足需求。
- vmalloc 允许内核分配大块虚拟地址空间,而无需担心物理内存的连续性。
- 隔离与管理:
-
- vmalloc 区域的内存分配与直接映射区的内存分配是分开的,这有助于内核内存管理的模块化。
- 例如,vmalloc 分配的内存可以通过独立的页表管理,减少对直接映射区的干扰。
4. vmalloc 的局限性与权衡
虽然 vmalloc 提供了灵活性,但它也有一些缺点,这也是为什么内核不总是使用 vmalloc 的原因:
- 性能开销:vmalloc 需要动态修改页表,每次分配和释放都会涉及页表操作,相比直接映射区的
kmalloc有更高的开销。 - TLB 效率:由于 vmalloc 分配的内存可能映射到不连续的物理页面,可能会导致更多的 TLB(Translation Lookaside Buffer)缓存缺失,影响性能。
- 空间限制:vmalloc 区域的大小是有限的(在 64 位系统中通常是几十 GB,具体取决于架构和配置),因此不能无限制使用。
- 不适合 DMA:由于 vmalloc 分配的内存物理地址不连续,通常不适合直接用于 DMA(直接内存访问),因为大多数硬件要求 DMA 缓冲区物理地址连续。
因此,内核在需要物理地址连续或高性能的场景(如小块内存分配或 DMA)时会优先使用 kmalloc,而在需要虚拟地址连续的大块内存或动态分配时使用 vmalloc。
5. 实际使用场景
以下是一些内核中使用 vmalloc 的典型场景:
- 内核模块:加载内核模块时,模块的代码、数据和符号表分配在 vmalloc 区域。
- 文件系统:文件系统的元数据(如 VFS 的 inode 或 dentry 缓存)可能使用 vmalloc 分配较大的缓冲区。
- 驱动程序:某些设备驱动需要分配较大的非连续内存块(如视频缓冲区或网络数据包缓冲区)。
- 用户空间映射:当内核需要将用户空间的内存映射到内核空间时,可能会使用 vmalloc 区域(例如通过
vmalloc_user)。
6. 总结
内核虚拟地址空间中的 vmalloc 区域是为了满足内核在动态分配大块内存或处理物理内存碎片化时的需求。它通过提供虚拟地址连续但物理地址可以不连续的内存分配,增强了内核的灵活性和内存管理能力。尽管 vmalloc 有性能和使用场景的限制,但它在内核模块加载、文件系统、驱动程序等场景中不可或缺。
🌍 思考:内核中除了有kmalloc,vmalloc还有什么其他malloc吗?
在 Linux 内核中,除了 kmalloc 和 vmalloc,还有其他几种内存分配机制,用于满足不同场景下的内存需求。这些分配器针对内核的不同用途和约束进行了优化。以下是内核中常见的内存分配方式及其特点:
1. kmalloc
- 功能:分配物理和虚拟地址都连续的小块内存,基于 slab 分配器。
- 特点:
-
- 适合分配较小的内存块(通常不超过几页)。
- 分配的内存位于直接映射区,性能高,适合高频小块分配。
- 可通过
GFP_KERNEL、GFP_ATOMIC等标志控制分配行为。 - 常用于内核数据结构(如链表、结构体)或需要物理连续性的场景(如 DMA)。
- 限制:受物理内存碎片化影响,难以分配大块连续内存。
2. vmalloc
- 功能:分配虚拟地址连续但物理地址可以不连续的内存。
- 特点:
-
- 适合分配较大的内存块或动态内存(如内核模块、文件系统缓存)。
- 通过修改页表实现,分配的内存位于 vmalloc 区域。
- 性能开销较高(页表操作、TLB 失效),不适合 DMA。
- 限制:vmalloc 区域大小有限,且分配/释放开销较大。
3. 其他内存分配机制
除了 kmalloc 和 vmalloc,Linux 内核还提供以下内存分配方式:
a. slab 分配器
- 功能:slab 分配器是 kmalloc 的底层实现,但也可以直接使用(如通过
kmem_cache_alloc)。 - 特点:
-
- 提供针对特定对象的高效缓存分配,减少内存碎片。
- 内核为常用数据结构(如 task_struct、inode)创建专用 slab 缓存。
- 可通过
kmem_cache_create创建自定义缓存,kmem_cache_alloc分配内存。
- 用途:适合频繁分配/释放固定大小的对象,如文件系统或网络堆栈中的结构体。
- 区别:kmalloc 是通用的 slab 分配接口,而直接使用 slab 分配器更适合特定对象的高效管理。
b. get_free_pages (GFP) / __get_free_page
功能:直接分配物理和虚拟地址连续的整页内存(基于 buddy 分配器)。
特点:
- 通过
alloc_pages或__get_free_page分配一个或多个页面(通常 4KB 或更大)。 - 提供更底层的控制,适合需要整页内存的场景。
- 支持
GFP_KERNEL、GFP_ATOMIC等标志,控制分配行为(如是否允许睡眠)。
用途:常用于需要大块连续内存的场景,如页表分配或某些驱动程序。
区别:相比 kmalloc,GFP 分配以页面为单位,适合较大内存需求;kmalloc 更适合小块内存。
🌍 思考:内核中页表是 所有内核进程共有的吗?
这个问题涉及到一个重要的概念澄清!
首先:什么是"内核进程"?
在Linux中,我们需要区分几个概念:
真正的内核线程(kernel threads):
- 如
kthreadd、ksoftirqd、migration等 - 这些是纯内核态运行的线程,没有用户态地址空间
普通进程在内核态执行:
- 用户进程通过系统调用进入内核态
- 这时不叫"内核进程",而是"进程的内核态执行"
页表的共享机制
内核态页表:全局共享
// 简化的页表结构
struct mm_struct {pgd_t *pgd; // 页全局目录};关键点:
- 内核态页表项是所有进程共享的
- 用户态页表项是每个进程独有的
- 页表的内核部分在所有进程间保持一致。
mm_struct主要描述用户态虚拟内存。内核空间的映射信息不在mm_struct中。内核空间由全局的数据结构管理。
内核空间的管理
// 内核使用的全局mm_struct
struct mm_struct init_mm = {.mm_rb = RB_ROOT,.pgd = swapper_pg_dir, // 内核页表.mm_users = ATOMIC_INIT(2),.mm_count = ATOMIC_INIT(1),.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),.page_table_lock = SPIN_LOCK_UNLOCKED,.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
};页表的实际共享机制
进程创建时
static int dup_mmap(struct mm_struct *mm, struct mm_struct *oldmm)
{// 1. 分配新的页表mm->pgd = pgd_alloc(mm);// 2. 初始化时,内核空间映射会被复制// 但这些映射指向相同的内核物理页面// 3. 用户空间的VMA会被复制或共享copy_vmas(mm, oldmm);
}
为什么这样设计?
效率考虑:
- 避免每个进程都维护完整的内核页表副本
- 内核代码和数据对所有进程都是相同的
一致性保证:
- 所有进程在内核态看到的虚拟地址映射都相同
kmalloc()返回的地址对所有进程都有效
内核态页表:
是全局共享的,不属于特定进程。所有进程(包括内核线程)共享同一套内核态页表映射。当内核态页表更新时,需要同步到所有进程
用户态页表:每个进程独有。进程切换时会切换用户态页表。内核态页表部分保持不变。




