目录
#1.1什么是Web请求与响应
1.1.1Web请求
1.1.2Web响应
1.1.3HTTP协议概述
1.1.4常见的HTTP状态码包括
#2.1Python的requests库
2.1.1安装requests库
2.1.2发送GET请求
2.1.3发送POST请求
2.1.4处理响应头和状态码
2.1.5发送带查询参数的GET请求
#3.1处理JSON响应
#4.1文件操作
4.1.1打开文件的模式
4.1.2读取文件
4.1.3写入文件
#5.1错误处理与异常捕获
5.1.1try语句的使用
5.1.2捕获常见异常
1.1什么是Web请求与响应?
Web请求与响应是Web通信的基础。Web请求由客户端发起,服务器处理后返回响应。
1.1.1Web请求
Web请求通常包括以下几个部分:
请求行:包括请求方法(GET,POST,PUT,DELETE),URL和HTTP协议版本(如HTTP/1.1)。
请求头:包含关于客户端信息,请求体类型,浏览器类型等元数据。
请求体:在POST请求中包含用户提交的数据,如表单数据或文件。
1.1.2Web响应
Web响应由服务器返回,通常包括以下几个部分:
响应行:包括HTTP协议版本,状态码和状态消息。
响应头:包括关于响应的信息,如内容类型,服务器信息等。
响应体:包含实际返回的数据(如HTML页面,JSON数据等)。
1.1.3HTTP协议概述
HTTP是Web上传输数据的协议,负责浏览器与服务器之间的通信,常见的HTTP方法有:
GET:请求服务器获取资源,通常用于读取数据。
POST:提交数据到服务器,通常用于表单提交,文件上传等。
PUT:更新服务器上的资源。
DELETE:删除服务器上的资源。
1.1.4常见的HTTP状态码包括
200 OK:请求成功,服务器返回所请求的数据。
301 Moved Permanently:资源已永久移动。
404 Not Found:请求资源不存在。
500 Internal Server Error:服务器内部错误。
2.1Python的requests库
Python的requests库发送HTTP请求和处理响应的最常用工具,它提供了简单,直观的API,使得Web请求和响应的操作变得非常容易。通过requests,我们可以轻松地发送GET,POST请求,处理JSON响应,管理请求头等。
2.1.1安装requests库
2.1.2发送GET请求

代码解释:
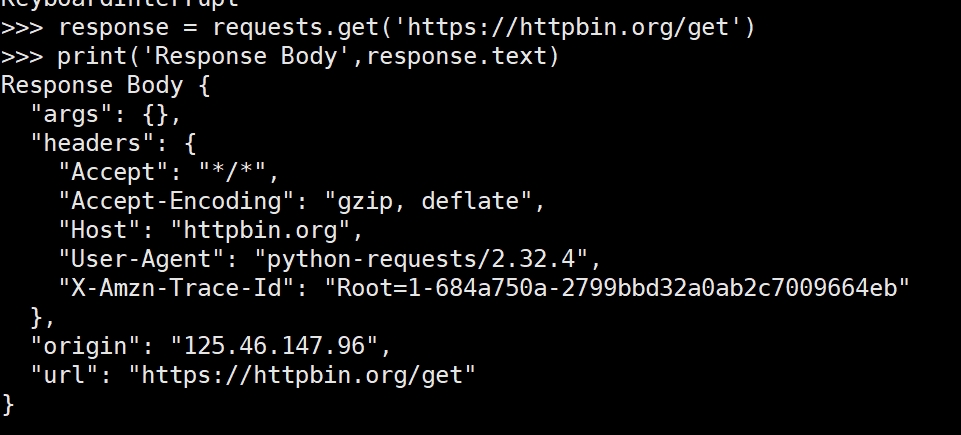
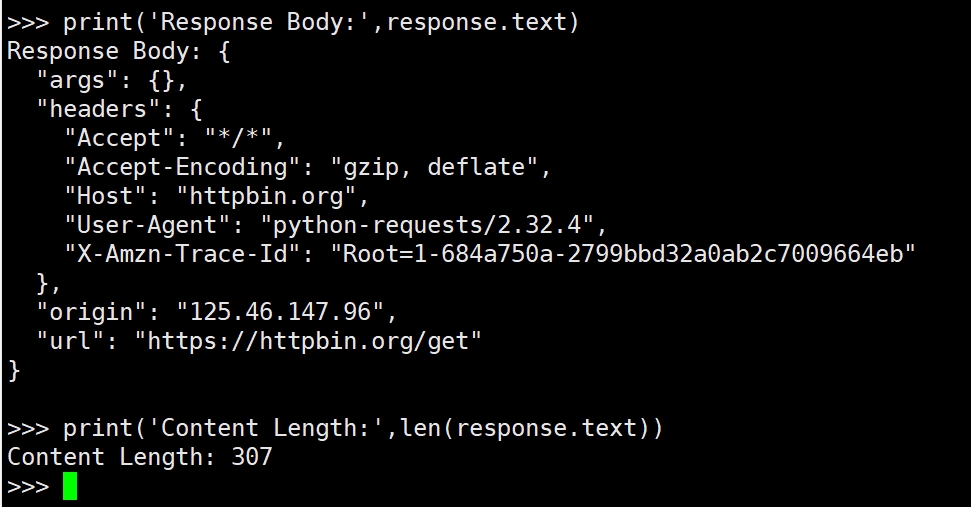
requests.get()用于发送GET请求,获取指定URL的数据。
response.status_code获取HTTP响应状态码。
response.text获取响应的正文内容(通常是HTML或JSON数据)。
response.headers获取响应头。
len(response.text)返回响应正文的长度,帮助我们了解返回内容的大小。
2.1.3发送POST请求
![]()
代码解释:
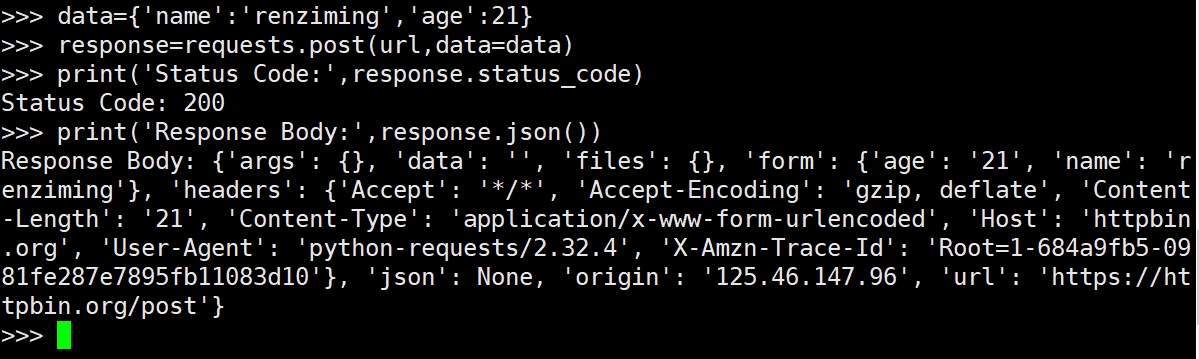
requests.post()用于发送POST请求,将数据提交到服务器。
data参数是一个字典,包含了我们要提交的数据。requests会自动将其编码为application/x-www-from-urlencoded格式。
response.json()用于解析返回的JSON数据。
2.1.4处理响应头和状态码
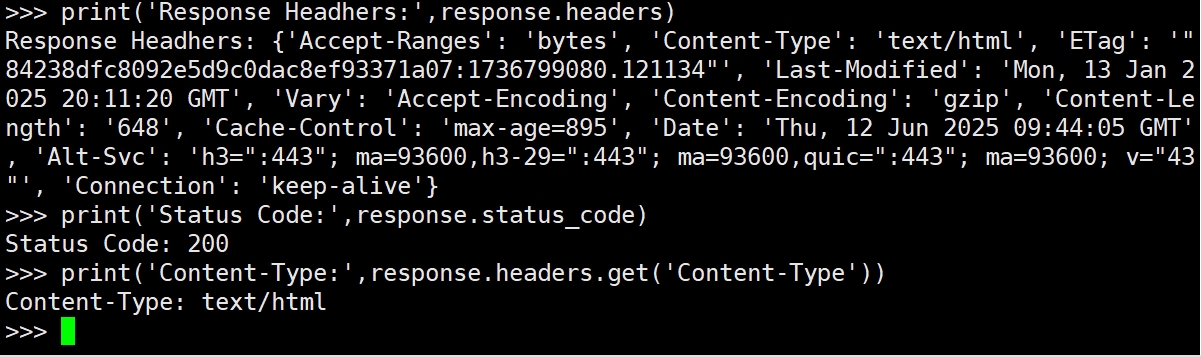
代码解释:
response.headers返回响应头,包含如Content-Type,Date,Server等信息。
response.status_code返回HTTP状态码。
response.headers.get('Content-Type')获取响应的内容类型(如text/html,application/json)。
2.1.5发送带查询参数的GET请求


代码解释:
params是一个字典,包含要传递的查询参数。
requests.get()会自动将这些参数编码到URL中。
3.1处理JSON响应
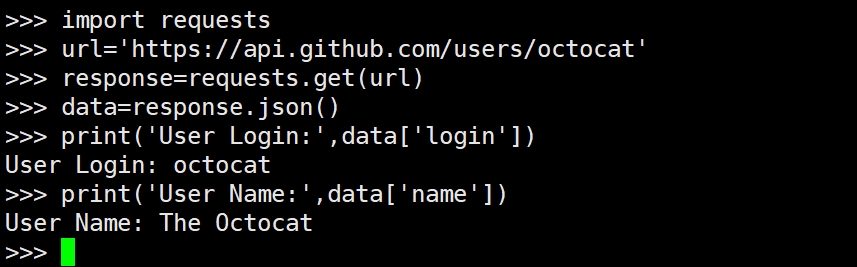
代码解释:
response.json()将响应的内容解析为Python字典,方便我们我们处理JSON数据。
4.1文件操作
文件操作是 Python 编程中常见的任务。Python 提供了多种方法来读取、写入和管理文件,能够处理文本文件、二进制文件以及目录操作等。掌握文件操作的基础和技巧是高效编程的关键。
4.1.1:打开文件的模式
Python 使用内置的 open() 函数来打开文件。打开文件时,我们需要指定文件模式(即操作文件的方式)。常见的文件模式如下:
(1) 常见的文件打开模式
r:只读模式(默认模式)。文件必须存在。如果文件不存在,会抛出 FileNotFoundError 异常。
w:写入模式。如果文件存在,会覆盖文件内容。如果文件不存在,会创建新文件。
a:追加模式。如果文件存在,写入的数据会追加到文件末尾;如果文件不存在,会创建新文件。
x:独占创建模式。若文件已存在,操作会失败并抛出 FileExistsError 异常。此模式通常用于创建文件时防止覆盖现有文件。
rb:二进制读取模式,用于读取非文本文件(如图片、音频文件)。
wb:二进制写入模式,用于写入非文本文件。
r+:读写模式。文件必须存在。既可以读取文件内容,也可以写入数据。
w+:读写模式。如果文件存在,会覆盖文件内容;如果文件不存在,会创建新文件。
a+:读写模式。文件存在时,数据会追加到文件末尾;如果文件不存在,会创建新文件。
rb+:二进制读写模式。
(2)打开文件并使用模式
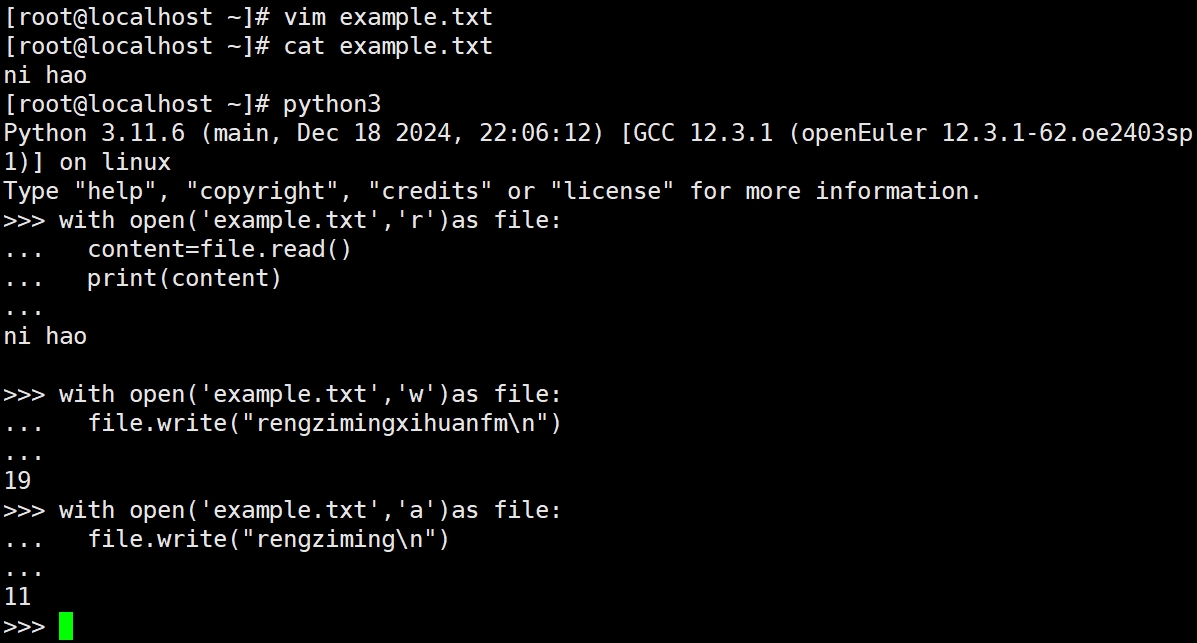
4.1.2读取文件
Python中的文件读取功能非常强大。以下是几种常见的读取方式:
(1)read()方法
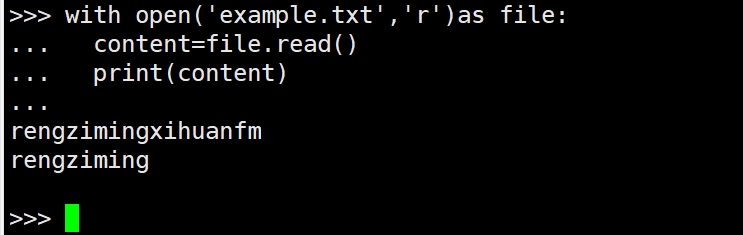
(2)readline()方法
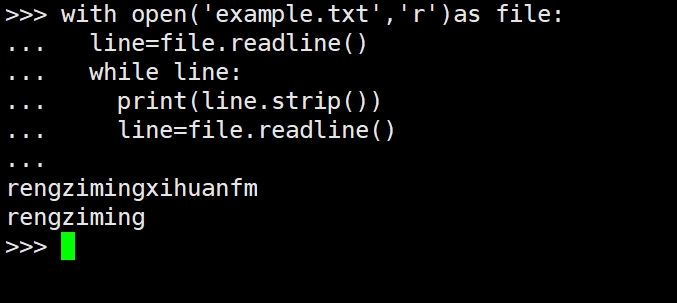
(3)readlines()方法
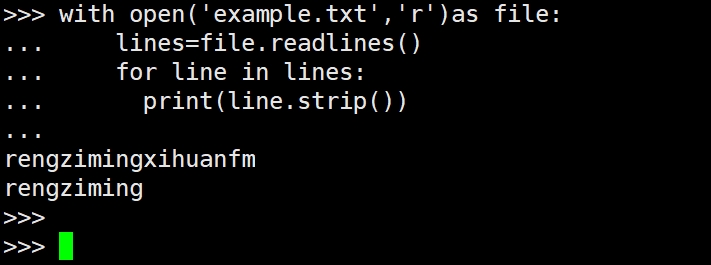
4.1.3写入文件
Python提供了几种方法将数据写入文件。写入操作常用于日志记录,数据导出等场景。
(1)使用write()方法写入文件
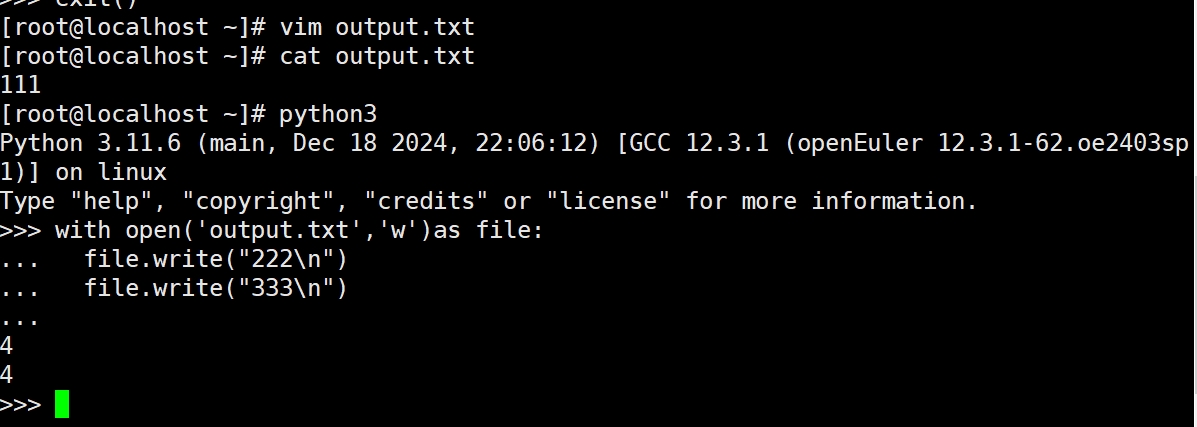
(2)使用writelines()方法写入多行数据

5.1错误处理与异常捕获
在进行 Web 请求时,可能会发生各种错误,例如网络超时、服务器错误等。requests 库通过异常处理机制帮助我们捕获这些错误。Python 的 try 语句能够捕获和处理代码块中的异常,从而避免程序崩溃,并且提供了处理错误的机会。
5.1.1:try 语句的使用
try 语句用于捕获和处理异常,它由三部分组成:
try 块:包含可能会引发异常的代码。当代码运行过程中发生错误时,程序会跳到相应的 except 块进行处理。
except 块:当 try 块中的代码出现异常时,程序会跳转到 except 块执行。在 except 中可以指定要捕获的异常类型,如 Timeout、HTTPError 等。
else 块(可选):如果 try 块中的代码没有抛出异常,则会执行 else 块中的代码。
finally块(可选):无论是否发生异常,finally块中的代码都会执行,通常用于清理资源等。
5.1.2捕获常见异常

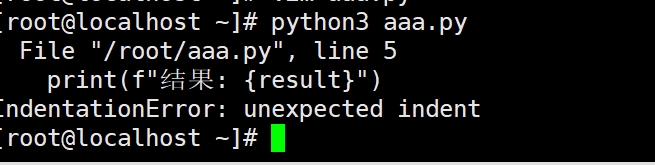


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

