最近用了一下RPA软件,挑了影刀,发现很无脑也很简单,其语法大概是JAVA和PYTHON的混合体,如果懂爬虫的话,学这个软件就快的很,看了一下官方的教程,对于有基础的人来说很有点枯燥,但又不得不看,毕竟要按照RPA的思路操作就必须懂他们的设计思路;
优点:对于不是特别复杂的需求,很快能上手,相信大部分人爬电商数据,不涉及到点进详情页抓各种信息,只抓搜索结果页面,就很简单;
缺点:复杂的需求,例如抓详情页信息,抓不规律的网站,就很麻烦,尝试过手动定位节点,软件还是难以识别,能手动正则\XPATH定位的人,基本也懂爬虫,当然像淘宝这种详情页信息,本身就不简单,这也怪不得软件;
例如抓淘宝的数据,如果是爬虫,基本要用SELENIUM,会涉及到登录验证,翻页和控制速度,要考虑的事情会比较多,也不能速度太快;
一、基本信息爬取和讲解
但用RPA就十分简单;
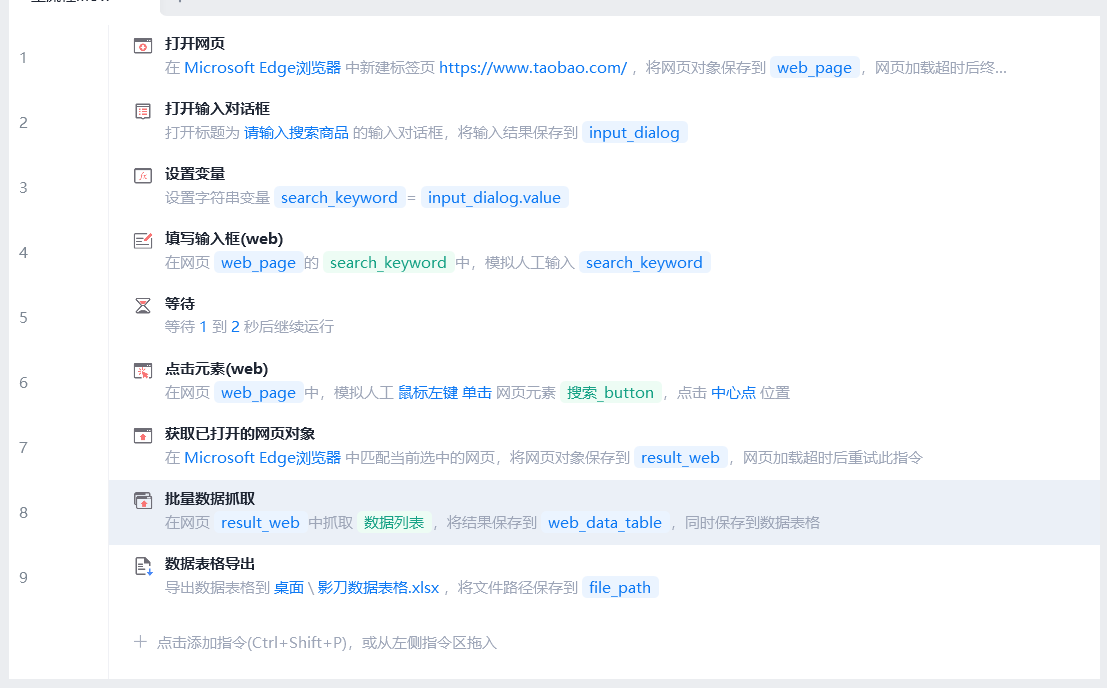
仅需要这几个步骤即可:
1.打开网页,以EDGE为例,并不是用的爬虫常用的EdgeDriver的控制软件,而是类似的,直接打开网页,会用保存的Cookies,所以自己有账号的话,并不需要登录;
2.有时登录后会碰到广告,理论上要把iframe信息点个X,但实测,这广告会马上自动消失;此时我们在RPA软件自带的弹窗中,输入关键词;
3.将关键词,保存为一个变量;
4.将变量输入到淘宝的搜索栏;
5.随机等1到2秒;
6.点搜索
7.搜索结果会弹出一个新网页标签,这一步获取已打开的网页对象,类似于selenium的这个操作;
driver.switch_to.window(driver.window_handles[-1]) 8.批量抓取数据,这一步,将标题、价格、店铺、销量、宣传tag等东西都抓到,再定位下一页的位置,会自动抓取一页的,当然懂爬虫的会更清晰地知道自己想要什么;
正常情况下,某宝PC端一页是48个数据,我以搜索显卡为例,抓了10页,发现每页只有46个数据,经观察,发现某宝前端经常改变;
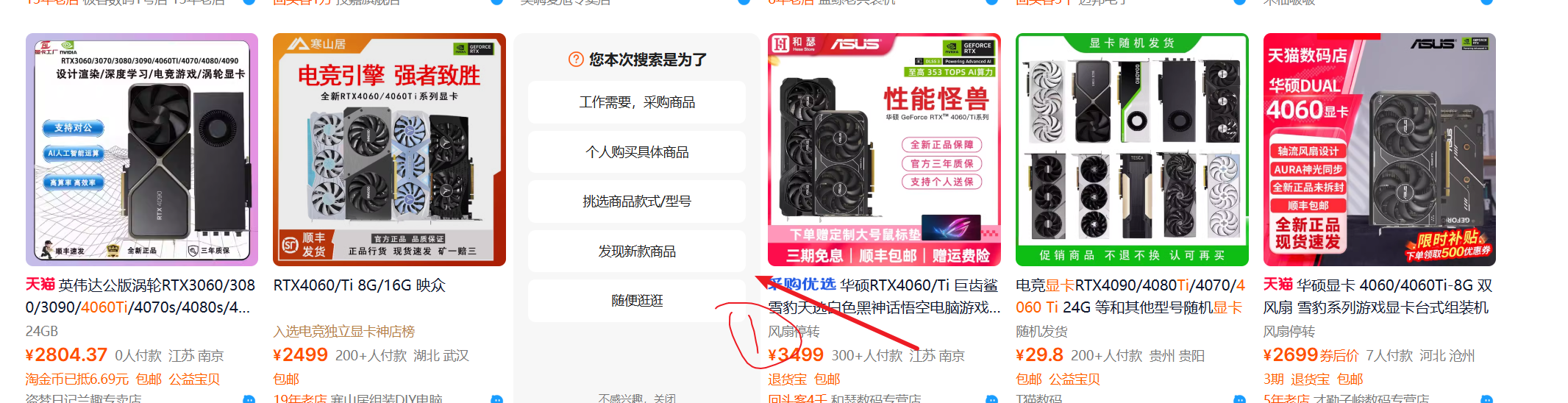
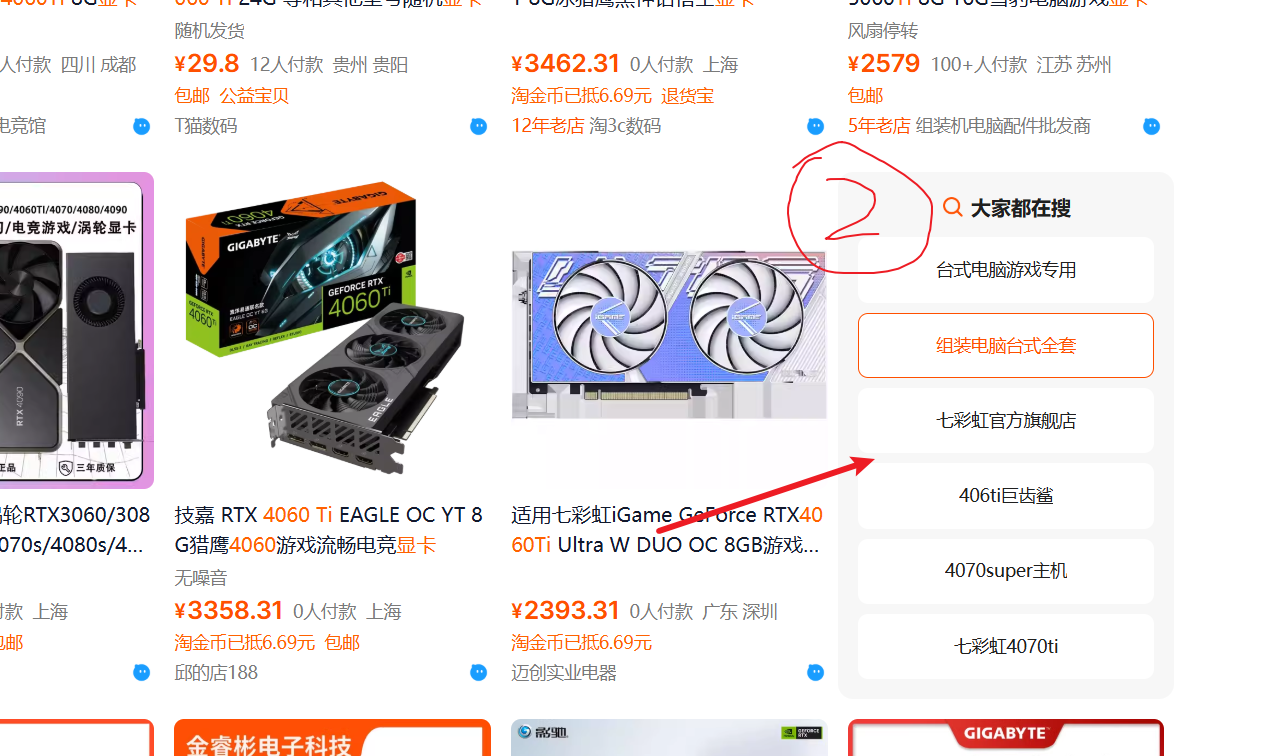
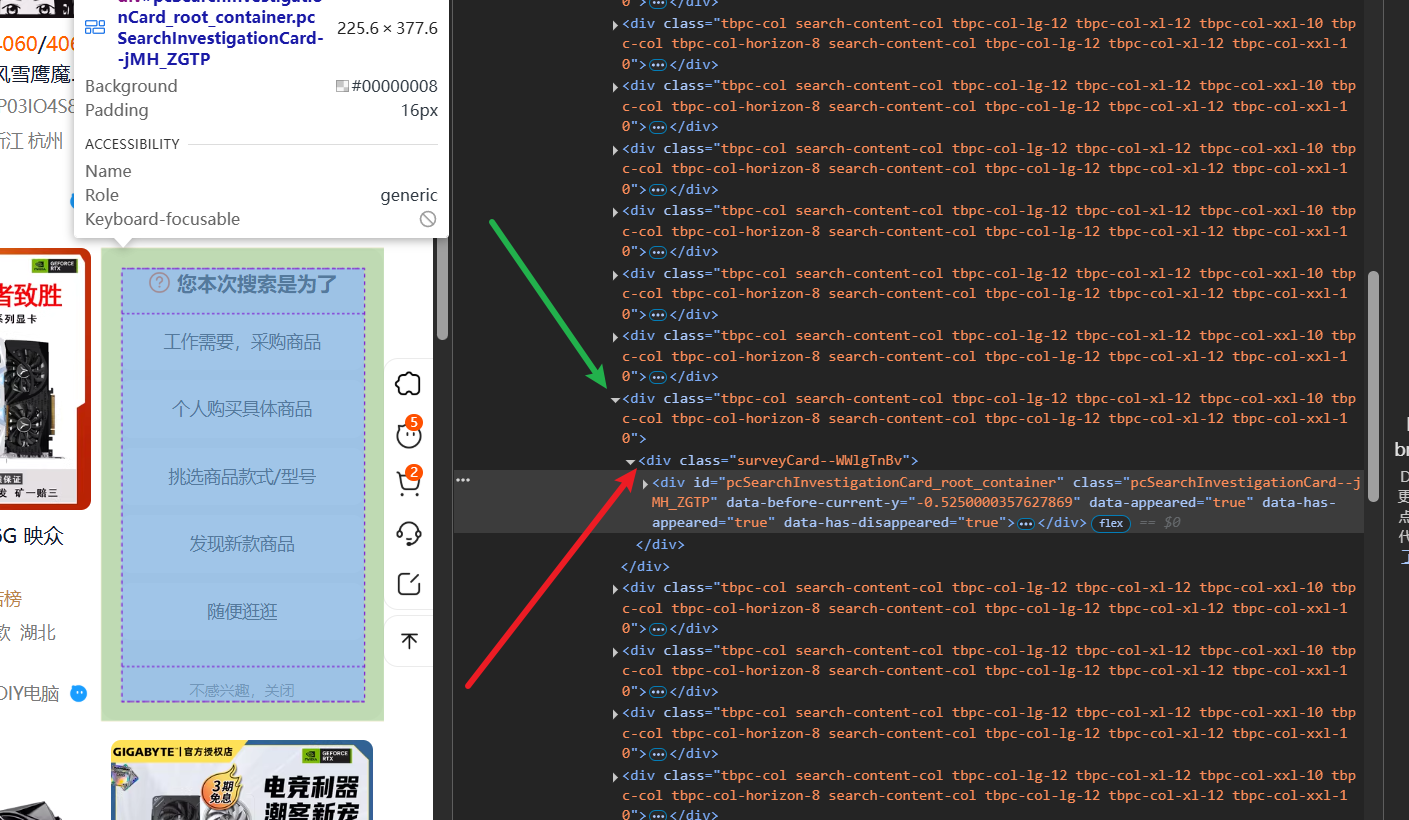
每一页都有2个这东西,如果自己写爬虫的话,经常要考虑很多情况,没想到影刀能自动剔除掉没用的数据;
看了一下elements,两个不要的东西的DIV并不相同,看来是在批量抓取数据的时候,选择哪些数据比较关键,会一些爬虫自然比较清楚怎么选;
9.最后保存到一个表格即可。
二、点进详情页
上面这一部分,我们只抓了基本信息,点进详情页的话,情况就复杂很多,那么用影刀的逻辑要大改;
我曾经就搞过详情页,后面发现太麻烦,详情页里面所需要的信息,基本就是不同SKU对应的价格,可参考
Selenium Python抓淘宝数据 基于手动登录后_python 抓包淘宝 出现登录验证-CSDN博客


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

