题目:
使用爬虫采集详情数据根据返回的数据进行求和提交答案
思路:
没有什么校验参数,根据借口获取就可以了
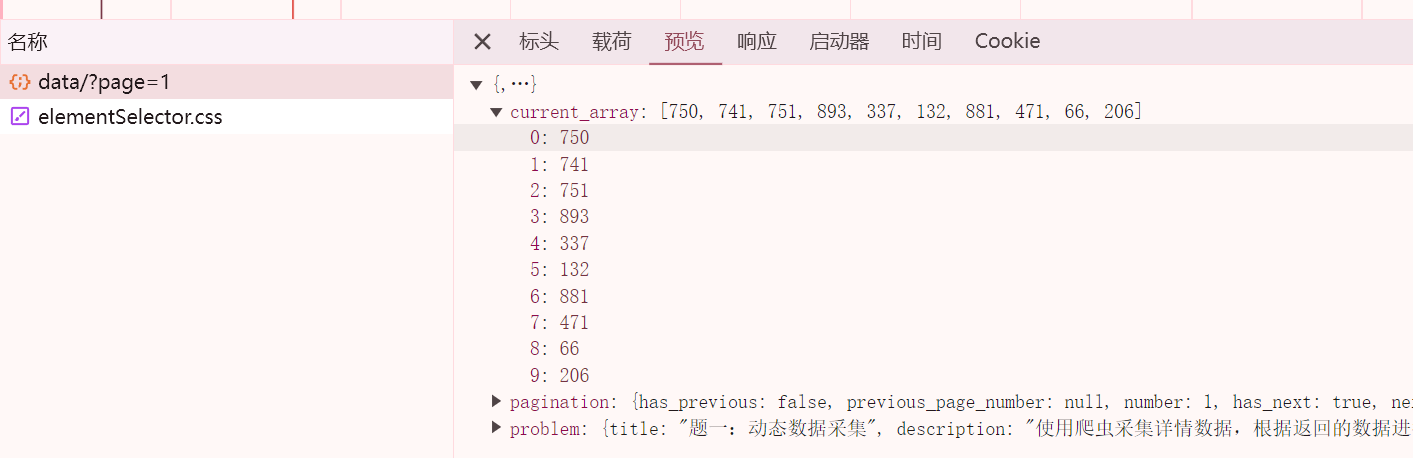
直接动手尝试,因为网站要登陆的,所以header要加cookie值
import requests
url = "https://stu.tulingpyton.cn/api/problem-detail/1/data/"
headers = {'cookie' : '替换自己的'}
response = requests.get(url,headers=headers).json()['current_array']
print(response)打印输出:

对此优化一下整体:
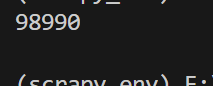
import requestsdef request_page(cookie, page):url = "https://stu.tulingpyton.cn/api/problem-detail/1/data/"headers = {"cookie": f'{cookie}',}parms = {"page": f"{page}"}return requests.get(url, headers=headers, params=parms).json()['current_array']if __name__ == '__main__':cookie = '替换自己的cookie'num = 0for i in range(1, 21):num += sum(request_page(cookie, i))print(num)输出结果:


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

