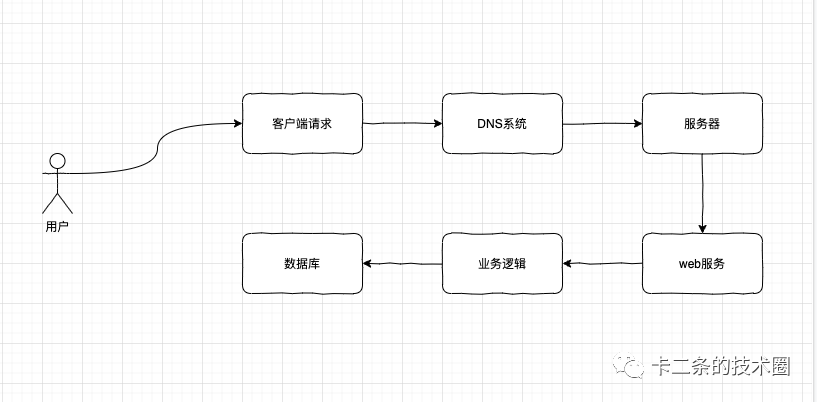
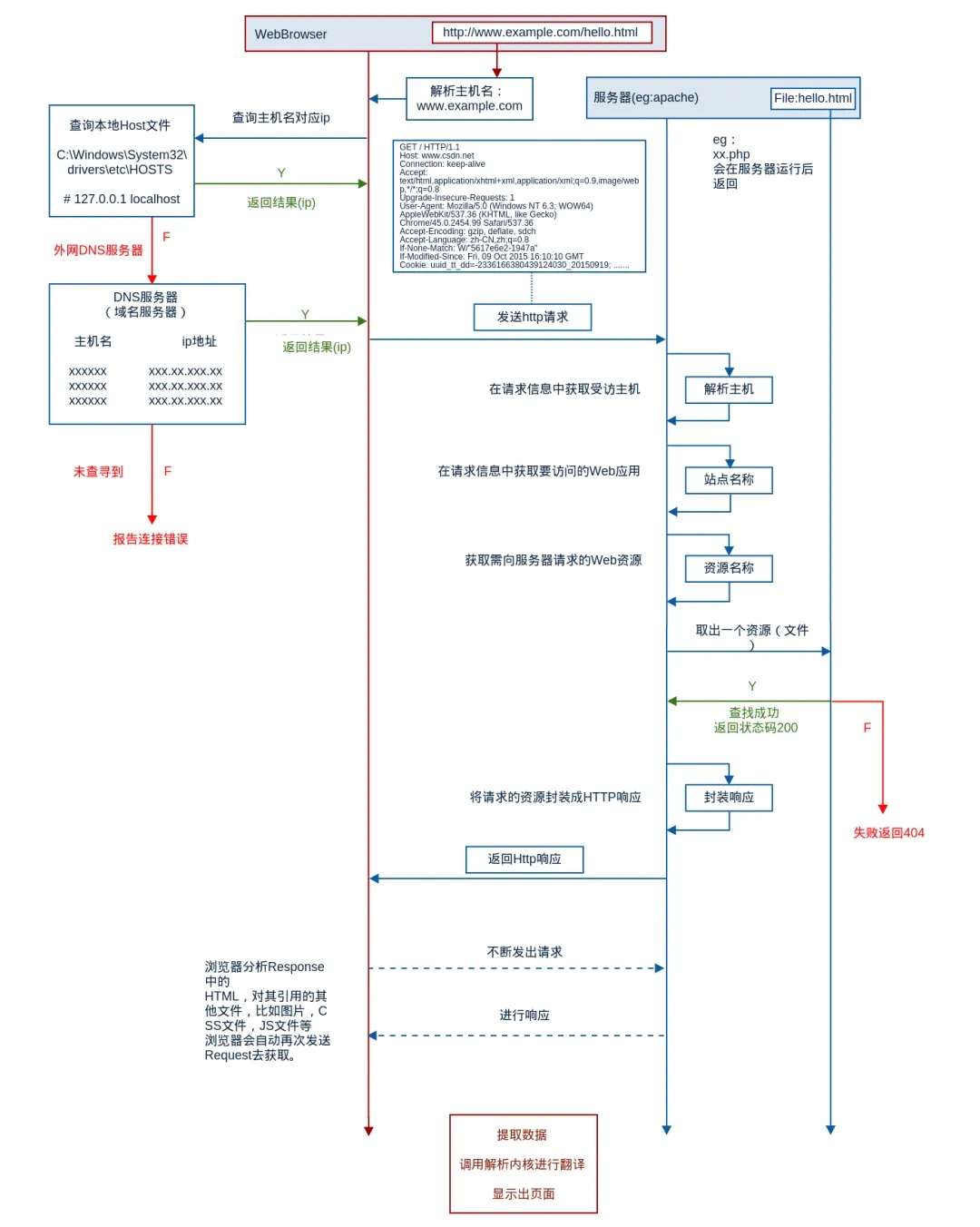
浏览器输入网址到呈现页面过程
DHCP(动态主机配置协议,Dynamic Host Configuration Protocol)是一种网络管理协议,用于自动分配 IP 地址和其他网络配置给计算机和设备。

应用层DNS解析,传输层TCP连接,网络层IP,数据链路MAC,真实物理层,接收到之后再一层层扒皮。
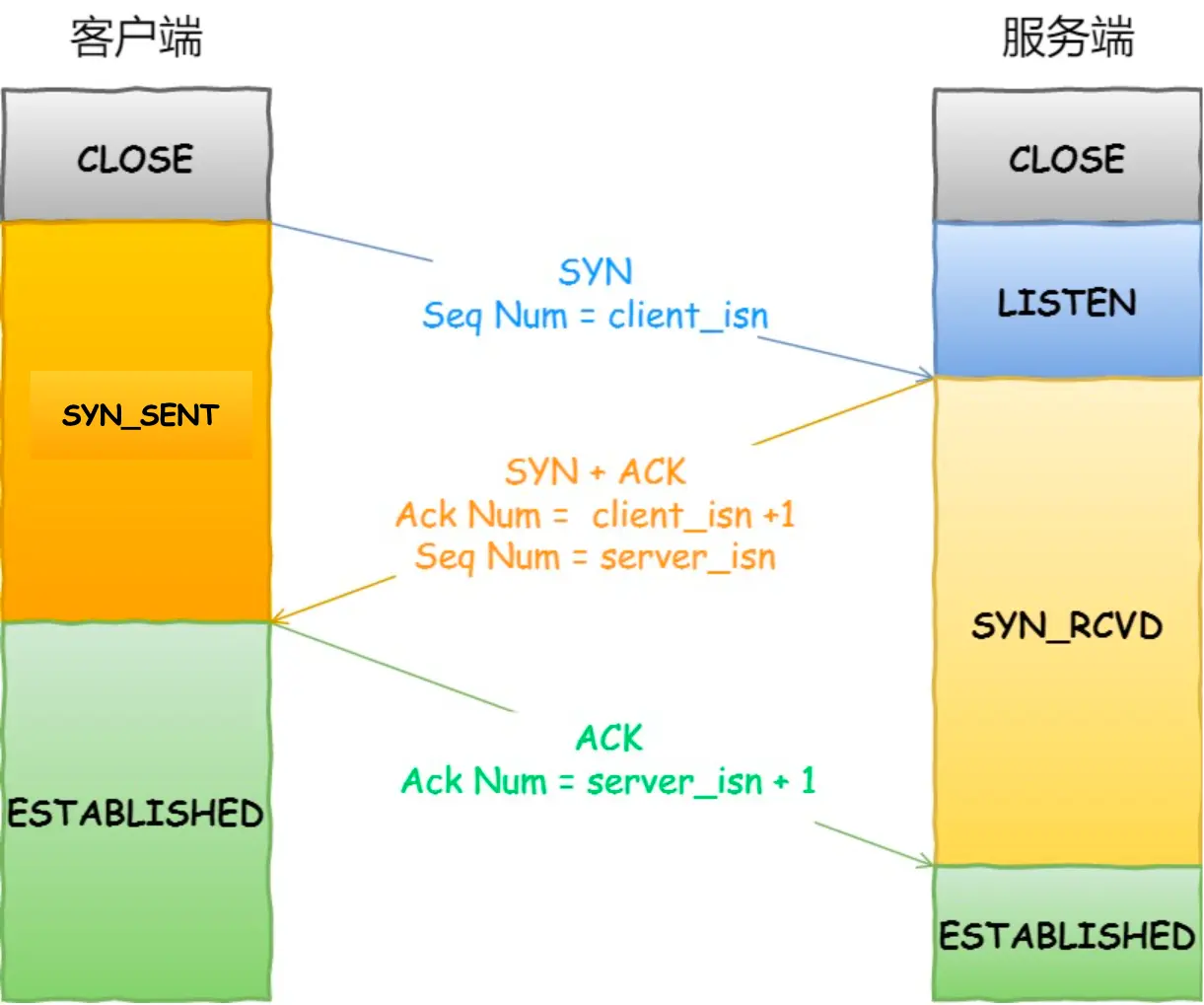
TCP连接过程
tcp报文结构,具体讲讲包含哪些字段及作用?
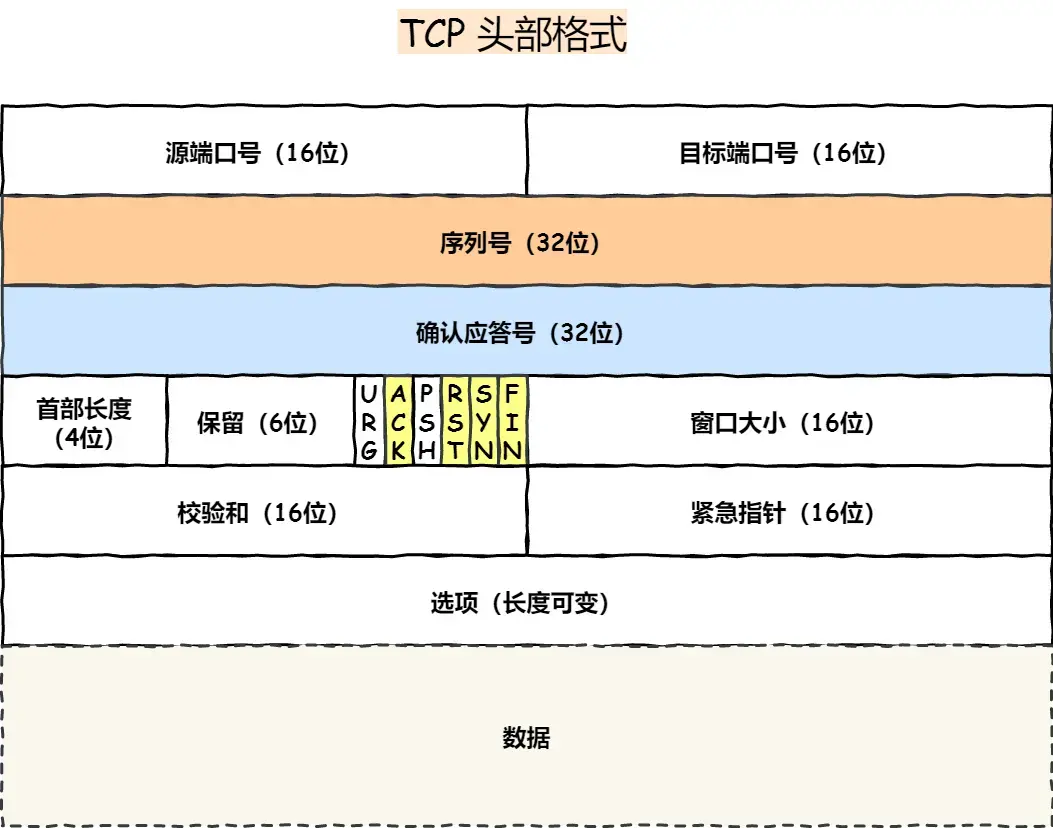
16位端口号:告知主机该报文段是来自哪里**(源端口Source Port)以及传给哪个上层协议或应用程序(目的端口Destination Port)**的。
32位序列号seq:一次TCP通信(从TCP连接建立到断开)过程中某一个传输方向上的字节流的每个字节的编号。
32位确认号(acknowledgement number):用作对另一方发送来的TCP报文段的响应。其值是收到的TCP报文段的序号值加1。
4位首部长度(header length):标识该TCP头部有多少个32bit字(4字节)。因为4位最大能标识15,所以TCP头部最长是60字节。
6位标志位包含如下几项:
URG标志,表示紧急指针(urgent pointer)是否有效。ACK标志,表示确认号是否有效。我们称携带ACK标识的TCP报文段为确认报文段。PSH标志,提示接收端应用程序应该立即从TCP接收缓冲区中读走数据,为接收后续数据腾出空间(如果应用程序不将接收到的数据读走,它们就会一直停留在TCP接收缓冲区中)。RST标志,表示要求对方重新建立连接。我们称携带RST标志的TCP报文段为复位报文段。SYN标志,表示请求建立一个连接。我们称携带SYN标志的TCP报文段为同步报文段。FIN标志,表示通知对方本端要关闭连接了。我们称携带FIN标志的TCP报文段为结束报文段。
16位窗口大小(window size):是TCP流量控制的一个手段。这里说的窗口,指的是接收通告窗口(Receiver Window,RWND)。它告诉对方本端的TCP接收缓冲区还能容纳多少字节的数据,这样对方就可以控制发送数据的速度。
16位校验和(TCP check sum):由发送端填充,接收端对TCP报文段执行CRC算法以检验TCP报文段在传输过程中是否损坏。注意,这个校验不仅包括TCP头部,也包括数据部分。这也是TCP可靠传输的一个重要保障。
16位紧急指针(urgent pointer):是一个正的偏移量。它和序号字段的值相加表示最后一个紧急数据的下一字节的序号。因此,确切地说,这个字段是紧急指针相对当前序号的偏移,不妨称之为紧急偏移。TCP的紧急指针是发送端向接收端发送紧急数据的方法。
TCP头部选项:TCP头部的最后一个选项字段(options)是可变长的可选信息。这部分最多包含40字节,因为TCP头部最长是60字节(其中还包含前面讨论的20字节的固定部分)。
报文长度有上限吗
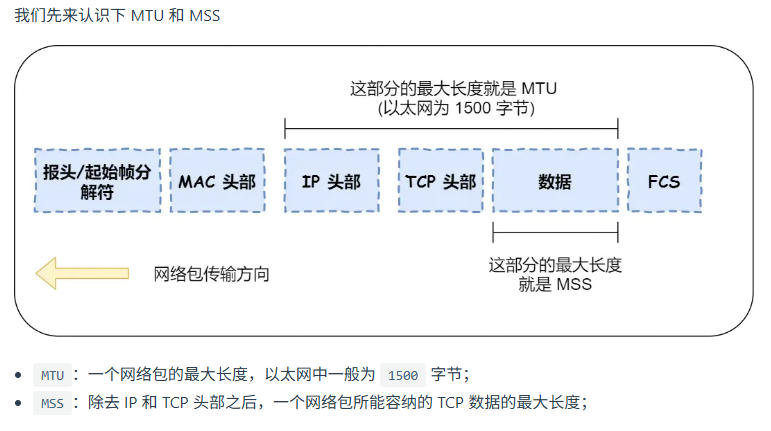
传输层除了tcp还有别的吗
UDP 然后说了说区别:数据包、无连接、不可靠,以及适用场景
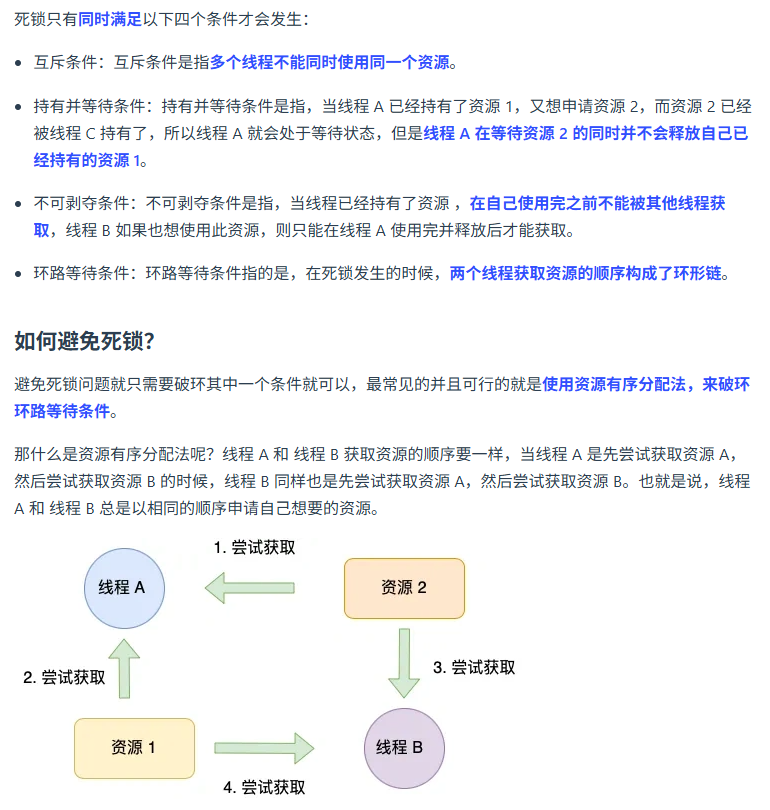
操作系统学过吧,讲讲死锁是什么?如何避免?
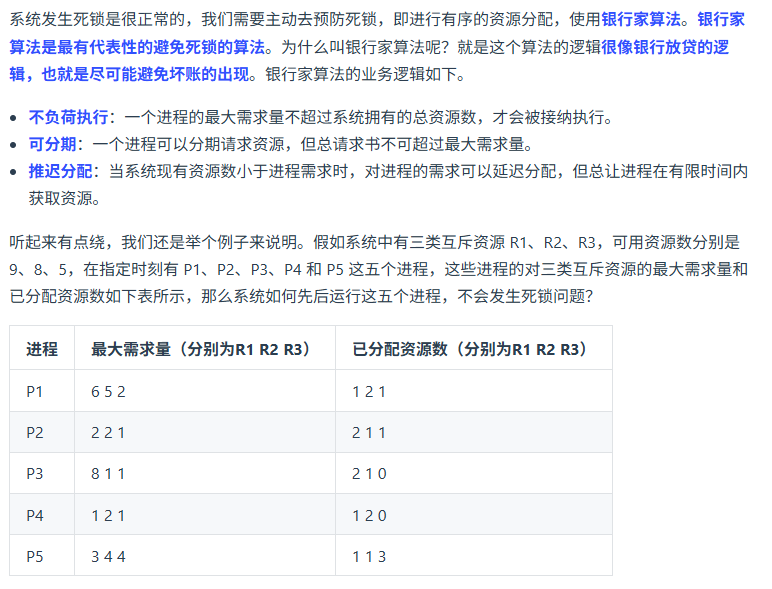
银行家算法有了解过么?具体说下思想?

cpu中断执行过程
硬中断与软中断的核心区别在于触发源(硬件 vs. 软件),但处理流程均依赖中断向量表(IDT)和上下文保存/恢复机制。



用户态、内核态

讲讲mysql和redis区别?
- 原理上关系/非关系,结构固定/灵活;
- mysql在磁盘中负责持久化;redis在内存中负责缓存,更快;

如何定义关系型/非关系型?



关系型数据库的相关规范?
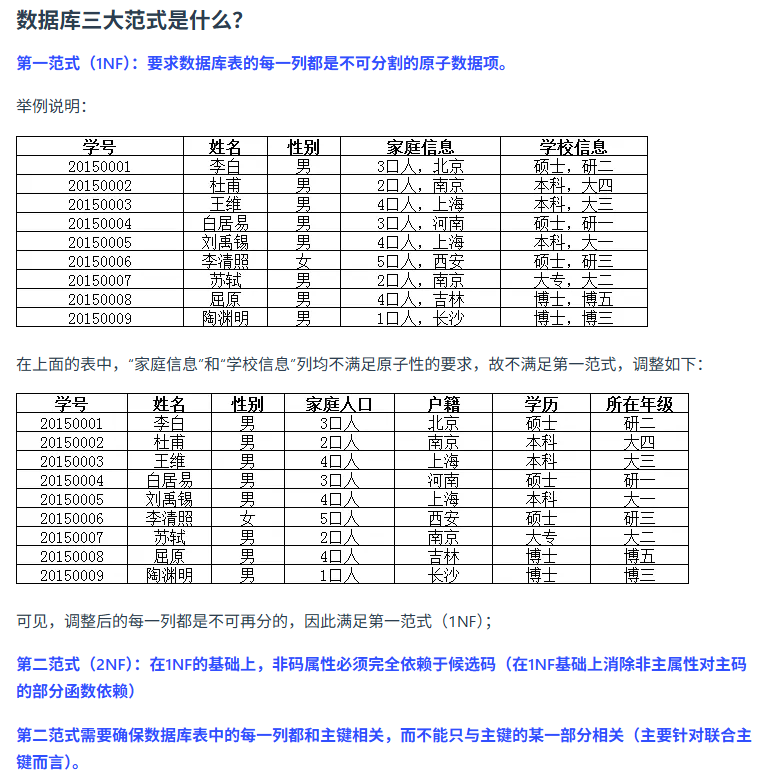
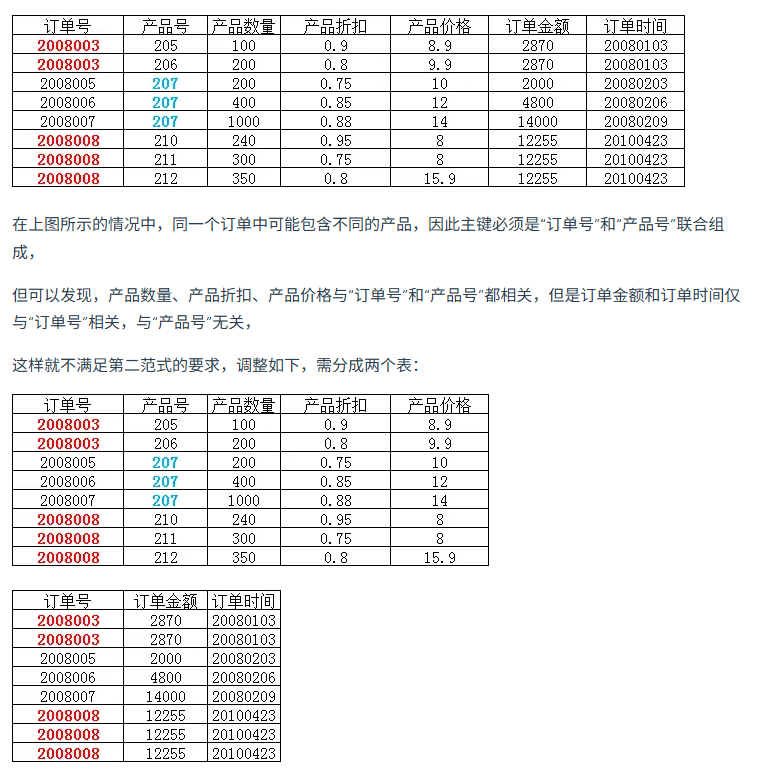
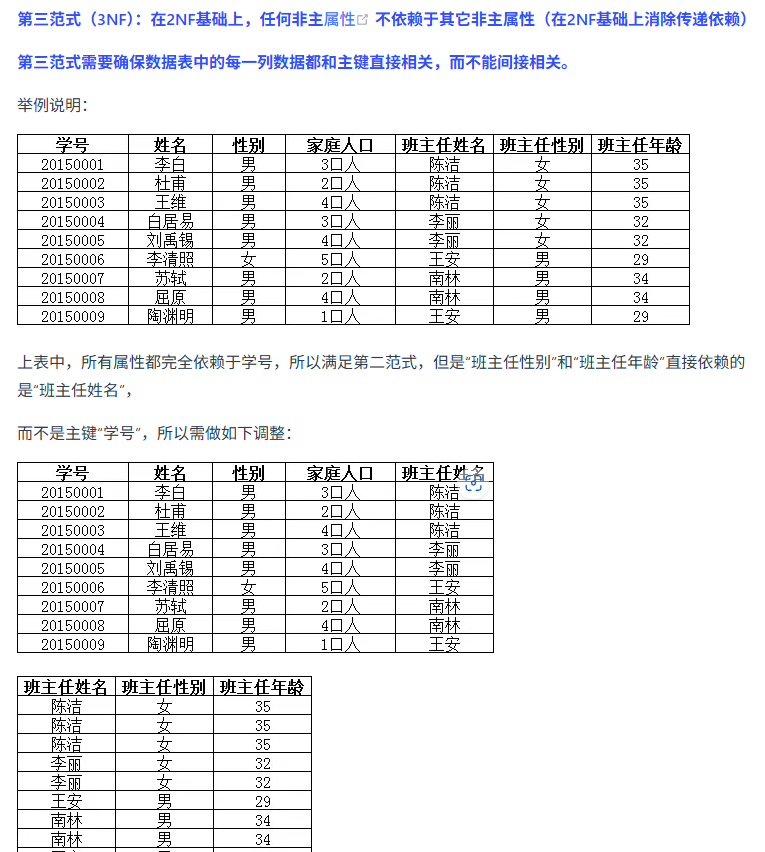
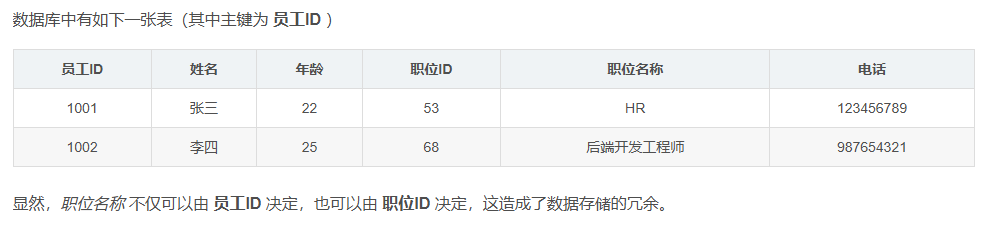



redis为什么快?
- 内存中;
- 单线程多路复用;
- 数据结构优秀,举了sds和跳表例子;
跳表上层下层节点数1/2的关系是固定的吗?
不是,添加操作是概率性的,而且这个概率也可以调;
跳表查询过程:小就向右大就向下
跳表节点存的是值
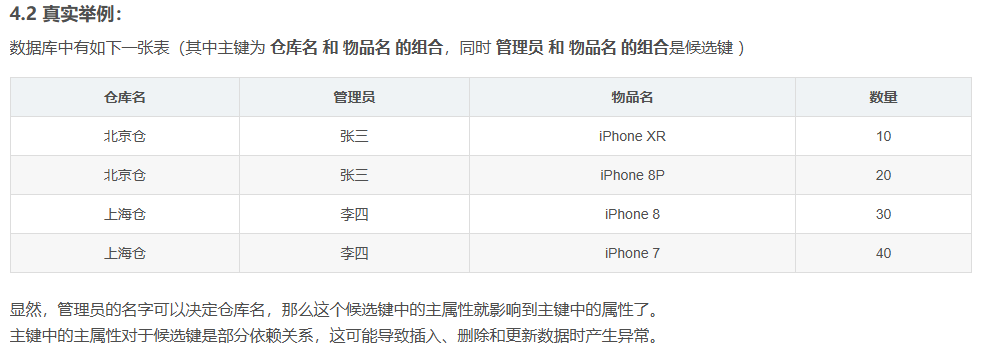
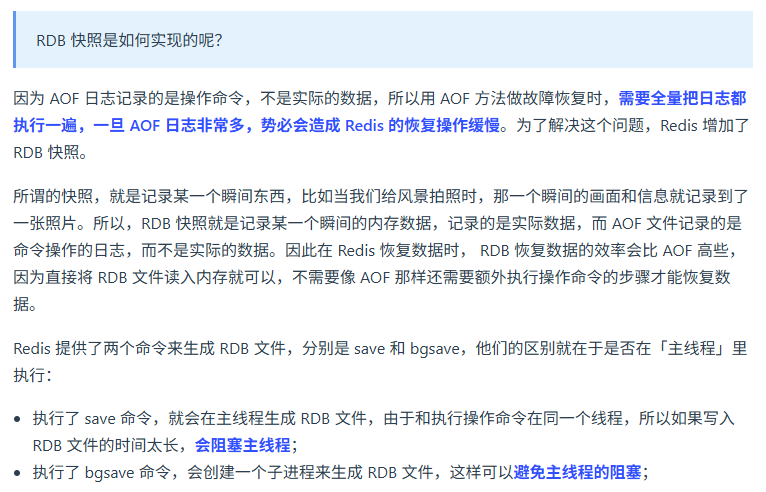
redis持久化存储



mongodb是关系型还是?为啥用?
- 非关系;
- 用mysql存大文档不理想,并且以后想在文章中扩展更多的内容,了解到mongodb比较合适;

能扩展什么类型?啥都可以,流媒体、评论嵌套都支持;
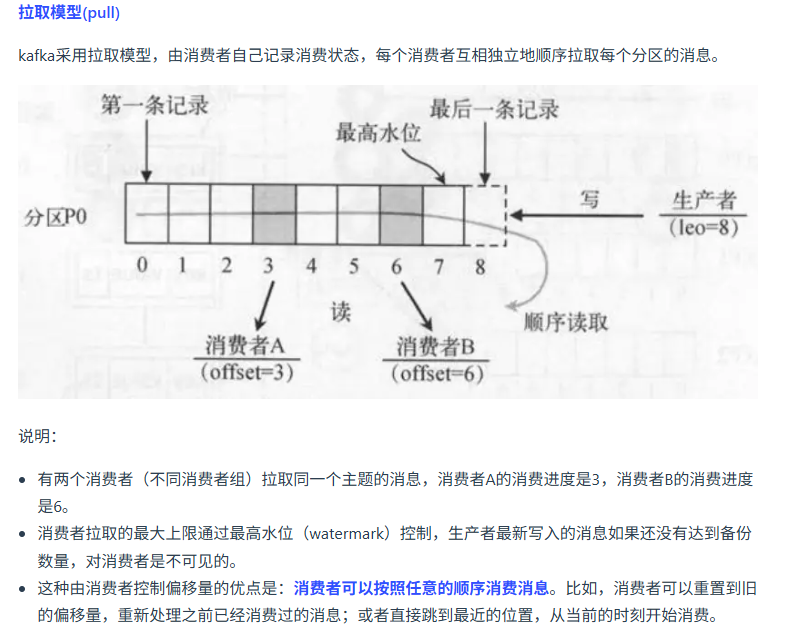
kafka使用场景?
- 异步 削峰 解藕 日志聚合 通信
- 项目里主要是用于异步点赞数的更新,避免阻塞正常的阅读过程





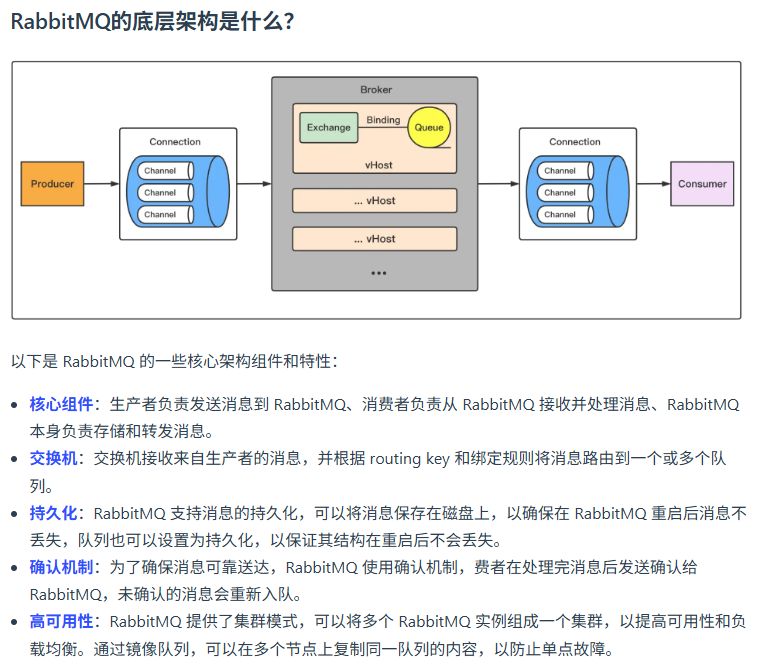
RabbitMQ
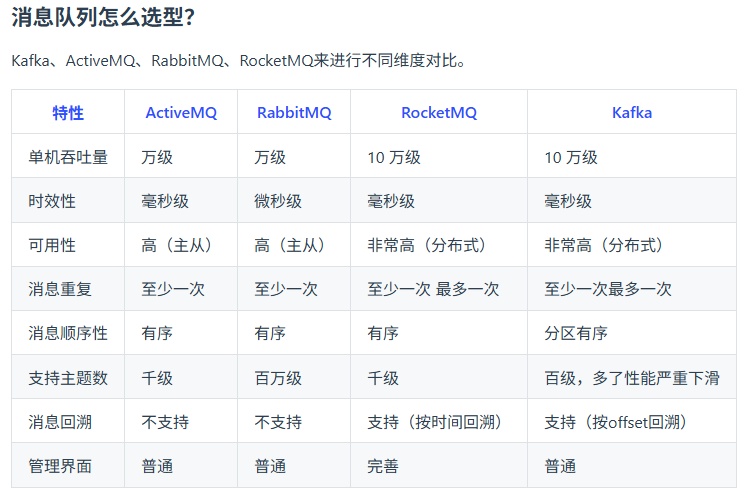
消息重复消费怎么解决?

怎么量化你项目的性能提升?
量化项目性能提升需要系统性地选择指标、建立基准、对比数据,并结合统计学方法验证结果的有效性。以下是详细的步骤和示例:
1. 定义关键性能指标(KPIs)
根据项目类型选择核心指标:
- 响应时间:平均延迟(ms)、P95/P99延迟(消除长尾效应)
- 吞吐量:每秒处理请求数(RPS)、数据库读写速度(TPS)
- 资源利用率:CPU/内存占用率(%)、磁盘IOPS、网络带宽(MB/s)
- 错误率:失败请求占比(%)、异常触发频率
- 可扩展性:集群规模扩大时的性能衰减比例(如10节点 vs 100节点的吞吐量差异)
示例:优化API网关后,目标将平均响应时间从200ms降至150ms,同时维持99.9%成功率。
2. 建立基准测试(Baseline)
- 工具选择:使用行业标准工具(如JMeter、Locust、wrk)或自定义脚本。
- 环境一致性:确保测试环境(硬件、网络、软件版本)与生产环境一致,避免容器化环境因资源隔离导致的偏差。
- 数据采样:多次运行测试(至少5次),取中位数或平均值,计算标准差以排除偶发干扰。
- 场景覆盖:模拟真实场景(如用户登录高峰期的混合读写操作)。
示例:在4核8G服务器上,用Apache Bench模拟100并发用户,持续压测10分钟,记录当前系统的平均吞吐量为1200 RPS。
3. 实施优化并收集数据
- A/B测试:新旧版本并行运行,对比相同负载下的表现(如蓝绿部署)。
- 渐进式验证:逐步放大优化范围(如从10%流量到全量),观察指标变化。
- 监控工具:集成Prometheus+Grafana实时监控,或使用ELK堆栈分析日志。
示例:优化数据库索引后,新版本在相同测试条件下平均查询时间从300ms降至180ms,CPU占用率从75%降至60%。
4. 数据分析与统计验证
-
提升百分比计算:
[
\text{提升百分比} = \left( \frac{\text{旧指标值} - \text{新指标值}}{\text{旧指标值}} \right) \times 100%
]
如响应时间从200ms→150ms,提升25%((200-150)/200=25%)。 -
统计学显著性:使用t-test或Mann-Whitney U检验(非正态分布数据)判断差异是否非随机(p-value <0.05)。
-
业务影响映射:将技术指标转化为业务价值(如延迟降低20% → 用户留存率提升5%)。
示例:通过t-test分析,新旧版本响应时间差异的p-value为0.003,证明优化具有统计显著性。
5. 多维结果展示
- 可视化报告:用折线图展示优化前后的QPS对比,箱型图显示延迟分布。
- 成本效益分析:如资源利用率降低30%,估算年度云成本节省$50K。
- 长尾优化:强调P99延迟从2s降至800ms,减少极端情况对用户体验的影响。
示例报告节选:
优化结果
- 平均响应时间:200ms → 142ms (↓29%)
- P99延迟:1.8s → 0.7s (↓61%)
- 服务器成本:$10k/月 → $7k/月(节省30%)
- 统计显著性:p=0.002(置信度99%)
6. 持续监控与反脆弱性
- 自动化测试流水线:在CI/CD中集成性能测试,防止代码变更导致性能回退。
- 真实环境追踪:通过APM工具(如New Relic、Datadog)监控生产环境,验证优化效果的持续性。
- 反馈循环:建立性能看板,定期Review指标,制定下一阶段优化目标(如进一步降低资源消耗)。
注意事项
- 避免局部优化陷阱:确保单点改进不损害整体系统(如缓存提速但导致数据不一致)。
- 权衡指标间关系:吞吐量提升可能伴随更高的CPU占用,需评估是否可接受。
- 用户感知优先:技术指标需与用户体验挂钩(如首屏加载时间<3s的SLA)。
通过以上方法,性能提升不再是主观感受,而是可验证、可解释的数据驱动结论。
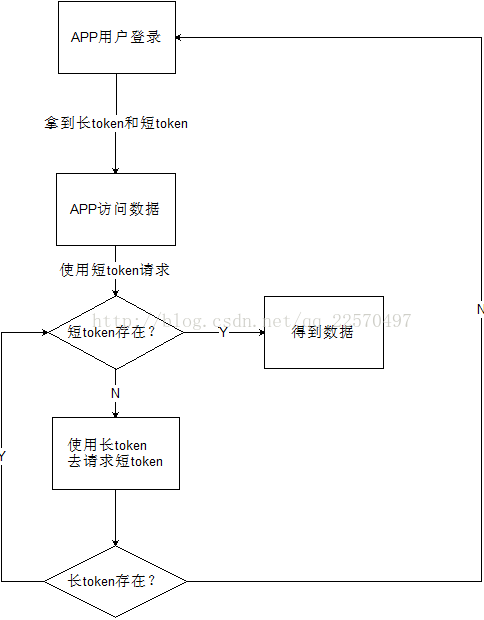
长短token

DDD领域驱动设计
以业务领域为核心


项目里涉及跨库事务一致性如何处理?


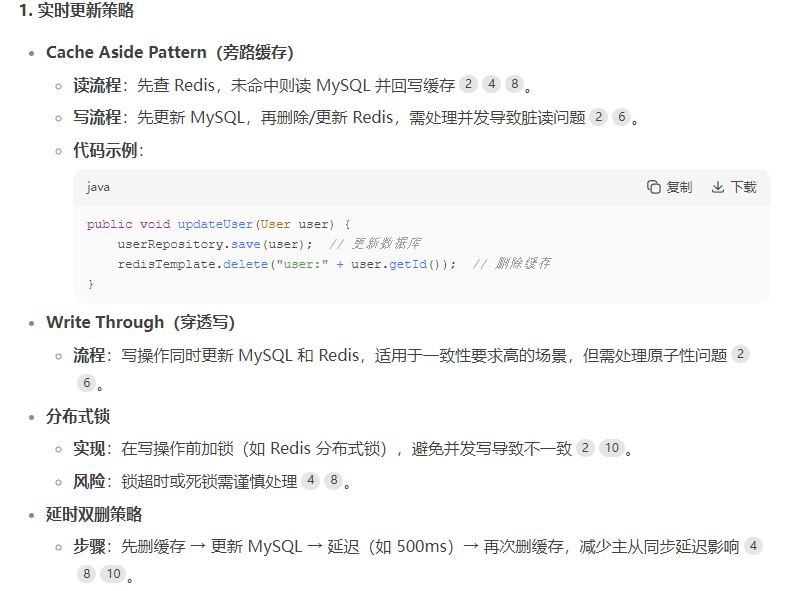
项目里redis适用场景,和mysql一致性怎么保证?

如何用ai改造你的项目?


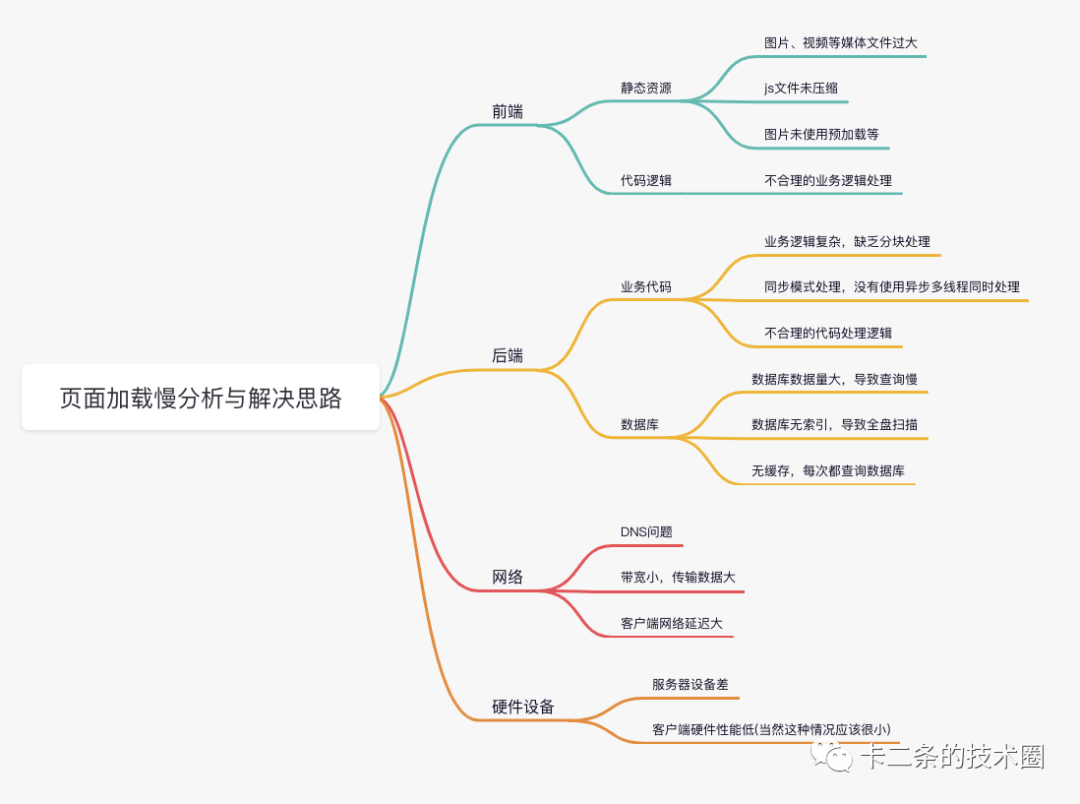
一个页面跳转慢,交给你去处理,你会怎么处理这个问题?