目录
一、NS-SWIFT简介
二、Qwen3简介
三、微调Qwen3
1、安装NS-SWIFT环境
2、准备训练数据
3、Lora微调
4、GROP训练
5、Megatron并行训练
一、NS-SWIFT简介
SWIFT(Scalable lightWeight Infrastructure for Fine-Tuning)是魔搭ModelScope开源社区推出的一套完整的轻量级训练、推理、评估和部署工具,支持200+大模型、15+多模态大模型以及10+轻量化Tuners,让AI爱好者能够使用自己的消费级显卡玩转大模型和AIGC。
SWIFT 框架主要特征特性:
- 具备SOTA特性的Efficient Tuners:用于结合大模型实现轻量级(在商业级显卡上,如RTX3080、RTX3090、RTX4090等)训练和推理,并取得较好效果
- 使用ModelScope Hub的Trainer:基于transformers trainer提供,支持LLM模型的训练,并支持将训练后的模型上传到ModelScope Hub中
- 可运行的模型Examples:针对热门大模型提供的训练脚本和推理脚本,并针对热门开源数据集提供了预处理逻辑,可直接运行使用
- 支持界面化训练和推理
二、Qwen3简介
Qwen3 是 Qwen 系列最新一代的大型语言模型,提供了一套全面的密集型和专家混合(MoE)模型。基于广泛的训练,Qwen3 在推理、指令遵循、代理能力和多语言支持方面实现了突破性的进展。
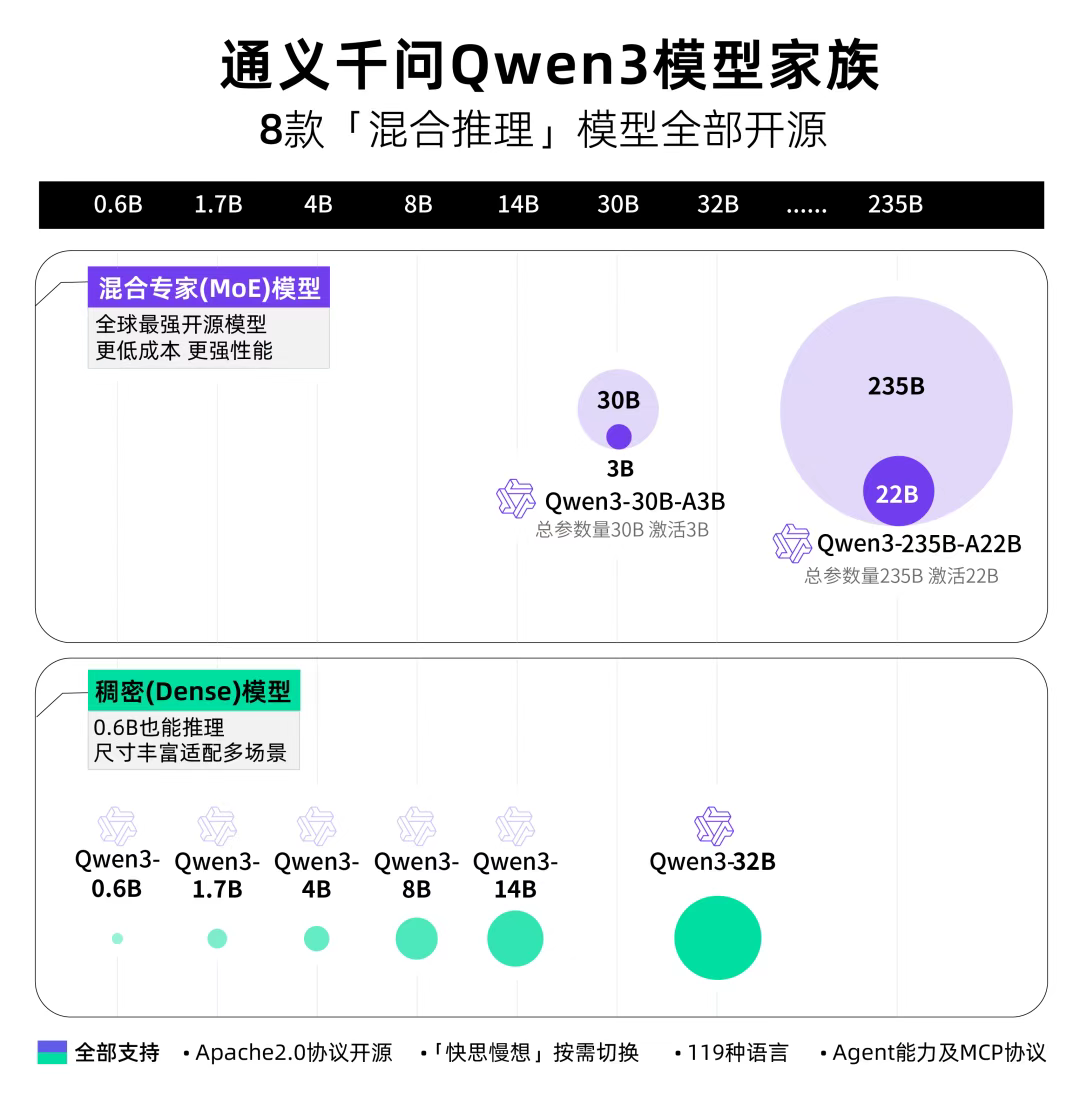
- 旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,与一众顶级模型(DeepSeek-R1、OpenAI-o1、OpenAI-o3-mini、Grok-3 和 Gemini-2.5-Pro)相比,表现出极具竞争力的结果。
- 小型MoE模型Qwen3-30B-A3B的激活参数数量是QwQ-32B 10%,表现更胜一筹。Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
核心亮点:
- 多种思考模式:Qwen3 模型支持思考模式、非思考模式两种思考模式(可以通过在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式)。
- 多语言:Qwen3 模型支持 119 种语言和方言。这一广泛的多语言能力为国际应用开辟了新的可能性,让全球用户都能受益于这些模型的强大功能。
- 增强的 Agent 能力:Qwen3 为即将到来的智能体 Agent 和大模型应用爆发提供了更好的支持。团队优化了 Qwen3 模型的编码和 Agent 能力,并增强了对 MCP 的支持。
三、微调Qwen3
1、安装NS-SWIFT环境
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .pip install liger-kernel transformers -U
2、准备训练数据
- 微调数据集
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "<think>\nxxx\n</think>\n\n浙江的省会在杭州。"}]}
- GRPO训练数据集
# llm
{"messages": [{"role": "system", "content": "You are a useful and harmless assistant"}, {"role": "user", "content": "Tell me tomorrow's weather"}]}
{"messages": [{"role": "system", "content": "You are a useful and harmless math calculator"}, {"role": "user", "content": "What is 1 + 1?"}, {"role": "assistant", "content": "It equals 2"}, {"role": "user", "content": "What about adding 1?"}]}
{"messages": [{"role": "user", "content": "What is your name?"}]}# mllm
{"messages": [{"role": "user", "content": "<image>What is the difference between the two images?"}], "images": ["/xxx/x.jpg"]}
{"messages": [{"role": "user", "content": "<image><image>What is the difference between the two images?"}], "images": ["/xxx/y.jpg", "/xxx/z.png"]}
数据集整理具体可参考官方网站:自定义数据集 — swift 3.4.0.dev0 文档
3、Lora微调
# 训练显存:22GB
# 你可以指定`--dataset AI-ModelScope/alpaca-gpt4-data-zh`来跑通实验
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen3-8B \
--train_type lora \
--dataset '<dataset-path>' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 4 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--packing true \
--user_liger_kernel true
4、GROP训练
# 70G*8
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
NPROC_PER_NODE=8 \
swift rlhf \
--rlhf_type grpo \
--model Qwen/Qwen3-8B \
--train_type full \
--dataset AI-MO/NuminaMath-TIR \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--learning_rate 1e-6 \
--save_total_limit 2 \
--logging_steps 5 \
--output_dir output \
--gradient_accumulation_steps 1 \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--max_completion_length 4096 \
--vllm_max_model_len 8192 \
--reward_funcs accuracy \
--num_generations 16 \
--use_vllm true \
--vllm_gpu_memory_utilization 0.4 \
--sleep_level 1 \
--offload_model true \
--offload_optimizer true \
--gc_collect_after_offload true \
--deepspeed zero3 \
--num_infer_workers 8 \
--tensor_parallel_size 1 \
--temperature 1.0 \
--top_p 0.85 \
--report_to wandb \
--log_completions true \
--overlong_filter true
GROP训练详细使用请参考官方文档:GRPO — swift 3.4.0.dev0 文档
5、Megatron并行训练
SWIFT引入了Megatron的并行技术来加速大模型的训练,包括数据并行、张量并行、流水线并行、序列并行,上下文并行,专家并行。支持Qwen3、Qwen3-MoE、Qwen2.5、Llama3、Deepseek-R1蒸馏系等模型的预训练和微调。
# https://help.aliyun.com/zh/pai/user-guide/general-environment-variables
# 请确保两个节点的保存权重路径相同
NNODES=$WORLD_SIZE \
NODE_RANK=$RANK \
megatron sft \
--load Qwen3-30B-A3B-Base-mcore \
--dataset 'liucong/Chinese-DeepSeek-R1-Distill-data-110k-SFT' \
--tensor_model_parallel_size 2 \
--expert_model_parallel_size 8 \
--moe_grouped_gemm true \
--moe_shared_expert_overlap true \
--moe_aux_loss_coeff 0.01 \
--micro_batch_size 1 \
--global_batch_size 16 \
--packing true \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 1 \
--train_iters 2000 \
--eval_iters 50 \
--finetune true \
--cross_entropy_loss_fusion true \
--lr 1e-5 \
--lr_warmup_iters 100 \
--min_lr 1e-6 \
--save megatron_output/Qwen3-30B-A3B-Base \
--eval_interval 200 \
--save_interval 200 \
--max_length 8192 \
--num_workers 8 \
--dataset_num_proc 8 \
--no_save_optim true \
--no_save_rng true \
--sequence_parallel true \
--use_flash_attn true
Megatron训练详细使用请参考官方文档:Megatron-SWIFT训练 — swift 3.4.0.dev0 文档






