前言
spiderflow入门及实践这篇文章有网友评论说如何使用正则表达式提取文本以及如何使用自定义函数来实现需要的功能,本文单独开一篇文章来解答这部分问题,希望能够帮助到这位网友和其他有需要的朋友。
支持的正则表达式
对正则表达式和xpath语法的支持主要是基于ExtractFunctionExecutor这个类,使用extract前缀。
spiderflow中支持如下表达式用法:
| 功能 | 示例 | 说明 |
|---|---|---|
| 根据jsonpath提取内容 | KaTeX parse error: Expected '}', got 'EOF' at end of input: …ath(resp.json,'.code’)} | 输入json, 返回json中的code字段值 |
| 根据正则表达式提取内容 | ${extract.regx(resp.html,‘(\d).?(\d).?(\d)’)} | 取出title标签中间的内容,默认取第1个 |
| 根据正则表达式提取内容 | ${extract.regx(resp.html,‘(\d).?(\d).?(\d)’,2)} | 取出title标签中间的内容,取指定位置的数据, 返回字符串 |
| 根据正则表达式提取内容 | ${extract.regx(resp.html,‘(\d).?(\d).?(\d)’,[1,2])} | 取出title标签中间的内容,取指定位置的数据,返回数组 |
| 根据正则表达式提取内容 | ${extract.regxs(resp.html,‘(\d).?(\d).?(\d)’)} | 取出title标签中间的内容,取指定位置的数据,返回数组,默认取第1个 |
| 根据正则表达式提取内容 | ${extract.regxs(resp.html,‘(\d).?(\d).?(\d)’, [1, 2])} | 取出title标签中间的内容,取指定位置的数据,返回数组实战 |
正则实战
示例1: 使用正则取出"a5b8c9"中的数字
假设变量名为source:
取出数字8的表达式写法: ${extract.regx(source,‘(\d).?(\d).?(\d)’,2)}
取出8和9的表达式写法: ${extract.regx(source,‘(\d).?(\d).?(\d)’,[2, 3])}
取出所有数字的表达式写法: ${extract.regxs(source,‘(\d)’)}
PS: 以上仅为示例,实际可以有其他实现方式
简单验证如下:
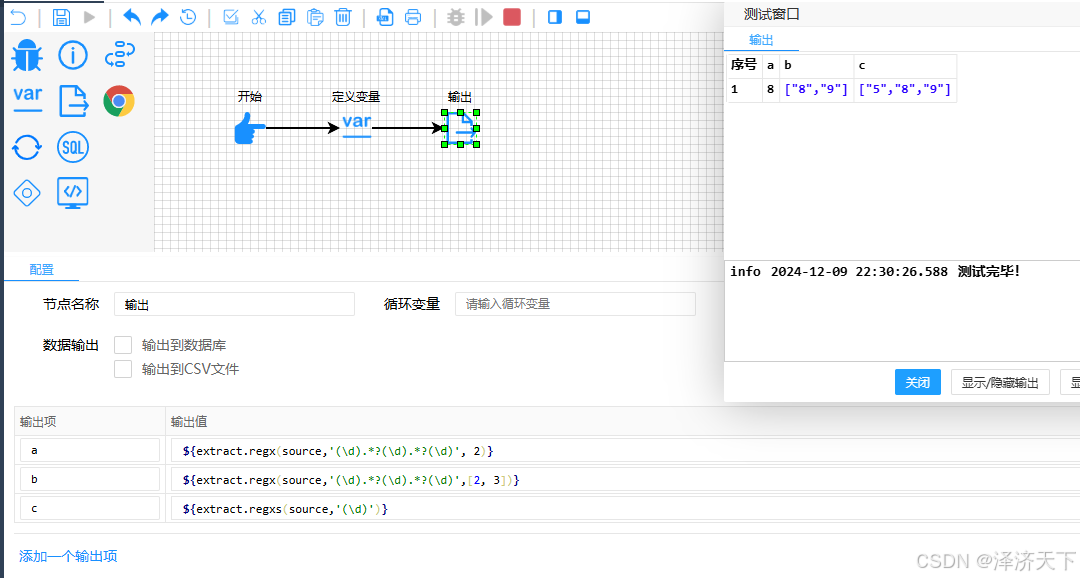
示例2: 取出"学号: 202411013021"中的数字
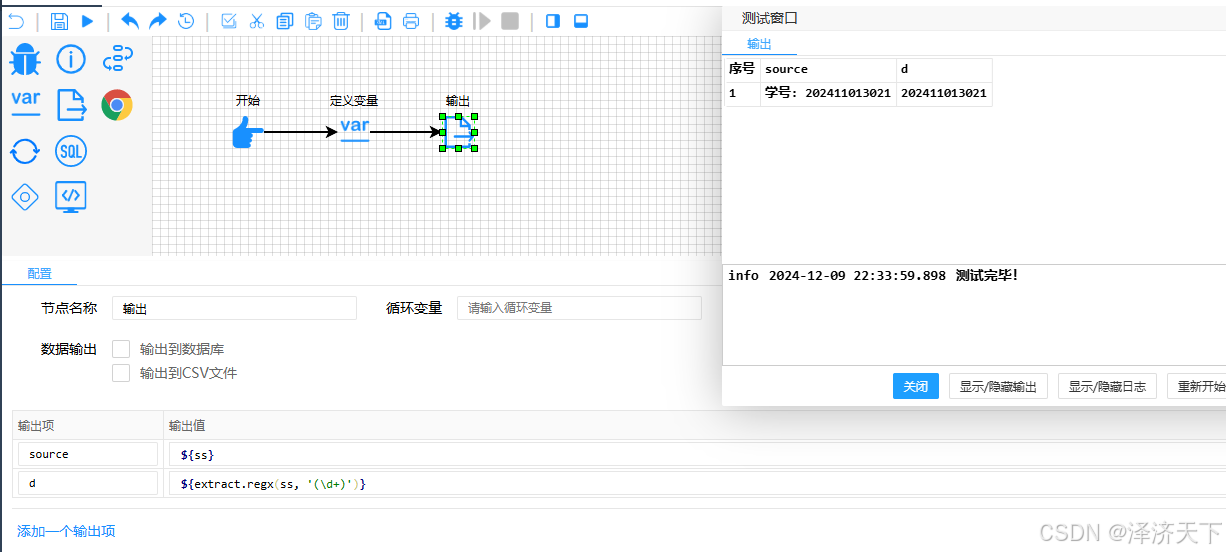
以上是简单示例,其他用法可参考上述规则自行扩展,有任何问题欢迎留言交流。
自定义函数的使用
示例: 使用自定义函数实现风力等级转换
这里还是使用实例来说明,假设我们有这样一个需求,根据我们抓取到的风速数据(单位m/s)转换成风力等级,每个等级对应一个区间,使用自定义函数实现结果的输出。
先看下自定义函数界面结构,如下图:
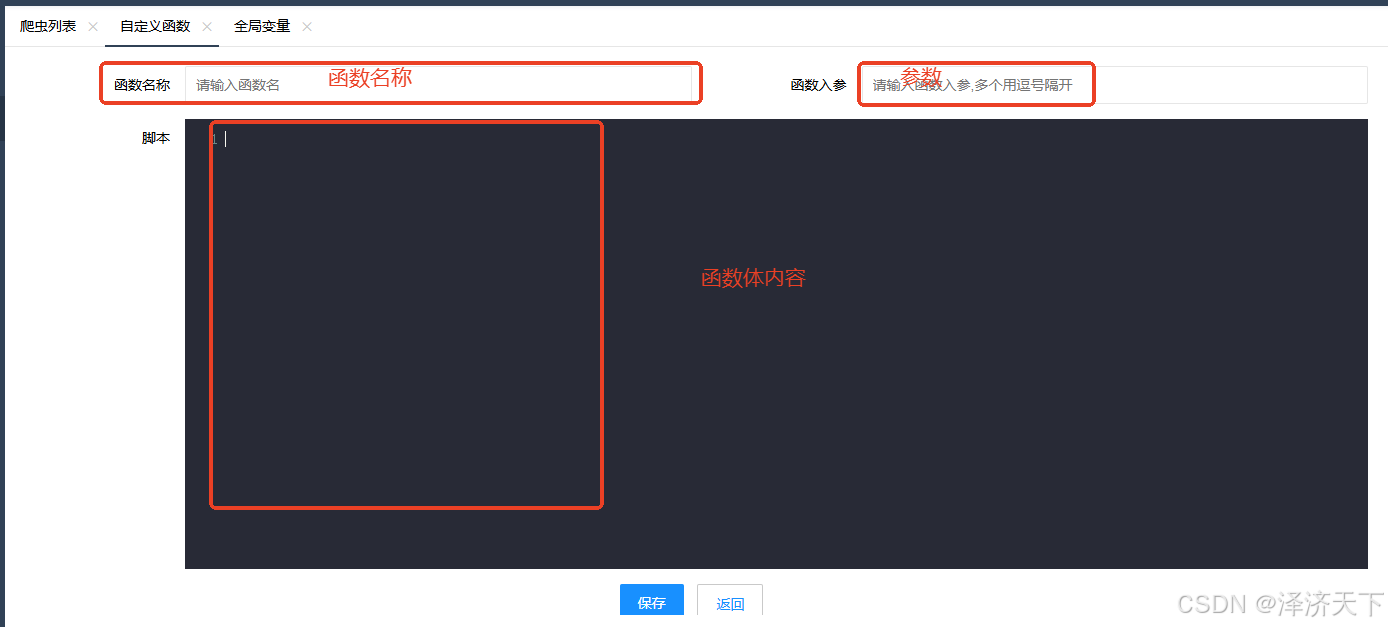
非常清晰,函数名称、参数、函数体。这里的函数体使用js语法,支持function调用。
实现上述需求的函数体示例如下:
if(!wind_speed){return '--'}//如果带有单位,先替换再处理, 也可以使用其他方式取出数值if(wind_speed.indexOf('m/s')!==-1){wind_speed = wind_speed.replace('m/s', '')wind_speed = parseFloat(wind_speed)}if (wind_speed < 1.5) {return 1}if (wind_speed < 3.3) {return 2}if (wind_speed < 5.4) {return 3}if (wind_speed < 7.9) {return 4}if (wind_speed < 10.7) {return 5}// ... 省略其他判断和返回逻辑return 'unknow level'
以上函数,假设名称为convert_wind_level, 入参为风速wind_speed,可以为数字或者带有m/s的字符串。
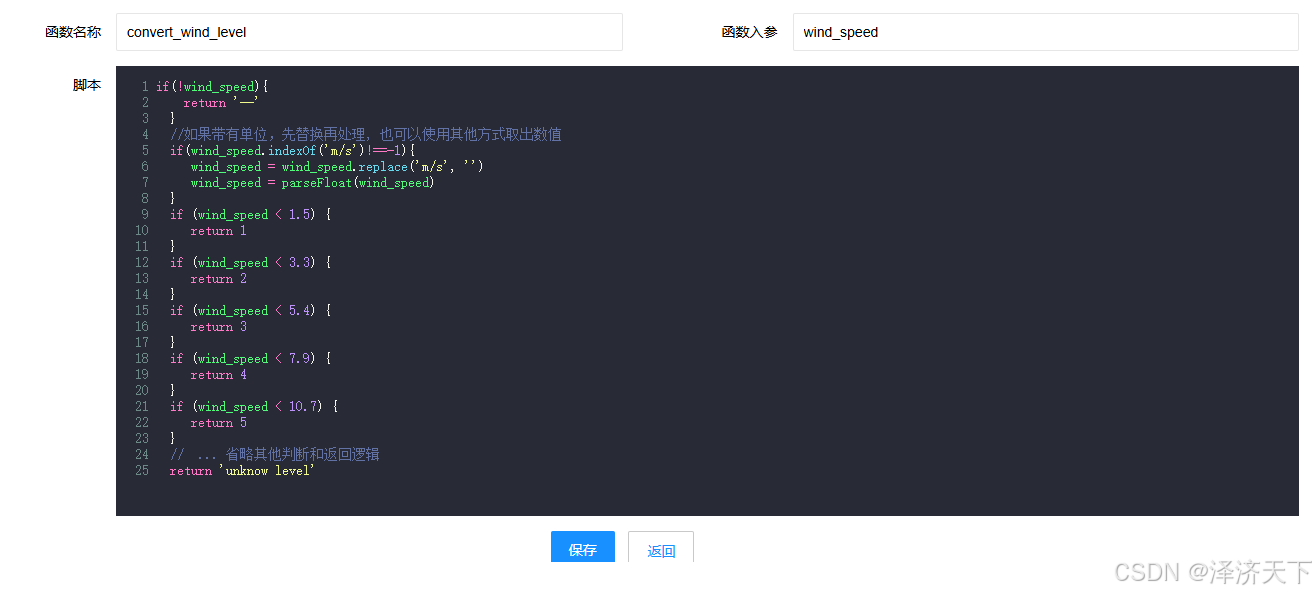
验证
新建爬虫,使用convert_wind_level,传入参数即可看到返回值。

总结
以上是本文所有内容了,主要是回答网友疑问,介绍了正则表达式和自定义函数的用法、语法规则以及示例等。
针对以上内容或者相关博客有任何疑问,欢迎留言讨论。
创作不易,欢迎一键三连~~~






