前沿
“AI生成的东西不对劲”、“知识库更新了,模型还是老黄历”、“大模型成本高得吓人”…这些是不是让你在Spring AI的应用开发中头秃到怀疑人生?别怕,RAG就是为你量身打造的“解药”!它就像给AI装了个“搜索引擎的脑子”,让它每次回答前都能“查查资料”,确保输出既聪明又靠谱!
在这里,我们将手把手带你把RAG这套“组合拳”完美融入你的Spring AI项目。从搭建高效的向量数据库,到设计巧妙的检索逻辑,再到与大模型的精妙对接,每一步都踩在实战的鼓点上。你将亲手打造出那个你一直梦想的应用——既保留了大模型的创造力,又拥有了知识库的严谨性!
但我们不止于此!我们深知,真正的高手不仅要会用“招式”,更要懂“内功”。所以,我们将带你潜入Spring AI的源码深处,像侦探一样追踪数据流,像工程师一样剖析算法逻辑。你将明白,为什么RAG在这里能如此高效,瓶颈可能出现在哪里,甚至能预判未来的优化方向!这,才是让Spring AI应用真正“长治久安”的硬核之道!准备好了吗?让我们一起终结那些恼人的AI痛点!
向量、文本向量化、向量模型、向量数据库
向量是什么?
在数学和物理学中,向量是一种既有大小又有方向的量。你可以把它想象成一个带箭头的线段,箭头所指的方向代表向量的方向,线段的长度则代表向量的大小(也称为向量的模或长度)。
表示方式: 向量可以用字母(如a、b、c)表示,也可以用起点和终点字母加箭头表示(如→AB,起点A在前,终点B在后)。
基本性质: 向量包含大小和方向两个要素,而与之相对的是标量,标量只有大小没有方向(如温度、质量等)。
应用场景: 在物理学中,力、位移、速度等都是典型的向量;在计算机科学中,向量常用于表示数据点,尤其是在机器学习和自然语言处理中。
文本向量化是什么?
文本向量化是将文本数据转换为数值向量的过程,目的是让计算机能够理解和处理文本内容。由于计算机无法直接理解文本,文本向量化是实现自然语言处理(NLP)任务的基础。
核心作用: 将文本映射到高维空间中的向量,每个维度代表文本的某种特征(如词频、语义等),从而支持相似度计算和模型训练。
常见方法:
词袋模型(Bag of Words): 统计文本中每个词的出现频率,生成向量。
TF-IDF: 结合词频和逆文档频率,突出重要词的影响。
词嵌入模型(如Word2Vec、BERT): 将词语或句子映射到连续的向量空间,保留语义信息。
应用场景: 文本相似度计算、文本分类、情感分析等。
向量模型是什么?
向量模型是一种利用向量表示数据,并通过向量之间的相似性或距离进行计算和检索的模型。它是机器学习和深度学习中的核心工具,特别是在处理非结构化数据(如文本、图像)时表现突出。
基本概念: 向量模型将数据(如文本、图像)转化为高维向量,每个向量代表数据在特定特征空间中的位置。
关键技术:
相似度计算: 如余弦相似度、欧氏距离等,用于衡量向量之间的接近程度。
降维技术: 如PCA、t-SNE,用于减少向量维度,提高计算效率。
应用场景: 推荐系统、图像识别、语义搜索等。
向量数据库是什么?
向量数据库是一种专门用于存储和检索高维向量数据的数据库系统,它通过高效的相似性搜索技术,为大规模非结构化数据的处理提供了支持。
核心功能:
存储向量数据: 将文本、图像等数据通过向量模型转换为向量后存储。
相似性搜索: 通过近似最近邻(ANN)算法(如HNSW、LSH)快速找到与查询向量最相似的数据。
索引优化: 利用KD树、Ball Tree等索引结构加速检索。
常见向量数据库:
Milvus: 开源的分布式向量数据库,支持多种索引算法。
Pinecone: 云原生向量数据库,提供高性能检索。
FAISS: Facebook AI 开发的向量检索库,适合大规模数据。
应用场景: 推荐系统、语义搜索、图像检索、异常检测等。
向量生成
千问模型列表https://help.aliyun.com/zh/model-studio/getting-started/models
配置向量模型:
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.5.0</version><relativePath /> <!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>spring-ai-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>spring-ai-demo</name><description>spring-ai-demo</description><url/><licenses><license/></licenses><developers><developer/></developers><scm><connection/><developerConnection/><tag/><url/></scm><properties><java.version>17</java.version><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><spring-ai.version>1.0.0</spring-ai.version><tinylog.version>2.7.0</tinylog.version><openai.version>1.0.3</openai.version><spring-ai-alibaba.version>1.0.0-M6.1</spring-ai-alibaba.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><exclusion><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-logging</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.tinylog</groupId><artifactId>slf4j-tinylog</artifactId><version>${tinylog.version}</version></dependency><dependency><groupId>org.tinylog</groupId><artifactId>tinylog-impl</artifactId><version>${tinylog.version}</version></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId><exclusions><exclusion><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai</artifactId></exclusion></exclusions></dependency><!-- <dependency>--><!-- <groupId>org.springframework.ai</groupId>--><!-- <artifactId>spring-ai-zhipuai</artifactId>--><!-- <version>${spring-ai.version}</version>--><!-- </dependency>--><!-- <dependency>--><!-- <groupId>org.springframework.ai</groupId>--><!-- <artifactId>spring-ai-qianfan</artifactId>--><!-- <version>${spring-ai.version}</version>--><!-- </dependency>--><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter-dashscope</artifactId><version>1.0.0.2</version></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId><exclusions><exclusion><groupId>co.elastic.clients</groupId><artifactId>elasticsearch-java</artifactId></exclusion></exclusions></dependency><dependency><groupId>co.elastic.clients</groupId><artifactId>elasticsearch-java</artifactId><version>8.15.5</version></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>${spring-ai.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><finalName>${name}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><executions><execution><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build><repositories><repository><id>spring-snapshots</id><name>Spring Snapshots</name><url>https://repo.spring.io/snapshot</url><releases><enabled>false</enabled></releases></repository><repository><name>Central Portal Snapshots</name><id>central-portal-snapshots</id><url>https://central.sonatype.com/repository/maven-snapshots/</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories></project>spring:ai:openai:api-key: sk-xxbase-url: https://api.deepseek.comchat:enabled: trueoptions:model: deepseek-chatzhipuai:api-key: xxbase-url: https://open.bigmodel.cn/api/paas/chat:options:model: glm-4v-flashdash scope:apiKey: sk-xxbase-url: https://dashscope.aliyuncs.comchat:options:model: gwen-plusembedding:options:model: text-embedding-v3
//通义千问 为啥这个名字 词不达意
@Resource
private DashScopeChatModel dashScopeChatModel;@Resource
private DashScopeEmbeddingModel dashScopeEmbeddingModel;@GetMapping("/embedding")
public float[] dashScopeEmbeddingModel(@RequestParam String message) {return dashScopeEmbeddingModel.embed(message);
}

向量相似度
向量相当于就是坐标点,如果两个坐标点靠得近,那么就表示这两个向量相似,所以,如果两句话对应的向量相似,那么就表示这两句话语义比较相似,当然这中间最关键的就是向量模型,因为向量是它生成的,向量模型也是经过大量机器学习训练之后产生的,向量模型效果越好,就表示它对于自然语言理解的程度越好,同时也就表示它生成出来的向量越准备,越能反映出语义的相似度。
Docker安装ES
docker pull elasticsearch:8.17.3
国内镜像可能不用了,参考:https://www.coderjia.cn/archives/dba3f94c-a021-468a-8ac6-e840f85867ea
比如:
docker pull docker.1ms.run/elasticsearch:8.17.3
启动ES
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e "ELASTIC_PASSWORD=123456" -e "xpack.security.http.ssl.enabled=false" docker.1ms.run/elasticsearch:8.17.3
然后浏览器访问:http://localhost:9200/ (主要一定得是http,不能是https,要支持https得单独有证书)
用户名/密码为:elastic/123456
Spring AI整合ES作为向量数据库
先添加starter
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-elasticsearch-store-spring-boot-starter</artifactId>
</dependency>
然后配置es的url和用户名密码:
spring:elasticsearch:uris: xx.xx.xx.xx:9200username: elasticpassword: xxxxxxx
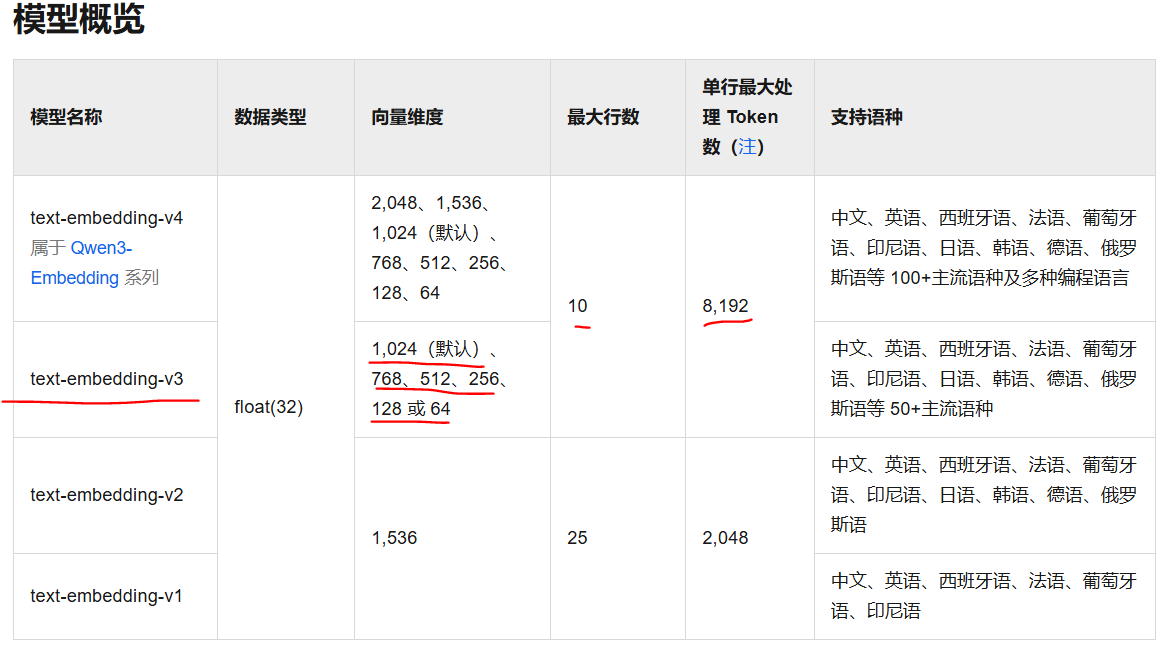
配置vectorstore,text-embedding-v3负责生成向量数据,es负责存储向量数据,而vectorstore就是两者的桥梁,负责创建index,负责调用向量模型生成向量数据,负责存到es中:
注意向量维度为1024。
spring:ai:dash scope:apiKey: sk-xxbase-url: https://dashscope.aliyuncs.comchat:options:model: gwen-plusembedding:options:model: text-embedding-v3vectors tore:elasticsearch:dimensions: 1024initialize-schema: trueindex-name: spring-ai-demo-indexsimilarity: cosineelasticsearch:uris: xx.xx.xx.xx:9200username: elasticpassword: xxxxxx
ES常用API
查看所有索引
curl -u elastic:123456 -X GET "http://localhost:9200/_cat/indices?v"
删除指定索引
curl -u elastic:123456 -X DELETE "http://localhost:9200/spring-ai-demo-index"
查看索引数据
curl -u elastic:123456 -X GET "http://localhost:9200/spring-ai-demo-index/_search?pretty"
文本向量化
qa.txt
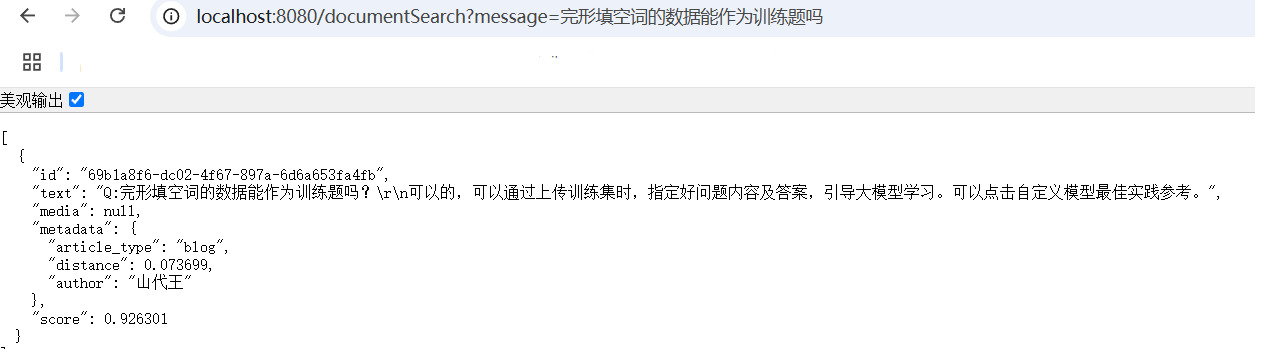
Q:完形填空词的数据能作为训练题吗?
可以的,可以通过上传训练集时,指定好问题内容及答案,引导大模型学习。可以点击自定义模型最佳实践参考。Q:目前阿里云百炼只能训练文字吗?图片可以训练吗?
目前已支持图片训练,qwen-vl-plus模型支持训练微调。Q:使用高阶模型微调,低阶模型做能力下沉,是想做蒸馏吗?
该技术通过微调高阶模型获取强大知识,然后将其转移至低阶模型,实现模型压缩与性能优化,使得低阶模型在保持小巧、高效的同时,获得接近或超越高阶模型的性能。Q:所谓大模型参数是怎么存储的?
可以通过魔搭下载模型,会有模型结构的JSON,可以参考JSON内容。一般情况下用开源的Python组件,去解析组件,会有向量信息,可能理解会有点难度。但是可以了解存储过程。Q:语料数据集的多样性怎么定义?
语料数据集的多样性是指其在语言特征、内容主题、文本类型、写作风格、语言变体、作者背景、时间跨度等多个维度上体现出的丰富程度和差异性,旨在真实反映语言的实际使用情况,提升NLP模型的泛化能力和对多元应用场景的适应性。Q:个人使用大模型训练时,qwen-turbo和qwen-max应该怎么选?
qwen-turbo注重速度与资源效率,适合对响应速度和部署便捷性有较高要求的场景;qwen-max则聚焦顶级性能与全面知识,适用于对模型精度和处理复杂任务能力有严格要求的环境。其中qwen-turbo的费用要比qwen-max低。根据您的具体需求和条件权衡,选择最适合自己的模型版本。也可以查看模型介绍:通义千问介绍了解具体差异。Q:模型训练中的自定义模型怎么上传?
模型调优中的自定义模型是指您已训练完成的模型,想要二次训练时,所选择的自定义模型。若是您自己在本地训练的模型不支持上传。Q:训练完的开源模型是否支持导出?
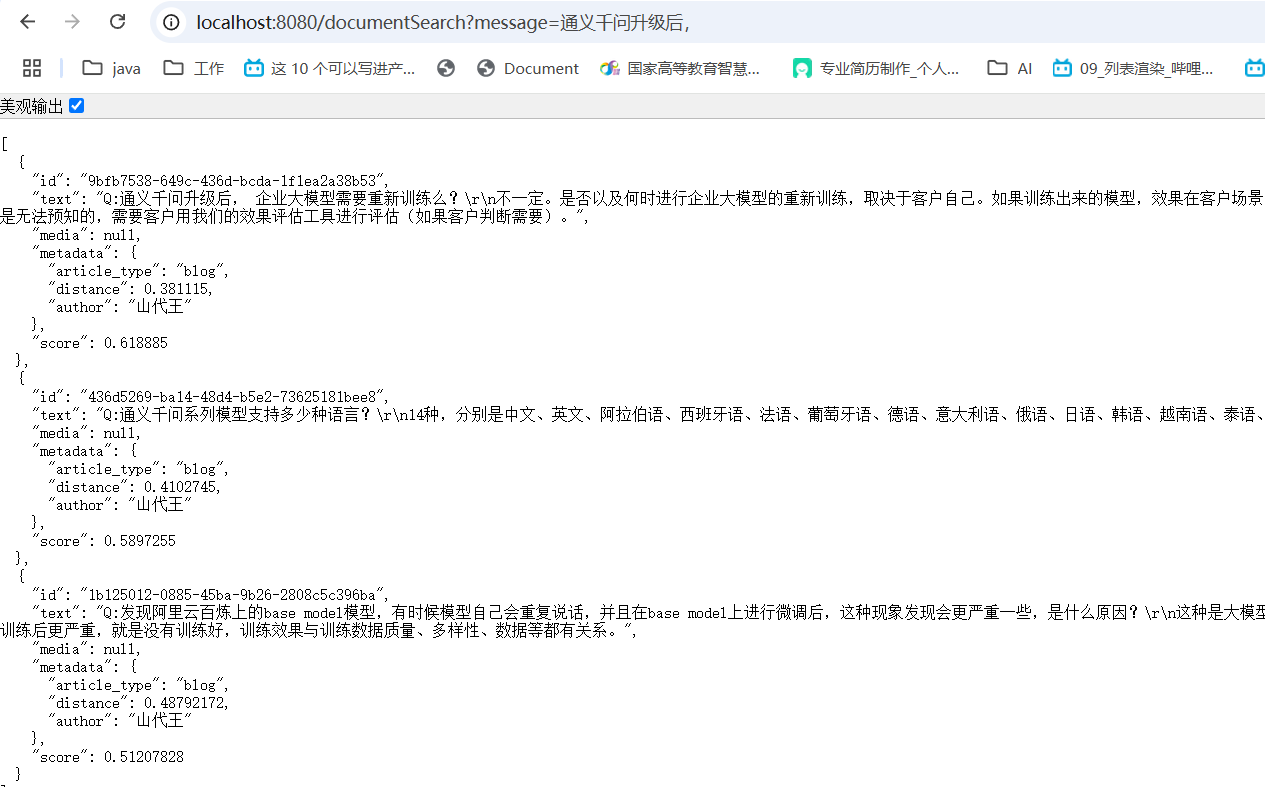
目前不支持。Q:通义千问系列模型支持多少种语言?
14种,分别是中文、英文、阿拉伯语、西班牙语、法语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语、印度尼西亚语。Q:当前模型可以对接结构化数据吗?比如MySQL和hive等。
当前不支持。但已经在开发中,优先对接RDS服务。Q:通义千问升级后, 企业大模型需要重新训练么?
不一定。是否以及何时进行企业大模型的重新训练,取决于客户自己。如果训练出来的模型,效果在客户场景中表现良好,就没必要再训练一遍。基模型的升级,在客户的应用场景会带来什么样的变化,是无法预知的,需要客户用我们的效果评估工具进行评估(如果客户判断需要)。Q:发现阿里云百炼上的base model模型,有时候模型自己会重复说话,并且在base model上进行微调后,这种现象发现会更严重一些,是什么原因?
这种是大模型的幻觉问题,当你输入的问题大模型没有知识回答的时候就可能出现。如果在base model上训练后更严重,就是没有训练好,训练效果与训练数据质量、多样性、数据等都有关系。Q我们现在是训练垂直领域的模型,知识都是安全领域的数据。请问下如果在SFT阶段,不混入通义原始的SFT数据,我们喂的垂直领域的数据越多,是不是越容易过拟合,遗忘了原有的知识。而且在我们这个领域的回答也会重复啰嗦。请问有什么最佳实践建议吗?
(1)只使用领域数据进行SFT训练,会遗忘大模型原有的通用知识。
(2)如何准备好的领域SFT数据:
任务定义要清晰,典型的不清晰是指同一个输入,对应模棱两可的两种答案。
数据质量、准确率要高,答案一定要是准确回答当前问题的,简单明了,最好不要有冗余废话。
多样性,如你所说,同一语义可以用丰富的prompt,避免学到单一prompt的模式信息。训练数据一般没法一次就做好,一般是多次迭代优化,数据很重要,构建成本也比较高,需要逐步迭代质量、多样性这些维度。Q:在训练的时候发现,数据量少的情况下,比如100条左右,循环次数越大效果越好。但在数据量多的情况下比如1000条以上,循环次数越多越容易过拟合。请问这个超参配置和数据配比,有什么最佳实践?
数据在质量保证的前提下,越多越好,尤其是对于难的任务。循环次数等这些超参数,不同任务可能不一样,没有具体规律,还是要在您的任务上实验下,我们一般在难的任务上,几千条数据的情况,也要训练20轮左右。另外,大模型的过拟合不能只看loss,loss上显示了过拟合,实际效果可能变好,这与传统模型不同,还是要人工看效果。Q:请问Qwen2、千问-MAX等模型的文字生成速度对所有用户都是固定的吗,有没有调速的途径?
这个速度不是固定的,跟线上资源和用户所有请求有关。Q:咱们模型限流触发后,一般需要等多长时间再次尝试呢?
这个就和具体限流值相关。比如有的客户的限流是120qpm,执行2次请求每1秒,那比如0.2秒的时候提交了2次请求,再提交就会被限流,然后需要等0.8秒
package com.example.controller;import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingModel;
import com.example.service.DocumentService;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController
public class DashScopeController {@Resourceprivate ElasticsearchVectorStore elasticsearchVectorStore;@Autowiredprivate DocumentService documentService;@Resourceprivate DashScopeChatModel dashScopeChatModel;@Resourceprivate DashScopeEmbeddingModel dashScopeEmbeddingModel;@GetMapping("/chat")public String dashScopeChatModel(@RequestParam String message) {return dashScopeChatModel.call(new UserMessage(message));}@GetMapping("/embedding")public float[] dashScopeEmbeddingModel(@RequestParam String message) {return dashScopeEmbeddingModel.embed(message);}@GetMapping("/documentEmbedding")public List<Document> documentEmbedding() {return documentService.loadText();}} public List<Document> split(Document document) {List<Document> documents = new ArrayList<>();String[] parts = split(document.getText());for (String part : parts) {documents.add(Document.builder().text(part).build());}return documents;}public String[] split(String text) {Pattern pattern = Pattern.compile("(\\R{2,})", Pattern.MULTILINE);return pattern.split(text);//return text.split("\\s*\\R\\s*\\R\\s*");}

相似度查询
@GetMapping("/documentSearch")
public List<Document> documentSearch(@RequestParam String message) {return documentService.search(message);}
public List<Document> search(String message){SearchRequest searchRequest = SearchRequest.builder().query(message).topK(1).similarityThreshold(0.1).filterExpression("author in ['山代王', 'test'] && 'article_type' == 'blog'").build();return vectorStore.similaritySearch(searchRequest);}
RAG
@GetMapping("/ragChat")
public String ragChat(@RequestParam String message) {Logger.info(" message:"+message);ChatClient.Builder builder = ChatClient.builder(dashScopeChatModel);ChatClient chatClient = builder.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build()).build();// 向量搜索List<Document> documentList = documentService.search(message);// 提示词模板PromptTemplate promptTemplate = new PromptTemplate("{userMessage}\n\n 用以下信息回答问题:\n {contents}");// 组装提示词Prompt prompt = promptTemplate.create(Map.of("userMessage", message, "contents", documentList));// 调用大模型return chatClient.prompt(prompt).call().content();
}

源码分析
/** Copyright 2023-2024 the original author or authors.** Licensed under the Apache License, Version 2.0 (the "License");* you may not use this file except in compliance with the License.* You may obtain a copy of the License at** https://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.springframework.ai.vectorstore;import java.util.Objects;import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.ai.vectorstore.filter.FilterExpressionBuilder;
import org.springframework.ai.vectorstore.filter.FilterExpressionTextParser;
import org.springframework.lang.Nullable;
import org.springframework.util.Assert;/*** 相似性搜索请求。使用 {@link SearchRequest#builder()} 创建 {@link SearchRequest} 实例。** @author Christian Tzolov* @author Thomas Vitale* @author Ilayaperumal Gopinathan*/
public class SearchRequest {/*** 接受所有搜索分数的相似性阈值。阈值为0.0表示接受任何相似性或禁用相似性阈值过滤。* 阈值为1.0表示需要完全匹配。*/public static final double SIMILARITY_THRESHOLD_ACCEPT_ALL = 0.0;/*** 返回的相似结果数量的默认值。*/public static final int DEFAULT_TOP_K = 4;/*** 默认值为空字符串。*/private String query = "";private int topK = DEFAULT_TOP_K;private double similarityThreshold = SIMILARITY_THRESHOLD_ACCEPT_ALL;@Nullableprivate Filter.Expression filterExpression;/*** 复制现有的 {@link SearchRequest.Builder} 实例。* @param originalSearchRequest 要复制的 {@link SearchRequest} 实例。* @return 返回新的 {@link SearchRequest.Builder} 实例。*/public static Builder from(SearchRequest originalSearchRequest) {return builder().query(originalSearchRequest.getQuery()).topK(originalSearchRequest.getTopK()).similarityThreshold(originalSearchRequest.getSimilarityThreshold()).filterExpression(originalSearchRequest.getFilterExpression());}public SearchRequest() {}protected SearchRequest(SearchRequest original) {this.query = original.query;this.topK = original.topK;this.similarityThreshold = original.similarityThreshold;this.filterExpression = original.filterExpression;}public String getQuery() {return this.query;}public int getTopK() {return this.topK;}public double getSimilarityThreshold() {return this.similarityThreshold;}@Nullablepublic Filter.Expression getFilterExpression() {return this.filterExpression;}public boolean hasFilterExpression() {return this.filterExpression != null;}@Overridepublic String toString() {return "SearchRequest{" + "query='" + this.query + '\'' + ", topK=" + this.topK + ", similarityThreshold="+ this.similarityThreshold + ", filterExpression=" + this.filterExpression + '}';}@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (o == null || getClass() != o.getClass()) {return false;}SearchRequest that = (SearchRequest) o;return this.topK == that.topK && Double.compare(that.similarityThreshold, this.similarityThreshold) == 0&& Objects.equals(this.query, that.query)&& Objects.equals(this.filterExpression, that.filterExpression);}@Overridepublic int hashCode() {return Objects.hash(this.query, this.topK, this.similarityThreshold, this.filterExpression);}/*** 创建SearchRequest实例的构建器。* @return 构建器。*/public static Builder builder() {return new Builder();}/*** SearchRequest构建器。*/public static class Builder {private final SearchRequest searchRequest = new SearchRequest();/*** @param query 用于嵌入相似性比较的文本。* @return 当前构建器。*/public Builder query(String query) {Assert.notNull(query, "查询不能为空。");this.searchRequest.query = query;return this;}/*** @param topK 返回的相似结果数量。* @return 当前构建器。*/public Builder topK(int topK) {Assert.isTrue(topK >= 0, "TopK应为正数。");this.searchRequest.topK = topK;return this;}/*** 用于过滤搜索响应的相似性阈值分数。只有相似性分数等于或大于'threshold'的文档才会返回。* 注意这是客户端执行的后处理步骤,而非服务器端。阈值为0.0表示接受任何相似性或禁用相似性阈值过滤。* 阈值为1.0表示需要完全匹配。* @param threshold 相似性分数的下限。* @return 当前构建器。*/public Builder similarityThreshold(double threshold) {Assert.isTrue(threshold >= 0 && threshold <= 1, "相似性阈值必须在[0,1]范围内。");this.searchRequest.similarityThreshold = threshold;return this;}/*** 通过将相似性阈值设置为0.0来禁用相似性阈值过滤 - 接受所有结果。* @return 当前构建器。*/public Builder similarityThresholdAll() {this.searchRequest.similarityThreshold = 0.0;return this;}/*** 通过查询嵌入相似性和匹配过滤器检索文档。'null'值表示不应用元数据过滤器。** 例如,如果 {@link Document#getMetadata()} 的模式为:** <pre>{@code* {* "country": <Text>,* "city": <Text>,* "year": <Number>,* "price": <Decimal>,* "isActive": <Boolean>* }* }</pre>** 你可以将搜索结果限制为仅包含isActive=true且year大于等于2020的UK国家。可以通过以下方式构建此类元数据过滤器:** <pre>{@code* var exp = new Filter.Expression(AND,* new Expression(EQ, new Key("country"), new Value("UK")),* new Expression(AND,* new Expression(GTE, new Key("year"), new Value(2020)),* new Expression(EQ, new Key("isActive"), new Value(true))));* }</pre>** {@link Filter.Expression} 可跨所有向量存储移植。<br/>** {@link FilterExpressionBuilder} 是一种以编程方式创建表达式的DSL:** <pre>{@code* var b = new FilterExpressionBuilder();* var exp = b.and(* b.eq("country", "UK"),* b.and(* b.gte("year", 2020),* b.eq("isActive", true)));* }</pre>** {@link FilterExpressionTextParser} 将文本化的、类似SQL的过滤器表达式语言转换为 {@link Filter.Expression}:** <pre>{@code* var parser = new FilterExpressionTextParser();* var exp = parser.parse("country == 'UK' && isActive == true && year >=2020");* }</pre>* @param expression 用于定义元数据过滤条件的 {@link Filter.Expression} 实例。'null'值表示无表达式过滤器。* @return 当前构建器。*/public Builder filterExpression(@Nullable Filter.Expression expression) {this.searchRequest.filterExpression = expression;return this;}/*** 文档元数据过滤器表达式。例如,如果你的 {@link Document#getMetadata()} 的模式如下:** <pre>{@code* {* "country": <Text>,* "city": <Text>,* "year": <Number>,* "price": <Decimal>,* "isActive": <Boolean>* }* }</pre>** 那么你可以使用元数据过滤器表达式来限制搜索结果,例如:** <pre>{@code* country == 'UK' && year >= 2020 && isActive == true* 或* country == 'BG' && (city NOT IN ['Sofia', 'Plovdiv'] || price < 134.34)* }</pre>** 这确保响应仅包含符合指定过滤条件的嵌入。<br/>** 这种声明式的、类似SQL的过滤器语法可跨所有支持过滤器搜索功能的向量存储移植。<br/>** {@link FilterExpressionTextParser} 用于将文本过滤器表达式转换为 {@link Filter.Expression}。* @param textExpression 声明式的、可移植的、类似SQL的元数据过滤器语法。'null'值表示无表达式过滤器。* @return 当前构建器*/public Builder filterExpression(@Nullable String textExpression) {this.searchRequest.filterExpression = (textExpression != null)? new FilterExpressionTextParser().parse(textExpression) : null;return this;}public SearchRequest build() {return this.searchRequest;}}}
这里用了一个模板方法模式
/** Copyright 2023-2025 the original author or authors.** Licensed under the Apache License, Version 2.0 (the "License");* you may not use this file except in compliance with the License.* You may obtain a copy of the License at** https://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.springframework.ai.vectorstore.observation;import java.util.List;import io.micrometer.observation.ObservationRegistry;import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.BatchingStrategy;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.AbstractVectorStoreBuilder;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.lang.Nullable;/*** 提供观测能力的{@link VectorStore}实现的抽象基类。* Abstract base class for {@link VectorStore} implementations that provides observation* capabilities.** @author Christian Tzolov* @author Soby Chacko* @since 1.0.0*/
public abstract class AbstractObservationVectorStore implements VectorStore {// 默认的观测约定private static final VectorStoreObservationConvention DEFAULT_OBSERVATION_CONVENTION = new DefaultVectorStoreObservationConvention();// 观测注册表private final ObservationRegistry observationRegistry;// 可自定义的观测约定@Nullableprivate final VectorStoreObservationConvention customObservationConvention;// 嵌入模型protected final EmbeddingModel embeddingModel;// 批处理策略protected final BatchingStrategy batchingStrategy;// 构造函数private AbstractObservationVectorStore(EmbeddingModel embeddingModel, ObservationRegistry observationRegistry,@Nullable VectorStoreObservationConvention customObservationConvention, BatchingStrategy batchingStrategy) {this.embeddingModel = embeddingModel;this.observationRegistry = observationRegistry;this.customObservationConvention = customObservationConvention;this.batchingStrategy = batchingStrategy;}/*** 使用指定的构建器设置创建一个新的AbstractObservationVectorStore实例。* 初始化观测相关组件和嵌入模型。* Creates a new AbstractObservationVectorStore instance with the specified builder* settings. Initializes observation-related components and the embedding model.* @param builder the builder containing configuration settings*/public AbstractObservationVectorStore(AbstractVectorStoreBuilder<?> builder) {this(builder.getEmbeddingModel(), builder.getObservationRegistry(), builder.getCustomObservationConvention(),builder.getBatchingStrategy());}/*** 添加文档到向量存储* Create a new {@link AbstractObservationVectorStore} instance.* @param documents the documents to add*/@Overridepublic void add(List<Document> documents) {// 创建观测上下文VectorStoreObservationContext observationContext = this.createObservationContextBuilder(VectorStoreObservationContext.Operation.ADD.value()).build();// 执行观测并添加文档VectorStoreObservationDocumentation.AI_VECTOR_STORE.observation(this.customObservationConvention, DEFAULT_OBSERVATION_CONVENTION, () -> observationContext,this.observationRegistry).observe(() -> this.doAdd(documents));}@Overridepublic void delete(List<String> deleteDocIds) {// 创建观测上下文VectorStoreObservationContext observationContext = this.createObservationContextBuilder(VectorStoreObservationContext.Operation.DELETE.value()).build();// 执行观测并删除文档VectorStoreObservationDocumentation.AI_VECTOR_STORE.observation(this.customObservationConvention, DEFAULT_OBSERVATION_CONVENTION, () -> observationContext,this.observationRegistry).observe(() -> this.doDelete(deleteDocIds));}@Overridepublic void delete(Filter.Expression filterExpression) {// 创建观测上下文VectorStoreObservationContext observationContext = this.createObservationContextBuilder(VectorStoreObservationContext.Operation.DELETE.value()).build();// 执行观测并根据过滤器删除文档VectorStoreObservationDocumentation.AI_VECTOR_STORE.observation(this.customObservationConvention, DEFAULT_OBSERVATION_CONVENTION, () -> observationContext,this.observationRegistry).observe(() -> this.doDelete(filterExpression));}@Override@Nullablepublic List<Document> similaritySearch(SearchRequest request) {// 创建搜索观测上下文VectorStoreObservationContext searchObservationContext = this.createObservationContextBuilder(VectorStoreObservationContext.Operation.QUERY.value()).queryRequest(request).build();// 执行观测并执行相似性搜索return VectorStoreObservationDocumentation.AI_VECTOR_STORE.observation(this.customObservationConvention, DEFAULT_OBSERVATION_CONVENTION,() -> searchObservationContext, this.observationRegistry).observe(() -> {var documents = this.doSimilaritySearch(request);searchObservationContext.setQueryResponse(documents);return documents;});}/*** 实际执行添加操作的方法* Perform the actual add operation.* @param documents the documents to add*/public abstract void doAdd(List<Document> documents);/*** 实际执行删除操作的方法* Perform the actual delete operation.* @param idList the list of document IDs to delete*/public abstract void doDelete(List<String> idList);/*** 基于过滤器的删除操作模板方法* Template method for concrete implementations to provide filter-based deletion* logic.* @param filterExpression Filter expression to identify documents to delete*/protected void doDelete(Filter.Expression filterExpression) {// 这是一个临时实现,直到我们在所有具体向量存储中实现此方法,// 届时这个方法将变成抽象方法。// this is temporary until we implement this method in all concrete vector stores,// at which point// this method will become an abstract method.throw new UnsupportedOperationException();}/*** 实际执行相似性搜索操作的方法* Perform the actual similarity search operation.* @param request the search request* @return the list of documents that match the query request conditions*/public abstract List<Document> doSimilaritySearch(SearchRequest request);/*** 创建观测上下文构建器* Create a new {@link VectorStoreObservationContext.Builder} instance.* @param operationName the operation name* @return the observation context builder*/public abstract VectorStoreObservationContext.Builder createObservationContextBuilder(String operationName);}
/** Copyright 2023-2025 the original author or authors.** Licensed under the Apache License, Version 2.0 (the "License");* you may not use this file except in compliance with the License.* You may obtain a copy of the License at** https://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.springframework.ai.vectorstore.elasticsearch;import java.io.IOException;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.Optional;
import java.util.stream.Collectors;import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.core.BulkRequest;
import co.elastic.clients.elasticsearch.core.BulkResponse;
import co.elastic.clients.elasticsearch.core.SearchResponse;
import co.elastic.clients.elasticsearch.core.bulk.BulkResponseItem;
import co.elastic.clients.elasticsearch.core.search.Hit;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.Version;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import com.fasterxml.jackson.databind.DeserializationFeature;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.elasticsearch.client.RestClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentMetadata;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingOptionsBuilder;
import org.springframework.ai.model.EmbeddingUtils;
import org.springframework.ai.observation.conventions.VectorStoreProvider;
import org.springframework.ai.observation.conventions.VectorStoreSimilarityMetric;
import org.springframework.ai.vectorstore.AbstractVectorStoreBuilder;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.ai.vectorstore.filter.FilterExpressionConverter;
import org.springframework.ai.vectorstore.observation.AbstractObservationVectorStore;
import org.springframework.ai.vectorstore.observation.VectorStoreObservationContext;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.util.Assert;/*** 基于Elasticsearch的向量存储实现,使用dense_vector字段类型。* * <p>* 该存储使用Elasticsearch索引持久化向量嵌入及其关联的文档内容和元数据。* 实现利用Elasticsearch的k-NN搜索能力进行高效的相似性搜索操作。* </p>** <p>* 特性:* </p>* <ul>* <li>自动模式初始化,可配置索引创建</li>* <li>支持多种相似性函数:余弦、L2范数和点积</li>* <li>使用Elasticsearch查询字符串进行元数据过滤</li>* <li>可配置的搜索结果相似性阈值</li>* <li>支持批处理策略</li>* <li>通过Micrometer支持观测和指标</li>* </ul>*/
public class ElasticsearchVectorStore extends AbstractObservationVectorStore implements InitializingBean {// 日志记录器private static final Logger logger = LoggerFactory.getLogger(ElasticsearchVectorStore.class);// 相似性函数与向量存储相似性指标的映射private static final Map<SimilarityFunction, VectorStoreSimilarityMetric> SIMILARITY_TYPE_MAPPING = Map.of(SimilarityFunction.cosine, VectorStoreSimilarityMetric.COSINE, SimilarityFunction.l2_norm, VectorStoreSimilarityMetric.EUCLIDEAN, SimilarityFunction.dot_product, VectorStoreSimilarityMetric.DOT);// Elasticsearch客户端private final ElasticsearchClient elasticsearchClient;// Elasticsearch向量存储选项private final ElasticsearchVectorStoreOptions options;// 过滤器表达式转换器private final FilterExpressionConverter filterExpressionConverter;// 是否初始化模式标志private final boolean initializeSchema;/*** 构造函数* @param builder 构建器对象*/protected ElasticsearchVectorStore(Builder builder) {super(builder);Assert.notNull(builder.restClient, "RestClient不能为空");this.initializeSchema = builder.initializeSchema;this.options = builder.options;this.filterExpressionConverter = builder.filterExpressionConverter;// 初始化Elasticsearch客户端String version = Version.VERSION == null ? "Unknown" : Version.VERSION.toString();this.elasticsearchClient = new ElasticsearchClient(new RestClientTransport(builder.restClient,new JacksonJsonpMapper(new ObjectMapper().configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false)))).withTransportOptions(t -> t.addHeader("user-agent", "spring-ai elastic-java/" + version));}/*** 添加文档到向量存储* @param documents 要添加的文档列表*/@Overridepublic void doAdd(List<Document> documents) {// 检查索引是否存在if (!indexExists()) {throw new IllegalArgumentException("索引不存在");}// 构建批量请求BulkRequest.Builder bulkRequestBuilder = new BulkRequest.Builder();// 获取文档的嵌入向量List<float[]> embeddings = this.embeddingModel.embed(documents, EmbeddingOptionsBuilder.builder().build(),this.batchingStrategy);// 为每个文档创建索引操作for (int i = 0; i < embeddings.size(); i++) {Document document = documents.get(i);float[] embedding = embeddings.get(i);bulkRequestBuilder.operations(op -> op.index(idx -> idx.index(this.options.getIndexName()).id(document.getId()).document(getDocument(document, embedding, this.options.getEmbeddingFieldName())));}// 执行批量请求BulkResponse bulkRequest = bulkRequest(bulkRequestBuilder.build());if (bulkRequest.errors()) {// 处理批量操作中的错误List<BulkResponseItem> bulkResponseItems = bulkRequest.items();for (BulkResponseItem bulkResponseItem : bulkResponseItems) {if (bulkResponseItem.error() != null) {throw new IllegalStateException(bulkResponseItem.error().reason());}}}}/*** 构建文档对象* @param document 文档* @param embedding 嵌入向量* @param embeddingFieldName 嵌入字段名* @return 文档对象*/private Object getDocument(Document document, float[] embedding, String embeddingFieldName) {Assert.notNull(document.getText(), "文档文本不能为空");return Map.of("id", document.getId(), "content", document.getText(), "metadata", document.getMetadata(),embeddingFieldName, embedding);}/*** 根据ID列表删除文档* @param idList 要删除的文档ID列表*/@Overridepublic void doDelete(List<String> idList) {BulkRequest.Builder bulkRequestBuilder = new BulkRequest.Builder();// 检查索引是否存在if (!indexExists()) {throw new IllegalArgumentException("索引不存在");}// 为每个ID创建删除操作for (String id : idList) {bulkRequestBuilder.operations(op -> op.delete(idx -> idx.index(this.options.getIndexName()).id(id)));}// 执行批量删除if (bulkRequest(bulkRequestBuilder.build()).errors()) {throw new IllegalStateException("删除操作失败");}}/*** 根据过滤器表达式删除文档* @param filterExpression 过滤器表达式*/@Overridepublic void doDelete(Filter.Expression filterExpression) {// 检查索引是否存在if (!indexExists()) {throw new IllegalArgumentException("索引不存在");}try {// 执行基于查询的删除this.elasticsearchClient.deleteByQuery(d -> d.index(this.options.getIndexName()).query(q -> q.queryString(qs -> qs.query(getElasticsearchQueryString(filterExpression))));}catch (Exception e) {throw new IllegalStateException("根据过滤器删除文档失败", e);}}/*** 执行批量请求* @param bulkRequest 批量请求* @return 批量响应*/private BulkResponse bulkRequest(BulkRequest bulkRequest) {try {return this.elasticsearchClient.bulk(bulkRequest);}catch (IOException e) {throw new RuntimeException(e);}}/*** 执行相似性搜索* @param searchRequest 搜索请求* @return 匹配的文档列表*/@Overridepublic List<Document> doSimilaritySearch(SearchRequest searchRequest) {Assert.notNull(searchRequest, "搜索请求不能为空");try {float threshold = (float) searchRequest.getSimilarityThreshold();// 对于L2范数距离,调整阈值if (this.options.getSimilarity().equals(SimilarityFunction.l2_norm)) {threshold = 1 - threshold;}final float finalThreshold = threshold;// 获取查询文本的嵌入向量float[] vectors = this.embeddingModel.embed(searchRequest.getQuery());// 执行k-NN搜索SearchResponse<Document> res = this.elasticsearchClient.search(sr -> sr.index(this.options.getIndexName()).knn(knn -> knn.queryVector(EmbeddingUtils.toList(vectors)).similarity(finalThreshold).k(searchRequest.getTopK()).field(this.options.getEmbeddingFieldName()).numCandidates((int) (1.5 * searchRequest.getTopK())).filter(fl -> fl.queryString(qs -> qs.query(getElasticsearchQueryString(searchRequest.getFilterExpression())))).size(searchRequest.getTopK()), Document.class);// 转换搜索结果到文档列表return res.hits().hits().stream().map(this::toDocument).collect(Collectors.toList());}catch (IOException e) {throw new RuntimeException(e);}}/*** 获取Elasticsearch查询字符串* @param filterExpression 过滤器表达式* @return 查询字符串*/private String getElasticsearchQueryString(Filter.Expression filterExpression) {return Objects.isNull(filterExpression) ? "*": this.filterExpressionConverter.convertExpression(filterExpression);}/*** 将命中结果转换为文档* @param hit 命中结果* @return 文档对象*/private Document toDocument(Hit<Document> hit) {Document document = hit.source();Document.Builder documentBuilder = document.mutate();if (hit.score() != null) {// 设置距离和分数元数据documentBuilder.metadata(DocumentMetadata.DISTANCE.value(), 1 - normalizeSimilarityScore(hit.score()));documentBuilder.score(normalizeSimilarityScore(hit.score()));}return documentBuilder.build();}/*** 标准化相似性分数* @param score 原始分数* @return 标准化后的分数*/private double normalizeSimilarityScore(double score) {switch (this.options.getSimilarity()) {case l2_norm:// L2范数的返回值与其他函数相反(越接近0表示越准确)return (1 - (java.lang.Math.sqrt((1 / score) - 1)));default: // cosine和dot_productreturn (2 * score) - 1;}}/*** 检查索引是否存在* @return 如果索引存在返回true,否则返回false*/public boolean indexExists() {try {return this.elasticsearchClient.indices().exists(ex -> ex.index(this.options.getIndexName())).value();}catch (IOException e) {throw new RuntimeException(e);}}/*** 创建索引映射*/private void createIndexMapping() {try {this.elasticsearchClient.indices().create(cr -> cr.index(this.options.getIndexName()).mappings(map -> map.properties(this.options.getEmbeddingFieldName(),p -> p.denseVector(dv -> dv.similarity(this.options.getSimilarity().toString()).dims(this.options.getDimensions()))));}catch (IOException e) {throw new RuntimeException(e);}}/*** 属性设置完成后初始化*/@Overridepublic void afterPropertiesSet() {if (!this.initializeSchema) {return;}if (!indexExists()) {createIndexMapping();}}/*** 创建观测上下文构建器* @param operationName 操作名称* @return 观测上下文构建器*/@Overridepublic VectorStoreObservationContext.Builder createObservationContextBuilder(String operationName) {return VectorStoreObservationContext.builder(VectorStoreProvider.ELASTICSEARCH.value(), operationName).collectionName(this.options.getIndexName()).dimensions(this.embeddingModel.dimensions()).similarityMetric(getSimilarityMetric());}/*** 获取相似性指标* @return 相似性指标名称*/private String getSimilarityMetric() {if (!SIMILARITY_TYPE_MAPPING.containsKey(this.options.getSimilarity())) {return this.options.getSimilarity().name();}return SIMILARITY_TYPE_MAPPING.get(this.options.getSimilarity()).value();}/*** 获取原生客户端* @return 原生客户端Optional*/@Overridepublic <T> Optional<T> getNativeClient() {@SuppressWarnings("unchecked")T client = (T) this.elasticsearchClient;return Optional.of(client);}/*** 创建ElasticsearchVectorStore构建器* @param restClient Elasticsearch REST客户端* @param embeddingModel 嵌入模型* @return 构建器实例*/public static Builder builder(RestClient restClient, EmbeddingModel embeddingModel) {return new Builder(restClient, embeddingModel);}/*** ElasticsearchVectorStore构建器类*/public static class Builder extends AbstractVectorStoreBuilder<Builder> {private final RestClient restClient;private ElasticsearchVectorStoreOptions options = new ElasticsearchVectorStoreOptions();private boolean initializeSchema = false;private FilterExpressionConverter filterExpressionConverter = new ElasticsearchAiSearchFilterExpressionConverter();/*** 构造函数* @param restClient Elasticsearch REST客户端* @param embeddingModel 嵌入模型*/public Builder(RestClient restClient, EmbeddingModel embeddingModel) {super(embeddingModel);Assert.notNull(restClient, "RestClient不能为空");this.restClient = restClient;}/*** 设置Elasticsearch向量存储选项* @param options 向量存储选项* @return 构建器实例*/public Builder options(ElasticsearchVectorStoreOptions options) {Assert.notNull(options, "options不能为空");this.options = options;return this;}/*** 设置是否初始化模式* @param initializeSchema 是否初始化模式* @return 构建器实例*/public Builder initializeSchema(boolean initializeSchema) {this.initializeSchema = initializeSchema;return this;}/*** 设置过滤器表达式转换器* @param converter 过滤器表达式转换器* @return 构建器实例*/public Builder filterExpressionConverter(FilterExpressionConverter converter) {Assert.notNull(converter, "filterExpressionConverter不能为空");this.filterExpressionConverter = converter;return this;}/*** 构建ElasticsearchVectorStore实例* @return ElasticsearchVectorStore实例*/@Overridepublic ElasticsearchVectorStore build() {return new ElasticsearchVectorStore(this);}}
}





