项目网址(具体描述):
https://www.kaggle.com/competitions/playground-series-s4e2
(一)数据导入与预览
import time
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pylab as plt
from scipy.stats import mode
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import StratifiedKFold
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train.head()
| id | Gender | Age | Height | Weight | family_history_with_overweight | FAVC | FCVC | NCP | CAEC | SMOKE | CH2O | SCC | FAF | TUE | CALC | MTRANS | NObeyesdad | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Male | 24.443011 | 1.699998 | 81.669950 | yes | yes | 2.000000 | 2.983297 | Sometimes | no | 2.763573 | no | 0.000000 | 0.976473 | Sometimes | Public_Transportation | Overweight_Level_II |
| 1 | 1 | Female | 18.000000 | 1.560000 | 57.000000 | yes | yes | 2.000000 | 3.000000 | Frequently | no | 2.000000 | no | 1.000000 | 1.000000 | no | Automobile | Normal_Weight |
| 2 | 2 | Female | 18.000000 | 1.711460 | 50.165754 | yes | yes | 1.880534 | 1.411685 | Sometimes | no | 1.910378 | no | 0.866045 | 1.673584 | no | Public_Transportation | Insufficient_Weight |
| 3 | 3 | Female | 20.952737 | 1.710730 | 131.274851 | yes | yes | 3.000000 | 3.000000 | Sometimes | no | 1.674061 | no | 1.467863 | 0.780199 | Sometimes | Public_Transportation | Obesity_Type_III |
| 4 | 4 | Male | 31.641081 | 1.914186 | 93.798055 | yes | yes | 2.679664 | 1.971472 | Sometimes | no | 1.979848 | no | 1.967973 | 0.931721 | Sometimes | Public_Transportation | Overweight_Level_II |
目标变量:NObeyesdad
(二)数据预处理
缺失值检验、重复值检验:
test.isnull().sum()
id 0
Gender 0
Age 0
Height 0
Weight 0
family_history_with_overweight 0
FAVC 0
FCVC 0
NCP 0
CAEC 0
SMOKE 0
CH2O 0
SCC 0
FAF 0
TUE 0
CALC 0
MTRANS 0
dtype: int64
train.duplicated().sum()
0
train.isnull().sum()
id 0
Gender 0
Age 0
Height 0
Weight 0
family_history_with_overweight 0
FAVC 0
FCVC 0
NCP 0
CAEC 0
SMOKE 0
CH2O 0
SCC 0
FAF 0
TUE 0
CALC 0
MTRANS 0
NObeyesdad 0
dtype: int64
整体预览:
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20758 entries, 0 to 20757
Data columns (total 18 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 id 20758 non-null int64 1 Gender 20758 non-null object 2 Age 20758 non-null float643 Height 20758 non-null float644 Weight 20758 non-null float645 family_history_with_overweight 20758 non-null object 6 FAVC 20758 non-null object 7 FCVC 20758 non-null float648 NCP 20758 non-null float649 CAEC 20758 non-null object 10 SMOKE 20758 non-null object 11 CH2O 20758 non-null float6412 SCC 20758 non-null object 13 FAF 20758 non-null float6414 TUE 20758 non-null float6415 CALC 20758 non-null object 16 MTRANS 20758 non-null object 17 NObeyesdad 20758 non-null object
dtypes: float64(8), int64(1), object(9)
memory usage: 2.9+ MB
(三)EDA
特征分类(数值型、类别型):
cats = train.select_dtypes('object').columns.tolist()
nums = train.select_dtypes('float').columns.tolist()
绘制分布图,可以直观发现数据的模式和异常,加深对数据的熟悉程度,也是为特征工程做准备,比如需要处理哪些特征:
plt.figure(figsize=(15, 10))
for i, col in enumerate(cats, 1): ax = plt.subplot(len(cats)//3+1, 3, i)sns.histplot(train[col], ax=ax)ax.tick_params(axis='x', rotation=30)ax.set_title(col, color='r')plt.tight_layout()
plt.show()

plt.figure(figsize=(15, 10))
for i, col in enumerate(nums, 1): ax = plt.subplot(len(nums)//3+1, 3, i)sns.histplot(train[col], ax=ax)ax.set_title(col, color='r')plt.tight_layout()
plt.show()

(四)特征工程
def feature_job(df): # 二分类特征编码for col in ['family_history_with_overweight', 'FAVC', 'SMOKE', 'SCC']: df[col] = df[col].map({'yes': 1, 'no': 0}).astype(int)df['Gender'] = df['Gender'].map({'Male': 1, 'Female': 0}).astype(int)# 有序多类别编码 for col in ['CAEC', 'CALC']:df[col] = df[col].map({'Sometimes': 1, 'Frequently': 2, 'no': 0, 'Always':3}).astype(int)# 无序多类别编码 - 独热编码df = pd.get_dummies(df, columns=['MTRANS'])# 数值型特征处理df['Age'] = df['Age'].apply(lambda x: x/20 + 1).astype(int)df['Height'] = pd.cut(df['Height'], bins=[0, 1.5, 1.6, 1.7, 1.8, 1.9, 2.5], labels=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6]).astype(float)df['Weight'] = pd.cut(df['Weight'], bins=[0, 40, 60, 80, 100, 120, 140, 160, 200], labels=[w/10 for w in range(1,9)]).astype(float)return df train = feature_job(train)
test = feature_job(test)
train.sample(3)
| id | Gender | Age | Height | Weight | family_history_with_overweight | FAVC | FCVC | NCP | CAEC | SMOKE | CH2O | SCC | FAF | TUE | CALC | NObeyesdad | MTRANS_Automobile | MTRANS_Bike | MTRANS_Motorbike | MTRANS_Public_Transportation | MTRANS_Walking | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5118 | 5118 | 0 | 3 | 0.2 | 0.4 | 1 | 1 | 2.020502 | 1.0 | 1 | 0 | 1.972551 | 0 | 1.926381 | 0.000000 | 0 | Obesity_Type_I | True | False | False | False | False |
| 19376 | 19376 | 0 | 2 | 0.3 | 0.5 | 1 | 1 | 3.000000 | 3.0 | 1 | 0 | 2.094901 | 0 | 0.067329 | 0.599441 | 1 | Obesity_Type_III | False | False | False | True | False |
| 6189 | 6189 | 0 | 2 | 0.2 | 0.2 | 1 | 1 | 2.000000 | 1.0 | 1 | 0 | 2.000000 | 0 | 1.000000 | 1.000000 | 1 | Normal_Weight | False | False | False | True | False |
建模前的数据处理:划分数据,并对目标进行标签编码,由于准备使用逻辑回归模型和SVM模型,而模型又对特征尺度敏感,所以又对特征进行了标准化处理:
X = train.drop(columns=['NObeyesdad', 'id'])
y= train['NObeyesdad']
# 目标 - 标签编码
label_enc = LabelEncoder()
y_enc = label_enc.fit_transform(y)
# 特征 - 标准化
scaler = StandardScaler()
X_scaler = scaler.fit_transform(X)
test_scaler = scaler.transform(test.drop(columns='id'))
(五)模型构建与预测
项目要求的模型评价指标: Accuracy - 准确率
模型一:逻辑回归模型
方法:5折交叉验证 + L1正则项
参数调节:简单测试了不同的参数,发现模型效果不好,所以没有进行过多参数调节。
n_folds = 5
accu_valids = [] # 存储每个 fold 的准确率start = time.time()
folds = StratifiedKFold(n_splits=n_folds, random_state=42, shuffle=True)
for fold, (train_idx, valid_idx) in enumerate(folds.split(X_scaler, y_enc)):X_train, y_train = X_scaler[train_idx], y_enc[train_idx]X_valid, y_valid = X_scaler[valid_idx], y_enc[valid_idx]model = LogisticRegression(class_weight='balanced',penalty='l1',solver='liblinear',C=5,max_iter=5000, random_state=42)model.fit(X_train, y_train)# 验证集性能y_pred_valids = model.predict(X_valid)accu_valid = accuracy_score(y_valid, y_pred_valids)print(f'Fold {fold} accuracy: {accu_valid}')accu_valids.append(accu_valid)end = time.time()
print(f'\nTime cost: {end-start: .3f} Seconds')
print(f'Avg accurary: {np.mean(accu_valids): .4f}')
结果输出:
Fold 0 accuracy: 0.7215799614643545
Fold 1 accuracy: 0.7124277456647399
Fold 2 accuracy: 0.7297687861271677
Fold 3 accuracy: 0.7087448807516261
Fold 4 accuracy: 0.7154902433148639Time cost: 5.921 Seconds
Avg accurary: 0.7176
评价:准确率只有0.7左右,效果很差,先试试其他模型,如果也很差,就是数据预处理和特征工程出现问题。
模型二:SVM
方法:5折交叉验证
参数调节:也是简单测试几个不同的参数,不进行复杂调参,而且SVM效率很慢(对当前数据集),训练时间长,可以优先考虑其他模型
说明:选择使用svm是因为想练习一下该模型,其实可以选择自己喜欢的模型,比如树模型等。
n_folds = 5
accu_valids = []start = time.time()
folds = StratifiedKFold(n_splits=n_folds, random_state=42, shuffle=True)
for fold, (train_idx, valid_idx) in enumerate(folds.split(X_scaler, y_enc)):X_train, y_train = X_scaler[train_idx], y_enc[train_idx]X_valid, y_valid = X_scaler[valid_idx], y_enc[valid_idx]model = SVC(class_weight='balanced',kernel='rbf', max_iter=6000,random_state=42)model.fit(X_train, y_train)# 验证集性能y_pred_valids = model.predict(X_valid)accu_valid = accuracy_score(y_valid, y_pred_valids)print(f'Fold {fold} accuracy: {accu_valid}')accu_valids.append(accu_valid)end = time.time()
print(f'\nTime cost: {end-start: .3f} Seconds')
print(f'Avg accuracy: {np.mean(accu_valids):.4f}')
Fold 0 accuracy: 0.7952793834296724
Fold 1 accuracy: 0.7776974951830443
Fold 2 accuracy: 0.799373795761079
Fold 3 accuracy: 0.7949891592387377
Fold 4 accuracy: 0.7865574560346904Time cost: 30.196 Seconds
Avg accuracy: 0.7908
评价:效果提升了不少,有0.79左右,接下来我选择使用CatBoost模型(因为是我个人比较喜欢的模型,最终我也是采用了CatBoost模型)
模型三:CatBoost模型
方法:5折交叉验证 + L2正则项 + 早停 + GPU加速
参数调节:简单测试了不同的参数取值,如学习率、正则化强度
import time
import optuna
from catboost import Pool, CatBoostClassifier
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pylab as plt
from scipy.stats import mode
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import accuracy_score, confusion_matrix
cat_features = X.select_dtypes('object').columns.tolist()n_fold = 5
folds = StratifiedKFold(n_splits=n_fold, random_state=42, shuffle=True)
accu_valids = [] # 储存每个 fold 的 AUC
y_pred = np.empty((n_fold, len(test))) # 存储每个fold的test预测值start = time.time()
for fold, (train_index, valid_index) in enumerate(folds.split(X, y_enc)): # 训练集X_train, y_train = X.iloc[train_index], y_enc[train_index]# 测试集X_vilid, y_vilid = X.iloc[valid_index], y_enc[valid_index]# 模型训练train_pool = Pool(X_train, y_train, cat_features=cat_features)valid_pool = Pool(X_vilid, y_vilid, cat_features=cat_features)clf = CatBoostClassifier(eval_metric='Accuracy',task_type='GPU', learning_rate=0.2, l2_leaf_reg=5,iterations=1000, early_stopping_rounds=100, verbose=200)clf.fit(train_pool, eval_set=valid_pool)# 验证集测试y_pred_valid = clf.predict(X_vilid)accu_valid = accuracy_score(y_vilid, y_pred_valid)print(f'Fold {fold} accurary: {accu_valid}')accu_valids.append(accu_valid)# 整个测试集性能y_pred[fold, :] = clf.predict(test)[: , 0]print('-' * 60)end = time.time()
print(f'\nTime cost: {end-start: .3f} Seconds')
print(f'Avg accurary: {np.mean(accu_valids): .4f}')
结果输出:
0: learn: 0.6945080 test: 0.6958092 best: 0.6958092 (0) total: 8.9ms remaining: 8.89s
200: learn: 0.8775142 test: 0.8338150 best: 0.8345376 (113) total: 1.31s remaining: 5.23s
bestTest = 0.8345375723
bestIteration = 113
Shrink model to first 114 iterations.
Fold 0 accurary: 0.8345375722543352
------------------------------------------------------------
0: learn: 0.6959533 test: 0.6900289 best: 0.6900289 (0) total: 7.07ms remaining: 7.06s
200: learn: 0.8749849 test: 0.8400771 best: 0.8415222 (198) total: 1.34s remaining: 5.31s
bestTest = 0.8427263969
bestIteration = 277
Shrink model to first 278 iterations.
Fold 1 accurary: 0.8427263969171483
------------------------------------------------------------
0: learn: 0.7006504 test: 0.6912331 best: 0.6912331 (0) total: 9.46ms remaining: 9.46s
200: learn: 0.8717933 test: 0.8458574 best: 0.8458574 (200) total: 1.33s remaining: 5.31s
bestTest = 0.8458574181
bestIteration = 200
Shrink model to first 201 iterations.
Fold 2 accurary: 0.8458574181117534
------------------------------------------------------------
0: learn: 0.6952490 test: 0.6928451 best: 0.6928451 (0) total: 7.58ms remaining: 7.57s
200: learn: 0.8737882 test: 0.8376295 best: 0.8388340 (188) total: 1.31s remaining: 5.21s
bestTest = 0.8397976391
bestIteration = 235
Shrink model to first 236 iterations.
Fold 3 accurary: 0.8397976391231029
------------------------------------------------------------
0: learn: 0.6989221 test: 0.6979041 best: 0.6979041 (0) total: 6.9ms remaining: 6.89s
200: learn: 0.8748118 test: 0.8308841 best: 0.8344977 (171) total: 1.3s remaining: 5.19s
bestTest = 0.8344977114
bestIteration = 171
Shrink model to first 172 iterations.
Fold 4 accurary: 0.8344977113948446
------------------------------------------------------------Time cost: 11.381 Seconds
Avg accurary: 0.8395
评价:效果又提升了不少,准确率突破了0.80,但是无论我后续我怎么调节参数,准确率都在 0.8~0.85 之间,没有得到明显提升。
后续策略:不浪费太多时间在调参上(当前特征不足以拟合出优秀的模型),而是将重心转向特征工程,优化特征工程策略。
(六)优化过程
优化内容:特征工程
策略:尝试构造更多新特征
- BMI(体质指数)
- Is_Obese:依据BMI,BMI>30,则肥胖
- Family_FAVC特征交互:家族肥胖 + 高热量饮食
- Health_Score综合评分:蔬菜摄入 + 运动频率 + 饮水
def feature_job(df): # 构造新特征 df['BMI'] = df['Weight'] / (df['Height']) ** 2df['Is_Obese'] = df['BMI'].apply(lambda x: 1 if x >= 30 else 0)df['Family_FAVC'] = df['family_history_with_overweight'].astype(str) + '_' + df['FAVC'].astype(str)df['Health_Score'] = df['FCVC'] + df['FAF'] + df['CH2O'] # 二分类特征编码for col in ['family_history_with_overweight', 'FAVC', 'SMOKE', 'SCC']: df[col] = df[col].map({'yes': 1, 'no': 0}).astype(int)df['Gender'] = df['Gender'].map({'Male': 1, 'Female': 0}).astype(int)# 有序多类别编码 for col in ['CAEC', 'CALC']:df[col] = df[col].map({'Sometimes': 1, 'Frequently': 2, 'no': 0, 'Always':3}).astype(int)# 无序多类别编码 - 独热编码df = pd.get_dummies(df, columns=['MTRANS', 'Family_FAVC'] ) # 数值型特征处理df['Age'] = df['Age'].apply(lambda x: x/20 + 1).astype(int)df['Height'] = pd.cut(df['Height'], bins=[0, 1.5, 1.6, 1.7, 1.8, 1.9, 2.5], labels=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6]).astype(float)df['Weight'] = pd.cut(df['Weight'], bins=[0, 40, 60, 80, 100, 120, 140, 160, 200], labels=[w/10 for w in range(1,9)]).astype(float)return df train = feature_job(train)
test = feature_job(test)
应用到CatBoost模型,输出如下:
cat_features = X.select_dtypes('object').columns.tolist()n_fold = 5
folds = StratifiedKFold(n_splits=n_fold, random_state=42, shuffle=True)
accu_valids = [] # 储存每个 fold 的 AUC
y_pred = np.empty((n_fold, len(test))) # 存储每个fold的test预测值start = time.time()
for fold, (train_index, valid_index) in enumerate(folds.split(X, y_enc)): # 训练集X_train, y_train = X.iloc[train_index], y_enc[train_index]# 测试集X_vilid, y_vilid = X.iloc[valid_index], y_enc[valid_index]# 模型训练train_pool = Pool(X_train, y_train, cat_features=cat_features)valid_pool = Pool(X_vilid, y_vilid, cat_features=cat_features)clf = CatBoostClassifier(eval_metric='Accuracy',task_type='GPU', learning_rate=0.2, l2_leaf_reg=5,iterations=1000, early_stopping_rounds=100, verbose=200)clf.fit(train_pool, eval_set=valid_pool)# 验证集测试y_pred_valid = clf.predict(X_vilid)accu_valid = accuracy_score(y_vilid, y_pred_valid)print(f'Fold {fold} accurary: {accu_valid}')accu_valids.append(accu_valid)# 整个测试集性能y_pred[fold, :] = clf.predict(test)[: , 0]print('-' * 60)end = time.time()
print(f'\nTime cost: {end-start: .3f} Seconds')
print(f'Avg accurary: {np.mean(accu_valids): .4f}')
(原代码基础上,加入了测试集的folds预测,用于kaggle上提交结果)
输出结果:
0: learn: 0.7897146 test: 0.7998555 best: 0.7998555 (0) total: 7.28ms remaining: 7.27s
200: learn: 0.9151512 test: 0.8947495 best: 0.8964355 (196) total: 1.33s remaining: 5.28s
bestTest = 0.8973988439
bestIteration = 270
Shrink model to first 271 iterations.
Fold 0 accurary: 0.8973988439306358
------------------------------------------------------------
0: learn: 0.7934482 test: 0.7887765 best: 0.7887765 (0) total: 8.24ms remaining: 8.23s
200: learn: 0.9193063 test: 0.8872832 best: 0.8892100 (119) total: 1.31s remaining: 5.23s
bestTest = 0.8892100193
bestIteration = 119
Shrink model to first 120 iterations.
Fold 1 accurary: 0.8892100192678227
------------------------------------------------------------
0: learn: 0.7923642 test: 0.7885356 best: 0.7885356 (0) total: 6.13ms remaining: 6.13s
200: learn: 0.9166566 test: 0.8928227 best: 0.8935453 (192) total: 1.33s remaining: 5.27s
400: learn: 0.9359870 test: 0.8964355 best: 0.8964355 (400) total: 2.63s remaining: 3.93s
bestTest = 0.8964354528
bestIteration = 400
Shrink model to first 401 iterations.
Fold 2 accurary: 0.8964354527938343
------------------------------------------------------------
0: learn: 0.7939423 test: 0.7836666 best: 0.7836666 (0) total: 6.63ms remaining: 6.63s
200: learn: 0.9188896 test: 0.8855697 best: 0.8867743 (169) total: 1.3s remaining: 5.19s
bestTest = 0.8874969887
bestIteration = 234
Shrink model to first 235 iterations.
Fold 3 accurary: 0.8874969886774271
------------------------------------------------------------
0: learn: 0.7917143 test: 0.7964346 best: 0.7964346 (0) total: 6.79ms remaining: 6.79s
200: learn: 0.9197326 test: 0.8879788 best: 0.8899060 (145) total: 1.33s remaining: 5.3s
bestTest = 0.8899060467
bestIteration = 145
Shrink model to first 146 iterations.
Fold 4 accurary: 0.8899060467357264
------------------------------------------------------------Time cost: 12.632 Seconds
Avg accurary: 0.8921
评价:不需要太复杂的调参,模型效果就得到了很大的提升,准确率提升到了0.892,模型效果很好了。
(七)结果保存
# 最终预测结果
y_pred_final = mode(y_pred, axis=0)[0].astype(int)
print(f'Test final prediction: {y_pred_final}')
Test final prediction: [3 5 4 ... 0 1 3]
将结果保存到csv文件, 用于kaggle上提交:
submission = pd.DataFrame({'id': test_id, 'NObeyesdad': le.inverse_transform(y_pred_final)
})
submission.to_csv('submission.csv', index=False)
kaggle上的最终评分(目前排行榜最高分,私人数据集0.91157,公共数据集0.92341):
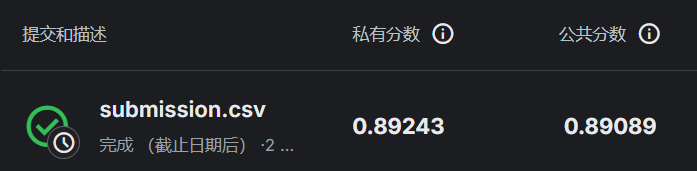
说明:当然后续还可以继续进行优化,使得分数去到0.9以上。
# 如果大家有更好的策略,欢迎一起探讨啊
# 文章到此就结束了,我们下期再见叭!






