1. 核心思想
QLoRA (Quantized Low-Rank Adaptation) 是一种 高效的微调方法,它在保持 LoRA 的参数效率基础上,通过 量化预训练模型到 4-bit 精度 来进一步减少显存占用。其核心思想是:
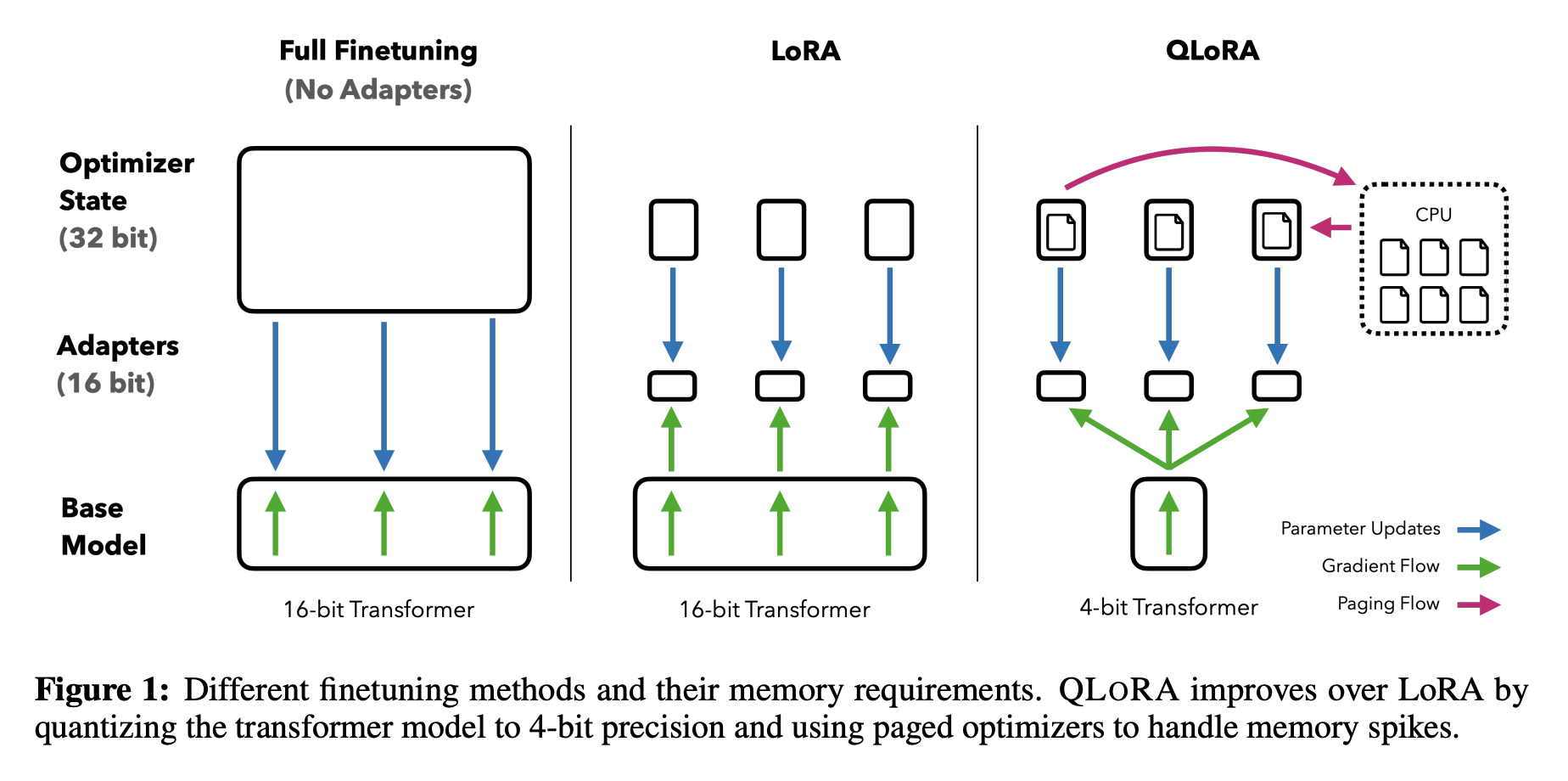
- 结合 LoRA: 沿用 LoRA 的方法,冻结原始预训练模型的权重,只训练少量新增的低秩适应器。
- 量化基底模型: 将冻结的预训练模型权重从高精度(如 FP16/BF16)量化到 4-bit NormalFloat (NF4) 格式,大大减少了显存占用。
- 双量化 (Double Quantization): 对量化常数本身进行再次量化,进一步节省内存。
- 分页优化器 (Paged Optimizers): 引入类似 CPU/GPU 内存分页的机制,有效管理优化器状态,防止显存溢出。
即基于 LoRA,对
base模型进行量化,并对量化参数再进行量化,同时引入分页优化器来管理优化器
2. 原理详解与关键技术
原理此处为作者搜集资料
QLoRA 在 LoRA 的基础上,引入了三项关键技术,使其能够在更低的显存下微调更大的模型:
2.1. 4-bit NormalFloat (NF4) 量化
- 背景: 传统的 4-bit 量化(如 INT4)通常是非线性的或需要复杂的校准。QLoRA 引入了一种新的数据类型 NormalFloat (NF4)。
- 原理:
- NF4 是一种信息理论最优的 4-bit 量化数据类型,其设计灵感来源于正态分布。
- 它通过将量化水平点均匀分布在标准正态分布的量化分位数上,能够更有效地表示神经网络权重中常见的正态分布特性。
- 步骤:
- 分位数估计: 对于给定的权重张量,估计其 2k 个分位数(例如,对于 4-bit,就是 16 个分位数)。
- 归一化: 将权重归一化到 [−1,1] 范围内。
- 映射: 将归一化后的浮点权重值映射到这 16 个分位数对应的 4-bit 整数索引上。
- 反量化: 推理或梯度计算时,将 4-bit 整数反量化回浮点值,通常是 BF16。
- 优势:
- 相比标准 INT4,NF4 在量化性能上更优,精度损失更小。
- 适用于预训练模型的权重,因为它不需要动态量化,权重是固定的。
2.2. 双量化 (Double Quantization, DQ)
- 背景: 在 4-bit 量化中,每个块的权重都需要一个量化常数(
quant_scale和quant_offset)。这些量化常数本身也是浮点数,且数量不少,也会占用显存。 - 原理:
- QLoRA 提出对这些 量化常数进行再次量化。
- 例如,如果原始 4-bit 量化常数是 FP32,可以将其量化到 8-bit float (Float8) 精度。
- 通过对量化常数进行二次量化,可以节省约 0.37 bits/参数的内存。
- 优势: 进一步减少了非权重参数(如量化常数)的内存占用,提升了显存效率。
2.3. 分页优化器 (Paged Optimizers)
- 背景: 训练深度学习模型时,优化器状态(如 Adam 的动量和方差项)会占用大量显存,尤其是在微调大模型时。对于 Adam 优化器,其状态通常是模型参数数量的两倍。
- 原理:
- QLoRA 借鉴了操作系统中的 分页 (Paging) 机制。
- 它将优化器状态从 GPU 显存分页到 CPU 内存(甚至硬盘)。
- 只在需要时(即当前批次需要更新的参数对应的优化器状态),才将相关的优化器页加载到 GPU 显存中。
- 优势:
- 有效解决了优化器状态的显存瓶颈,使得微调非常大的模型(如 65B 参数)成为可能。
- 避免了显存不足 (OOM) 错误,提高了微调的鲁棒性。
3. 优点
- 极高的显存效率: 能够在消费级 GPU 上微调数千亿参数的模型(例如,QLoRA 可以在 24GB 显存的 RTX 3090 上微调 65B 参数的模型)。
- 性能接近全参数微调: 由于 LoRA 适配器仍然是全精度训练,且基底模型通过 NF4 量化保持了高精度,QLoRA 能够实现与全参数微调相似的性能。
- 训练速度更快: 尽管有量化和分页的开销,但由于参数量大幅减少,整体训练速度仍然比全参数微调快得多。
- 兼容性好: 可以应用于现有的 LoRA 代码库,只需在加载模型时指定量化参数。
- 无需多 GPU: 很多情况下,单张消费级 GPU 即可完成大模型微调,降低了硬件门槛。
4. 缺点
- 量化引入的微小精度损失: 尽管 NF4 表现优秀,但量化始终会带来一定的信息损失,可能在某些极端任务上导致性能略微下降。
- 推理速度提升有限: QLoRA 主要优化训练时的显存和计算效率,对于推理阶段,由于基底模型仍然需要反量化到 BF16/FP16 才能参与计算,因此推理速度提升不如纯 INT4/INT8 推理。
- 实现复杂性: 内部实现涉及到复杂的量化、反量化和分页机制,对开发者来说,从头实现较为复杂(但通常我们会使用现成的库)。
**5. 代码实现 **
或者通过 LlamaFactory页面进行QLoRA微调模型
QLoRA 通常通过 Hugging Face 的 peft 库和 bitsandbytes 库来实现,而不是从头手写。
环境准备:
pip install torch transformers peft bitsandbytes accelerate datasets
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
from datasets import load_dataset # 用于加载数据# --- 1. 定义量化配置 (4-bit NF4) ---
# BitsAndBytesConfig 是 transformers 库中用于配置量化参数的类
# load_in_4bit=True: 启用 4-bit 量化
# bnb_4bit_quant_type="nf4": 指定使用 NormalFloat 4-bit 量化
# bnb_4bit_use_double_quant=True: 启用双量化
# bnb_4bit_compute_dtype=torch.bfloat16: 计算时使用 BF16 精度,确保精度
quantization_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=torch.bfloat16, # 在训练过程中,量化权重会动态反量化到此精度进行计算
)# --- 2. 加载预训练模型和分词器 (启用 4-bit 量化) ---
# 这里以 Meta-Llama/Llama-2-7b-hf 为例
model_id = "meta-llama/Llama-2-7b-hf" # 替换为你要微调的模型ID# AutoModelForCausalLM 会根据 quantization_config 加载一个 4-bit 量化模型
# 注意:需要 Hugging Face Hub token 才能访问 Llama-2
model = AutoModelForCausalLM.from_pretrained(model_id,quantization_config=quantization_config,device_map="auto" # 自动将模型分配到可用的GPU设备
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Llama tokenizer 通常没有 pad token,需要手动设置
tokenizer.pad_token = tokenizer.eos_tokenprint(f"Model loaded successfully in 4-bit: {model.dtype}")
# 检查模型参数类型,大部分参数应为 torch.uint8 (量化后的 4-bit)# --- 3. 为 k-bit 训练准备模型 (Paging Optimizers) ---
# prepare_model_for_kbit_training 会做几件事:
# - 冻结除 LoRA 适配器之外的所有参数
# - 将 LayerNorm 层转换为 float32 (通常是为了稳定训练)
# - 启用梯度检查点 (gradient checkpointing),进一步节省显存
# - 启用 Paged Optimizers (通过 bitsandbytes 库的集成)
model.gradient_checkpointing_enable() # 启用梯度检查点,但会增加计算时间
model = prepare_model_for_kbit_training(model)# --- 4. 配置 LoRA 适配器 ---
# r: 低秩矩阵的秩,越小越节省参数,但可能影响性能
# lora_alpha: LoRA 层的缩放因子
# target_modules: 指定哪些层需要添加 LoRA 适配器,通常是 atención 机制中的 q, k, v 投影层
# lora_dropout: LoRA 层的 dropout
# bias: 是否对 LoRA 层的 bias 进行微调
# task_type: 任务类型,例如 CAUSAL_LM (因果语言模型)
lora_config = LoraConfig(r=16, # 秩,可以根据需要调整lora_alpha=32, # LoRA 缩放因子target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # Llama-2 的 QKV O 投影层lora_dropout=0.05,bias="none",task_type="CAUSAL_LM"
)# --- 5. 获取 PEFT 模型 ---
# get_peft_model 会将 LoRA 适配器添加到模型中
model = get_peft_model(model, lora_config)print("\n--- LoRA Model Structure ---")
# 打印可训练参数数量和比例
model.print_trainable_parameters()# --- 6. 准备数据进行微调 ---
# 示例:加载一个小型数据集
dataset = load_dataset("Abirate/english_quotes")
# 对数据集进行简单的分词和格式化
def tokenize_function(examples):return tokenizer(examples["quote"], truncation=True, max_length=128)tokenized_dataset = dataset.map(tokenize_function, batched=True)
# 这里通常需要对数据集进行更复杂的处理,如分组文本、创建输入/标签对等# --- 7. 配置训练器 (使用 Trainer API) ---
from transformers import TrainingArguments, Trainer# 定义训练参数
training_args = TrainingArguments(output_dir="./qlora_results",num_train_epochs=1, # 示例:只训练一个 epochper_device_train_batch_size=2, # 批次大小gradient_accumulation_steps=4, # 梯度累积步数,模拟更大批次learning_rate=2e-4,fp16=True, # 启用 FP16 混合精度训练 (bitsandbytes compute_dtype 会覆盖)logging_steps=10,save_strategy="epoch",report_to="none" # 可以配置为 "wandb", "tensorboard" 等
)# 创建 Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset["train"],tokenizer=tokenizer,
)# --- 8. 开始微调 ---
print("\n--- Starting QLoRA Fine-tuning ---")
trainer.train()print("\n--- Fine-tuning Complete ---")# --- 9. 保存微调后的 LoRA 适配器 ---
# 仅保存 LoRA 适配器,不保存整个大模型,因此文件很小
# model.save_pretrained("./qlora_adapter")
# tokenizer.save_pretrained("./qlora_adapter")# --- 10. 加载和合并 LoRA 适配器 (可选,用于推理或部署) ---
# from peft import PeftModel
# base_model = AutoModelForCausalLM.from_pretrained(
# model_id,
# torch_dtype=torch.bfloat16, # 或 torch.float16
# device_map="auto"
# )
# loaded_model = PeftModel.from_pretrained(base_model, "./qlora_adapter")
# merged_model = loaded_model.merge_and_unload() # 合并 LoRA 权重到基底模型
# merged_model.save_pretrained("./merged_model")
# tokenizer.save_pretrained("./merged_model")
代码解释:
-
BitsAndBytesConfig: 核心配置类,用于指定 4-bit 量化类型 (nf4)、是否使用双量化 (True) 以及计算时的数据类型 (torch.bfloat16)。 -
AutoModelForCausalLM.from_pretrained(..., quantization_config=...): 当quantization_config被传入时,transformers库会自动使用bitsandbytes库将模型加载为 4-bit 量化形式。 -
- 这个函数是 QLoRA 的重要组成部分。它会执行以下操作:
prepare_model_for_kbit_training(model)- 将所有非量化层(如 LayerNorm)转换为
torch.float32以保持训练稳定性。 - 启用梯度检查点 (Gradient Checkpointing),通过牺牲计算速度来大幅节省显存。
- 与
bitsandbytes集成,启用分页优化器,以管理优化器状态。
-
LoraConfig: 定义 LoRA 适配器的参数,如秩r、缩放因子lora_alpha和要注入 LoRA 适配器的目标模块target_modules。 -
get_peft_model(model, lora_config): 将 LoRA 适配器注入到 4-bit 量化模型中,并返回一个PeftModel对象,该对象仅允许训练 LoRA 适配器的参数。 -
model.print_trainable_parameters(): 这个 PEFT 函数会打印出当前模型中可训练参数的数量和占总参数的比例,你会发现这个比例非常小。 -
Trainer: Hugging Face 的训练器 API,简化了训练循环的编写。fp16=True会启用混合精度训练,这里bitsandbytes的compute_dtype会决定实际的计算精度。




