Spark读取并分析HBase数据
- 一、摘要
- 二、实现过程
- 三、小结
一、摘要
Apache Spark 是一个快速、通用的大数据处理引擎,提供了丰富的 API 用于数据处理和分析。HBase 是一个分布式、可扩展的 NoSQL 数据库,适合存储海量结构化和半结构化数据。Spark 与 HBase 的结合可以充分发挥两者的优势,实现高效的数据处理和分析。
Spark 可以通过 HBase 的 Java API 或者专用的连接器来读取 HBase 中的数据。在读取数据时,Spark 可以将 HBase 表中的数据转换为 RDD(弹性分布式数据集)或者 DataFrame,然后利用 Spark 的各种操作进行数据处理和分析。
本文以Spark2.3.2读取HBase1.4.8中的hbase_emp_table表数据进行简单分析,用户实现相关的业务逻辑。
二、实现过程
- 在IDEA创建工程SparkReadHBaseData
- 在pom.xml文件中添加依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><scala.version>2.11.8</scala.version><spark.version>2.3.3</spark.version><hbase.version>1.4.8</hbase.version> </properties><dependencies><!-- Spark 依赖 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency><!-- HBase 依赖 --><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-common</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-hadoop-compat</artifactId><version>${hbase.version}</version></dependency><!-- Hadoop 依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.4</version><scope>provided</scope></dependency><!-- 处理依赖冲突 --><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>12.0.1</version></dependency><!-- 使用scala2.11.8进行编译和打包 --><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency></dependencies><build><!-- 指定scala源代码所在的目录 --><sourceDirectory>src/main/scala</sourceDirectory><plugins><!-- Scala 编译插件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.4.6</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.6.0</version><configuration><archive><!-- 项目中有多个主类时,采用不指定主类规避pom中只能配置一个主类的问题 --><manifest/></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins> </build> - 新建com.lpssfxy的package

- 在该package下新建名为SparkReadHBaseData的Object,编写程序实现业务逻辑:
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName} import org.apache.hadoop.hbase.client.{ConnectionFactory, Scan} import org.apache.hadoop.hbase.util.Bytes import org.apache.spark.sql.{SparkSession}/*** Employee样例类** @param empNo* @param eName* @param job* @param mgr* @param hireDate* @param salary* @param comm* @param deptNo*/ case class Employee(empNo: Int, eName: String, job: String, mgr: Int, hireDate: String, salary: Double, comm: Double, deptNo: Int)object SparkReadHBaseData {private val TABLE_NAME = "hbase_emp_table"private val INFO_CF = "info"def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("SparkHBaseIntegration").master("local[*]").getOrCreate()val conf = HBaseConfiguration.create()conf.set("hbase.zookeeper.quorum", "s1,s2,s3")conf.set("hbase.zookeeper.property.clientPort", "2181")val connection = ConnectionFactory.createConnection(conf)val table = connection.getTable(TableName.valueOf(TABLE_NAME))val scan = new Scan()scan.addFamily(Bytes.toBytes(INFO_CF))// 扫描 HBase 表并转换为 RDDval results = table.getScanner(scan)val data = Iterator.continually(results.next()).takeWhile(_ != null).map { result =>val rowKey = Bytes.toString(result.getRow())val eName = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("ename")))val job = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("job")))val mgrString = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("mgr")))var mgr: Int = 0if (!"".equals(mgrString) && null != mgrString) {mgr = mgrString.toInt}val hireDate = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("hiredate")))val salary = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("sal")))val commString = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("comm")))var comm: Double = 0if (!"".equals(commString) && null != commString) {comm = commString.toDouble}val deptNo = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("deptno")))(rowKey.toInt, eName, job, mgr, hireDate, salary.toDouble, comm, deptNo.toInt)}.toList// 转换为 DataFrameimport spark.implicits._val df = spark.sparkContext.parallelize(data).map(item => {Employee(item._1, item._2, item._3, item._4, item._5, item._6, item._7, item._8)}).toDF()// 将df注册成临时表df.createOrReplaceTempView("emp")// 需求1:统计各个部门总支出val totalExpense = spark.sql("select deptNo,sum(salary) as total from emp group by deptNo order by total desc")totalExpense.show()// 需求2: 统计各个部门总的支出(包括工资和奖金),并按照总支出升序排val totalExpense2 = spark.sql("select deptNo,sum(salary + comm) as total from emp group by deptNo order by total")totalExpense2.show()// TODO:需求3-结合dept部门表来实现多表关联查询,请同学自行实现// 关闭连接connection.close()// 停止spark,释放资源spark.stop()} } - 为了没有大量无关日志输出,在resources目录下新建log4j.properties,添加如下内容:
log4j.rootLogger=ERROR,stdout # write to stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n - 启动虚拟机中的hdfs、zookeeper和hbase
start-dfs.sh zkServer.sh start start-hbase.sh - 运行代码,查看执行结果
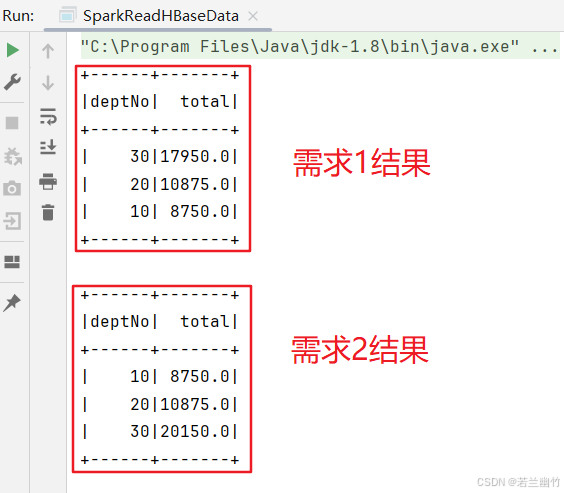
三、小结
- 本实验仅仅演示Spark读取HBase表数据并简单分析的过程,可以作为复杂的业务逻辑分析的基础。
- Spark 读取并分析 HBase 数据具有高性能、丰富的数据分析功能、可扩展性、灵活性和实时性等优势。然而,也存在数据一致性、复杂的配置和管理、资源消耗和兼容性等不足。在实际应用中,需要根据具体的需求和场景来选择是否使用 Spark 和 HBase 的组合,并注意解决可能出现的问题。
)

)



