论文《 BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation 》原理解析及代码复现。
文章目录
- 概要
- 理论知识
- 整体架构流程
- 关键模块解析
- 细节分支(Detail Branch)
- 语义分支(Semantic Branch)
- 子结构1:Gather Expansion Layer
- 子结构2:ContextEmbeddingBlock
- 双分支特征融合(AggregationLayer)
- 多尺度监督机制(SegHead)
- 模型实践
- 训练数据准备
- 模型训练
- 影像测试
- 结果示例
概要
提示: (1)论文地址 https://arxiv.org/abs/2004.02147 (2)本人打包好数据可运行代码:BiSeNetv2.zip 链接: https://pan.baidu.com/s/1tHtcWoCx3ZftU73Yq5cPww?pwd=icc5 提取码: icc5
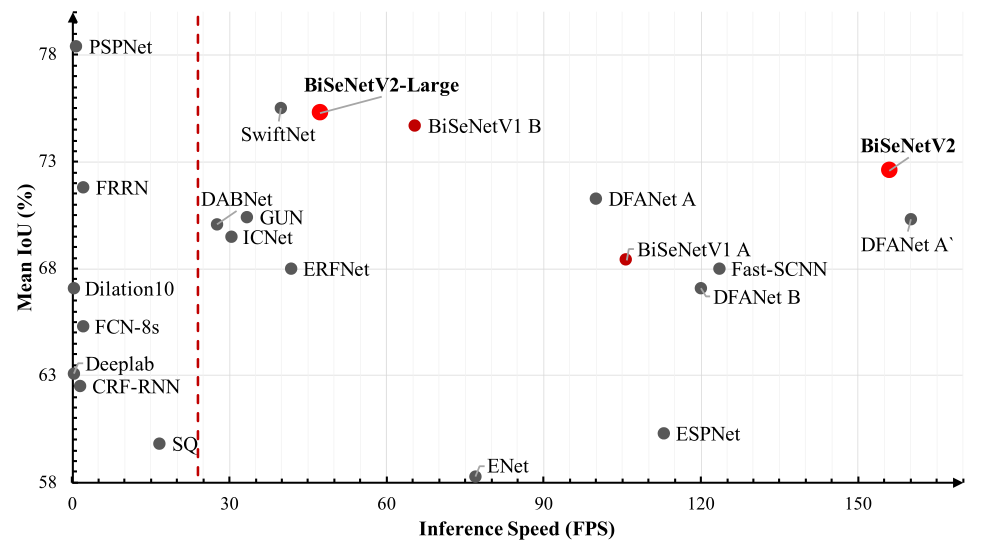
BiSeNetv2是面向实时语义分割任务的高效网络架构,其核心设计理念是通过双分支结构实现细节特征与语义特征的协同优化。相比传统单分支架构,BiSeNetv2在Cityscapes数据集上达到75.8% mIoU的同时保持47.3 FPS(1080Ti),主要创新点包括:
-
双分辨率特征流:通过Detail Branch(细节分支)和Semantic Branch(语义分支)的并行处理,分别捕获高分辨率空间细节和深层语义信息。
-
轻量化上下文聚合:采用改进的Gather Expansion模块替代传统膨胀卷积,在保持感受野的同时减少70%的计算量。
-
多层次特征监督:引入4个辅助分割头实现深度监督,加速模型收敛。
理论知识
整体架构流程
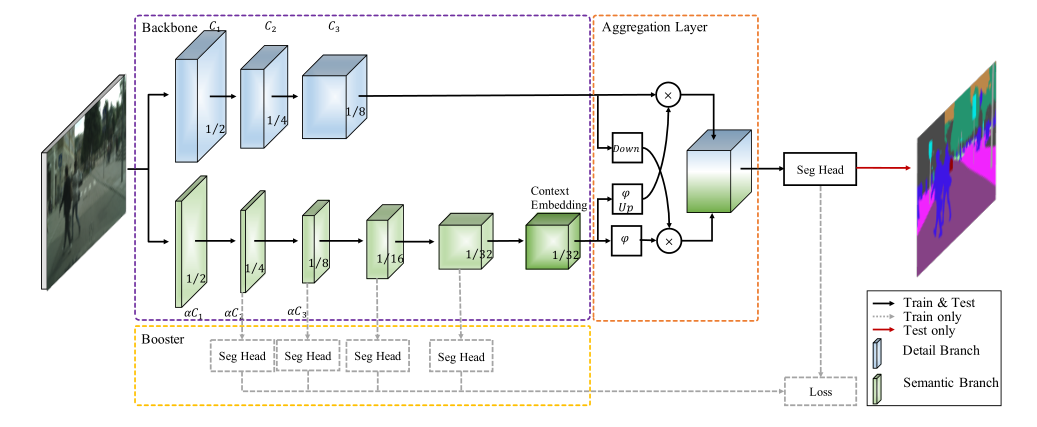
class BiSeNetv2(nn.Module):def __init__(self, backbone: str = None, num_classes: int = 2) -> None:super().__init__()self.detail_branch = DetailBranch()self.semantic_branch = SemanticBranch()self.aggregation_layer = AggregationLayer()self.output_head = SegHead(128, 1024, num_classes, upscale_factor=8, is_aux=False)def forward(self, x):x_d = self.detail_branch(x)aux2, aux3, aux4, aux5, x_s = self.semantic_branch(x)output = self.aggregation_layer(x_d, x_s)output = self.output_head(output)- 高分辨率分支(细节分支,DetailBranch):保持1/8输入分辨率特征图来捕捉图像中的细节信息,使用常规残差块(RB),确保能够保留图像中的局部特征,提升分割精度。
- 低分辨率分支(语义分支,SemanticBranch):通过步长2卷积逐步下采样至1/32,使用瓶颈残差块(RBB)提取语义。较低分辨率的特征图可以捕捉图像的全局语义信息,同时低分辨率处理使得该路径在计算上更加高效,能够快速提取高级语义特征。
- 特征融合(Aggregation Layer),预测(SegHead )。
关键模块解析
| 模块名称 | 功能描述 | 关键创新点 |
|---|---|---|
| Detail Branch | 细节分支,保留高分辨率空间细节 | 浅层卷积堆叠保持细节 |
| Semantic Branch | 语义分支,提取深层语义特征 | Gather Expansion模块优化计算 |
| Aggregation Layer | 双分支特征融合 | 跨分辨率特征交互机制 |
| Context Embedding | 语义分支子结构,全局上下文信息建模 | 轻量化全局注意力 |
| SegHead | 多尺度特征解码监督训练 | PixelShuffle上采样 |
细节分支(Detail Branch)
class DetailBranch(nn.Module):def __init__(self):self.S1 = nn.Sequential( # Stage1: 3→64, 1/2下采样ConvModule(3,64,3,2,1),ConvModule(64,64,3,1,1))self.S2 = nn.Sequential( # Stage2: 64→64, 1/4ConvModule(64,64,3,2,1),ConvModule(64,64,3,1,1),ConvModule(64,64,3,1,1))self.S3 = nn.Sequential( # Stage3: 64→128, 1/8ConvModule(64,128,3,2,1),ConvModule(128,128,3,1,1),ConvModule(128,128,3,1,1))def forward(self, x):return self.S3(self.S2(self.S1(x)))
DetailBranch包含了三个主要的子模块(S1, S2, S3),每个子模块都是一个由多个卷积操作构成执行顺序(Sequential)。forward方法依次通过这些子模块来处理输入数据,并最终输出处理后的特征图。设计特点:
-
全卷积结构,无池化操作,最大程度保留空间细节
-
渐进式下采样(1/8最终尺度)平衡细节保留与计算量
-
使用3×3小卷积核堆叠,参数量仅1.2M
语义分支(Semantic Branch)
class SemanticBranch(nn.Module):def __init__(self) -> None:super().__init__()self.S1S2 = StemBlock()self.S3 = nn.Sequential(GatherExpansionLayerv2(16, 32),GatherExpansionLayerv1(32, 32))self.S4 = nn.Sequential(GatherExpansionLayerv2(32, 64),GatherExpansionLayerv1(64, 64))self.S5_1 = nn.Sequential(GatherExpansionLayerv2(64, 128),GatherExpansionLayerv1(128, 128),GatherExpansionLayerv1(128, 128),GatherExpansionLayerv1(128, 128))self.S5_2 = ContextEmbeddingBlock()def forward(self, x):x2 = self.S1S2(x)x3 = self.S3(x2)x4 = self.S4(x3)x5_1 = self.S5_1(x4)x5_2 = self.S5_2(x5_1)return x2, x3, x4, x5_1, x5_2
由多个子模块组成的神经网络模型,其中包括多个分支(如 S1S2, S3, S4, S5_1, S5_2),每个分支都负责从输入图像中提取不同层次的特征信息。它的设计目标是通过逐层处理,逐渐提取更深层次的语义信息,帮助网络更好地理解输入数据。设计特点:
-
层次化特征提取,每个子模块都在上一层的基础上进一步扩展特征的维度或复杂性,从而使得网络能够在不同尺度上学习数据的语义信息。
(1)S1S2模块:提取原始数据的基础特征。
(2)S3和S4模块:扩展特征维度,提取更高层次的特征。
(3)S5_1和S5_2模块:通过多个层次的特征扩展和上下文嵌入,进一步捕捉更深层次的语义信息。 -
1×1卷积实现通道压缩(16→8),减少计算量30%
子结构1:Gather Expansion Layer
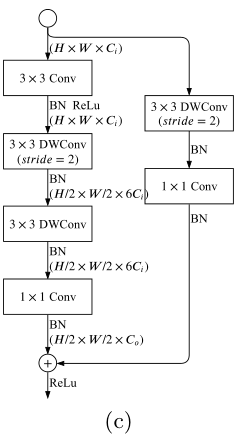
class GatherExpansionLayerv2(nn.Module):def __init__(self, in_ch, out_ch, e=6):self.inner = nn.Sequential( # 主路径ConvModule(in_ch,in_ch,3,1,1),DepthwiseConv(in_ch, in_ch*e, stride=2), # 深度可分离卷积ConvModule(in_ch*e, in_ch*e,3,1,1),Conv1x1(in_ch*e, out_ch))self.outer = nn.Sequential( # 捷径DepthwiseConv(in_ch, in_ch, stride=2),Conv1x1(in_ch, out_ch))GatherExpansionLayerv1是常规的33、11、残差累加操作,而v2在结构上融合了深度可分离卷积,能够有效地减少计算量,同时保留了重要的特征信息,该结构技术亮点:
-
深度可分离卷积减少参数量(标准卷积的1/8)
-
扩展因子e=6增大感受野少量增加计算
-
残差连接缓解梯度消失
子结构2:ContextEmbeddingBlock
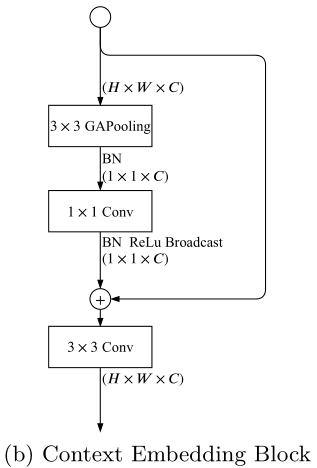
class ContextEmbeddingBlock(nn.Module):def __init__(self) -> None:super().__init__()self.inner = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.BatchNorm2d(128),ConvModule(128, 128, 1, 1, 0) )self.conv = ConvModule(128, 128, 3, 1, 1) def forward(self, x):y = self.inner(x)out = x + yreturn self.conv(out)
ContextEmbeddingBlock 是一个用于提取和融合上下文信息的模块,核心操作是通过 self.inner 提取全局信息,并通过残差连接与输入特征图结合,再通过卷积层进一步处理。这种结构的好处是能够捕捉全局上下文信息(通过全局池化),同时保持局部特征(通过残差连接),并进一步通过卷积增强特征表示的表达能力。
双分支特征融合(AggregationLayer)
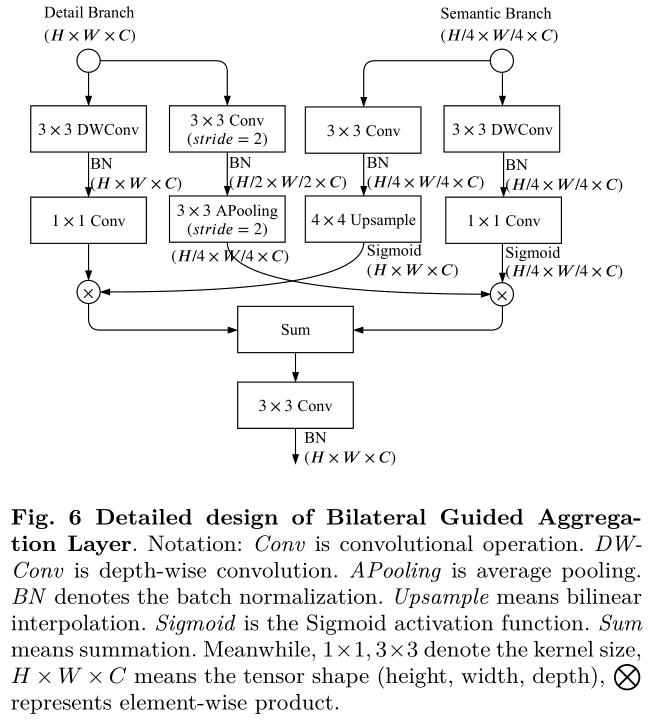
class AggregationLayer(nn.Module):def __init__(self) -> None:super().__init__()self.left1 = nn.Sequential(nn.Conv2d(128, 128, 3, 1, 1, groups=128, bias=False),nn.BatchNorm2d(128),nn.Conv2d(128, 128, 1, 1, 0, bias=False))self.left2 = nn.Sequential(nn.Conv2d(128, 128, 3, 2, 1, bias=False),nn.BatchNorm2d(128),nn.AvgPool2d(3, 2, 1, ceil_mode=False))self.right1 = nn.Sequential(nn.Conv2d(128, 128, 3, 1, 1, bias=False),nn.BatchNorm2d(128),nn.Upsample(scale_factor=4),nn.Sigmoid())self.right2 = nn.Sequential(nn.Conv2d(128, 128, 3, 1, 1, groups=128, bias=False),nn.BatchNorm2d(128),nn.Conv2d(128, 128, 1, 1, 0, bias=False),nn.Sigmoid())self.up = nn.Upsample(scale_factor=4) self.conv = ConvModule(128, 128, 3, 1, 1) def forward(self, x_d, x_s):x1 = self.left1(x_d)x2 = self.left2(x_d)x3 = self.right1(x_s)x4 = self.right2(x_s)left = x1 * x3right = x2 * x4right = self.up(right)out = left + rightreturn self.conv(out)
设置两个不同的路径来处理输入特征图:一个“左”路径和一个“右”路径。每个路径对输入进行不同的操作:
1、左路径,处理较大尺度的输入特征图(x_d,细节特征),通过两个连续的块进行处理:
- left1:首先使用深度可分离卷积(groups=128),然后是批归一化,再进行标准卷积。深度可分离卷积通过减少参数量和计算量来提高效率。
- left2:使用步幅为2的卷积进行下采样,再进行批归一化和平均池化操作,进一步降低输入特征图的空间维度。
左路径的输出将包含来自 x_d 的高层特征,且具有较高的分辨率,保留了更多的细节特征。
2、右路径, 处理较小尺度的输入特征图(x_s,语义特征),并通过操作来扩展分辨率使语义特征与左路径细节特征尺度一致:
- right1:首先进行标准卷积、批归一化,然后通过 Upsample 操作将特征图上采样4倍,并使用 sigmoid 激活函数将值限制在 0 到 1 之间。
- right2:类似于 left1,使用深度可分离卷积、批归一化和标准卷积,最后应用 sigmoid 激活函数。这个步骤旨在进一步细化特征。
右路径的输出具有较低的分辨率和较多的上下文语义特征,通过上采样和卷积操作扩展尺度。
3、特征融合
- left = x1 * x3:左路径的输出(x1)与右路径的上采样输出(x3)进行逐元素相乘。
- right = x2 * x4:x2 和 x4 也进行逐元素相乘,x4 是右路径的最终处理结果。
- right = self.up(right):右路径的输出再经过一个上采样操作,将其分辨率扩大四倍,与左路径的输出对齐。
多尺度监督机制(SegHead)
class BiSeNetv2(nn.Module):def forward(self, x):if self.training:aux2 = self.aux2_head(aux2)aux3 = self.aux3_head(aux3)aux4 = self.aux4_head(aux4)aux5 = self.aux5_head(aux5)return output#, aux2, aux3, aux4, aux5
多尺度监督提升浅层特征判别性,辅助损失权重设置为0.4(主损失为1.0),仅训练阶段启用,推理时自动跳过。
提示:本代码中将该功能注释暂停使用了,打开后注意在dp0_train.py训练过程中增加对应损失函数定义和计算。
模型实践
训练数据准备
提示:云盘代码已内置少量高分二号卫星影像建筑物数据集
训练数据分为原始影像和标签(二值化,0和255),均位于Sample文件夹内,本示例数据为512*512,数据相对路径为:
Sample\Build\train\ IMG_T1
------------------\ IMG_LABEL
-------------\val \ IMG_T1
------------------\IMG_LABEL
模型训练
运行dp0_train.py,模型开始训练,核心参数包括:
| parser参数 | 说明 |
|---|---|
| num_epochs | 训练批次 |
| learning_rate | 初始学习率 |
| batch_size | 单次样本数量 |
| dataset | 数据集名字 |
| crop_height | 训练时影像重采样尺度 |
数据结构CDDataset_Seg定义在utils文件夹dataset.py中,注意读取后进行了数据增强(随机翻转),灰度化,尺寸调整,标签归一化、 one-hot 编码,以及维度和数据类型的转换,最终得到适用于 PyTorch 模型训练的张量。
# 读取训练图片和标签图片image_t1 = cv2.imread(image_t1_path,-1)#image_t2 = cv2.imread(image_t2_path)label = cv2.imread(label_path)# 随机进行数据增强,为2时不做处理if self.data_augment:flipCode = random.choice([-1, 0, 1, 2])if flipCode != 2:
# image_t1 = normalized(image_t1, 'tif')image_t1 = self.augment(image_t1, flipCode)#image_t2 = self.augment(image_t2, flipCode)label = self.augment(label, flipCode) label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)image_t1 = cv2.resize(image_t1, (self.img_h, self.img_w))#image_t2 = cv2.resize(image_t2, (Config.img_h, Config.img_w))label = cv2.resize(label, (self.img_h, self.img_w))label = label/255label = label.astype('uint8')label = onehot(label, 2)label = label.transpose(2, 0, 1)label = torch.FloatTensor(label)
训练过程如下图所示,模型保存至checkpoints数据集同名文件夹内。
影像测试
运行dp0_AllPre.py,核心参数包括:
| parser参数 | 说明 |
|---|---|
| Checkpointspath | 预训练模型位置名称 |
| Dataset | 批量化预测数据文件夹 |
| Outputpath | 输出数据文件夹 |
数据加载方式:
pre_dataset = CDDataset_Pre(data_path=pre_imgpath1,transform=transforms.Compose([transforms.ToTensor()]))pre_dataloader = torch.utils.data.DataLoader(dataset=pre_dataset,batch_size=1,shuffle=False,pin_memory=True,num_workers=0)
需要注意,预测定义的数据结构CDDataset_Pre与训练时CDDataset_Seg有区别,没有resize等,后续使用自己的数据训练时注意调整。
结果示例
论文结果:
打包好的GF2数据:





