本节代码定义了一个 TransformerDecoderBlock 类,它是 Transformer 架构中解码器的一个基本模块。这个模块包含了多头自注意力(Multi-Head Attention)、前馈网络(Feed-Forward Network, FFN)和层归一化(Layer Normalization)。
⭐这一节代码理解即可,知道Transformer的关键组成部分:多头自注意力(Multi-Head Attention)、前馈网络(Feed-Forward Network, FFN)和层归一化(Layer Normalization),不同DecoderBlock 有不同的复现方式,本文只给出了自己的实现方式
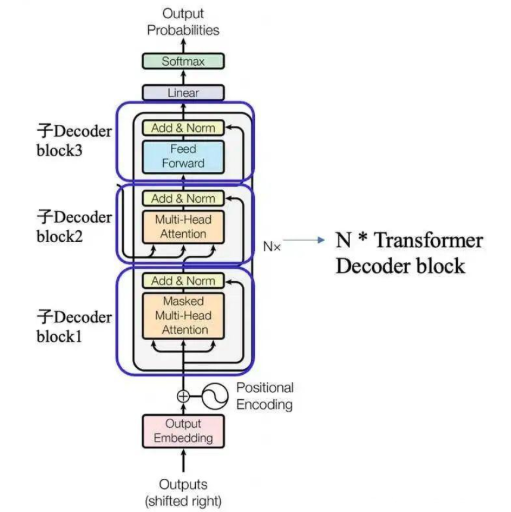
1. 初始化方法
def __init__(self, d_model, dff, dropout):super().__init__()self.linear1 = nn.Linear(d_model, dff)self.activation = nn.GELU()self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(dff, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.mha_block1 = MultiHeadAttention(d_model, num_heads, dropout)self.mha_block2 = MultiHeadAttention(d_model, num_heads, dropout)-
d_model:模型的维度,通常是嵌入维度。 -
dff:前馈网络的中间层维度。 -
dropout:Dropout 的概率。 -
num_heads:多头注意力机制中的头数(未在代码中定义,需要传入)。
2. 多头自注意力机制
self.mha_block1 = MultiHeadAttention(d_model, num_heads, dropout)
self.mha_block2 = MultiHeadAttention(d_model, num_heads, dropout)-
MultiHeadAttention是一个自定义的多头自注意力模块,通常包含查询(Q)、键(K)和值(V)的线性变换,以及多头注意力机制。 -
mha_block1和mha_block2分别表示两个多头自注意力模块。
3. 前馈网络
self.linear1 = nn.Linear(d_model, dff)
self.activation = nn.GELU()
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dff, d_model)-
前馈网络由两个线性层组成,中间使用激活函数(如 GELU 或 ReLU)和 Dropout。
-
linear1将输入从d_model映射到dff,linear2将输出从dff映射回d_model。
4. 层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)-
层归一化用于稳定训练过程,减少内部协变量偏移。
5. Dropout
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)-
Dropout 用于防止过拟合,通过随机丢弃一些神经元的输出来增强模型的泛化能力。
6. 前向传播
def forward(self, x, mask=None):x = self.norm1(x + self.dropout1(self.mha_block1(x, mask)))x = self.norm2(x + self.dropout2(self.mha_block2(x, mask)))x = self.norm3(self.linear2(self.dropout(self.activation(self.linear1(x)))))return x-
mha_block1和mha_block2:两个多头自注意力模块,分别处理输入x。 -
norm1和norm2:在每个自注意力模块后应用层归一化。 -
linear1和linear2:前馈网络的两个线性层,中间使用激活函数和 Dropout。 -
norm3:在前馈网络后应用层归一化。
需复现的完整代码(未标红部分为上节提到的多头自注意力机制)
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_project = nn.Linear(d_model, d_model)self.k_project = nn.Linear(d_model, d_model)self.v_project = nn.Linear(d_model, d_model)self.o_project = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, attn_mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)atten_scores = Q @ K.transpose(2, 3) / math.sqrt(self.d_k)if attn_mask is not None:attn_mask = attn_mask.unsqueeze(1)atten_scores = atten_scores.masked_fill(attn_mask == 0, -1e9)atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ Vout = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)out = self.o_project(out)return self.dropout(out)
class TransformerDecoderBlock(nn.Module):def __init__(self, d_model, dff, dropout):super().__init__()self.linear1 = nn.Linear(d_model, dff)self.activation = nn.GELU()# self.activation = nn.ReLU()self.dropout = nn .Dropout(dropout)self.linear2 = nn.Linear(dff, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.mha_block1 = MultiHeadAttention(d_model, num_heads, dropout)self.mha_block2 = MultiHeadAttention(d_model, num_heads, dropout)def forward(self, x, mask=None):x = self.norm1(x + self.dropout1(self.mha_block1(x, mask)))x = self.norm2(x + self.dropout2(self.mha_block2(x, mask)))x = self.norm3(self.linear2(self.dropout(self.activation(self.linear1(x)))))return x





