表数据如下:
数据格式为json:
{"username":"张三","score":95}
{"username":"李四","score":76}
{"username":"赵本山","score":92}
{"username":"王五","score":76}
{"username":"赵六","score":62}
{"username":"赵六1","score":62}
{"username":"赵六2","score":26}
{"username":"赵六3","score":89}
{"username":"赵六4","score":77}
思路:
两种方式思路都一样:
拿到 score 去进行 if 判断:成绩大于90为优、大于80为良、大于60为中,不及格为差
方式一:
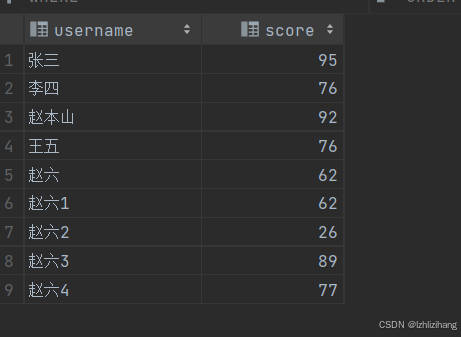
建表和加载数据:
hive 中有 json serde ,可以解析 json 数据到表中:
重要的一点:建表字段与 json 数据的 key 值需要一样
create table t6(username string,score int
)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';load data local inpath '/home/hivedata/t6.txt' into table t6;
json serde 模块有两种:一个是第三方的,一个是hive自带的
-- org.openx.data.jsonserde.JsonSerDe 这个类是第三方的类,所以要导入包
row format serde 'org.openx.data.jsonserde.JsonSerDe';-- hive自带的:
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';
加载到表中如下图:
答案代码:
with t1 as (select`if`(score >= 90 ,'优',`if`(score < 90 and score >= 80, '良',`if`(score < 80 and score >= 60, '中',`if`(score < 60, '差',0)))) leval
from t6
)
select leval,count(*) from t1 group by leval;
方式二:
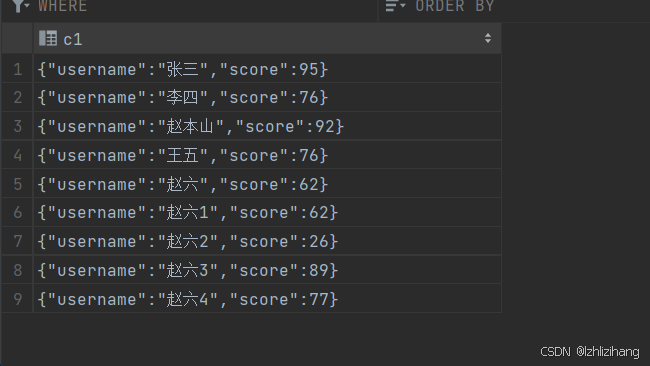
建表和加载数据:
直接将 json 数据导入到表中
create table t6(c1 string
);load data local inpath '/home/hivedata/t6.txt' into table t6;
加载到表中如下图:
通过 hive 自带的函数 get_json_object(c1,‘$.score’),将字段c1 传进去,拿到 username 和 score
答案代码:
with t as (select get_json_object(c1,'$.username') username,get_json_object(c1,'$.score') score,`if`(get_json_object(c1,'$.score') > 90,'优',if(get_json_object(c1,'$.score')>=80,'良',`if`(get_json_object(c1,'$.score')>=60,'中','不及格')) ) grade
from t6
)
select grade,count(1) rs from t group by grade ;






