浙大疏锦行-CSDN博客
聚类的最终目的不是仅仅得到几个数字标签(比如簇0、簇1、簇2),而是要结合业务或现实场景,给每个簇赋予实际意义。 例如:
- 如果数据是客户信息(收入、消费习惯等),可能某个簇的客户平均收入高、信用评分高,那么这个簇的实际含义可能是「优质客户」;
- 另一个簇的客户收入低、逾期次数多,可能对应「高风险客户」。
总结 :这句话的核心是「在完成K-means聚类后,通过分析每个簇的特征(如平均值、分布等),给每个簇打上业务层面的标签,让聚类结果从“数字分组”变成“有现实意义的群体”」。
预先处理的代码
先筛选字符串→标签编码mapping→独热编码→0-1映射→补全残缺→划分数据集
标准化数据集
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# X_scaled为什么聚类前需要标准化? 聚类算法(如K-means)通常基于特征之间的“距离”(如欧氏距离)来分组。如果不同特征的单位或数值范围差异很大(例如“收入”可能是几千到几万,“年龄”是几十),会导致距离计算被“大数值特征”主导,影响聚类效果。标准化可以消除这种差异,让所有特征在相同尺度下比较。
2. scaler = StandardScaler()
这行代码创建了一个 StandardScaler (标准化器)对象。 StandardScaler 是 scikit-learn 库中用于“Z-score标准化”的工具,它的作用是将数据转换为 均值为0,标准差为1 的分布。3. X_scaled = scaler.fit_transform(X)
这行代码是核心操作,分为两步:- fit :计算原始数据 X 的均值和标准差(相当于“学习”数据的分布)。
- transform :用计算出的均值和标准差,将原始数据 X 转换为标准化后的数据 X_scaled 。 公式 :标准化后的值 = (原始值 - 均值) / 标准差
### 4. 注释行:# X_scaled
这行是注释,可能原本用于查看标准化后的数据(例如打印 X_scaled ),但被暂时注释掉了。
评估k值
k_range 数组inertia_values = [] silhouette_scores = [] ch_scores = [] db_scores = [] 分别作为储存kmeans的特征值的地方
1. 创建K-means模型,指定当前k值和随机种子(保证结果可复现)
kmeans = KMeans(n_clusters=k, random_state=42)
2. 训练模型并预测样本所属的簇标签(一步完成训练+预测)
kmeans_labels = kmeans.fit_predict(X_scaled)
for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans_labels = kmeans.fit_predict(X_scaled)inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数db_scores.append(db)print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")
进行kmeans聚类
# 提示用户选择 k 值
selected_k = 3 # 这里选择3后面好分析,也可以根据图选择最佳的k值# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()
簇赋值
现在需要给这个簇赋予实际的含义,一般当你赋予实际含义的时候,你需要根据某几个特征来赋予,但是源数据特征很多,如何选择特征呢?有2种思路:
1. 你最开始聚类的时候,就选择了你想最后用来确定簇含义的特征,那么你需要选择一些特征来进行聚类,那么你最后确定簇含义的特征就是这几个特征,而非全部。如你想聚类消费者购买习惯,那么他过去的消费记录、购买记录、购买金额等等,这些特征都与消费者购买习惯有关,你可以使用这些特征来确定簇含义,一些其他的特征,如消费者年龄,工作行业则不考虑。
----适用于你本身就有构造某些明确含义的特征的情况。
2. 最开始用全部特征来聚类,把其余特征作为 x,聚类得到的簇类别作为标签构建监督模型,进而根据重要性筛选特征,来确定要根据哪些特征赋予含义。
---使用于你想构造什么,目前还不清楚。
【上面这个思路好好学,这是真干货,构造具有价值的特征工程,妥妥的创新点和工作量】
SHAP特征重要性
这段代码的核心目标是 通过训练好的随机森林模型,结合SHAP值分析 ,找出对聚类结果( KMeans_Cluster )影响最大的特征。例如:
- 如果“收入”特征的SHAP值很高,说明收入是区分不同簇的关键因素;
- 如果“工作年限”的SHAP值很低,说明它对聚类结果影响较小。
后续可以通过SHAP值可视化(如特征重要性图),快速定位关键特征,从而结合业务知识推断每个簇的实际含义(例如“高收入稳定簇”“低收入波动簇”等)。
x1= X.drop('KMeans_Cluster',axis=1) # 删除聚类标签列
y1 = X['KMeans_Cluster']
# 构建随机森林,用shap重要性来筛选重要性
import shap
import numpy as np
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
model = RandomForestClassifier(n_estimators=100, random_state=42) # 随机森林模型
model.fit(x1, y1) # 训练模型,此时无需在意准确率 直接全部数据用来训练了shap值计算
shap.initjs()
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x1) # 这个计算耗时
shap_values.shape # 第一维是样本数,第二维是特征数,第三维是类别数绘制SHAP 特征重要性条形图
# --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[:, :, 0], x1, plot_type="bar",show=False) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()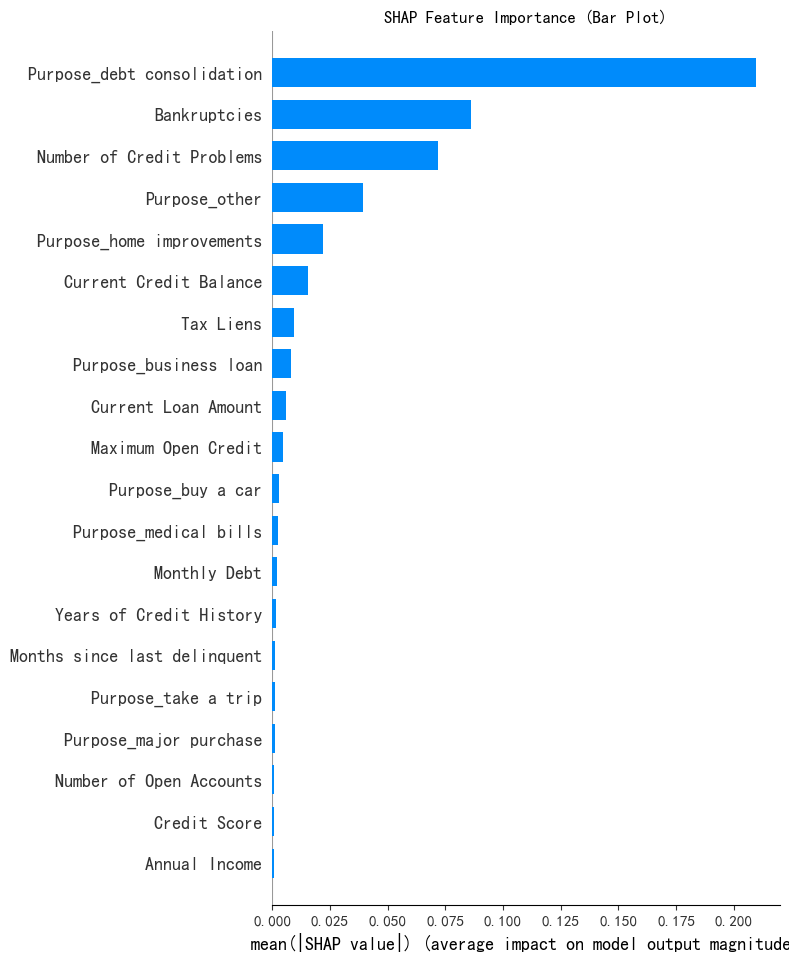
### 1. SHAP的核心作用:量化特征贡献
SHAP基于博弈论中的Shapley值,通过计算每个特征在模型预测中的“边际贡献”,得到一个 统一的重要性指标 (SHAP值)。 简单来说:
- 如果某个特征的SHAP值绝对值很大(无论正负),说明它对模型将样本分到某个簇的影响很大;
- 如果SHAP值接近0,说明该特征对聚类结果几乎无影响。
### 2. 为什么适用于当前场景?
你的代码中,随机森林模型被训练为“根据特征预测样本的聚类标签( KMeans_Cluster )”。此时,模型的本质是 学习聚类算法(K-means)的分组逻辑 。 SHAP的作用是:
- 揭示模型“如何根据特征区分不同簇”(即K-means聚类时实际依赖了哪些特征);
- 例如:如果“收入”特征的SHAP值很高,说明K-means在分组时主要依据收入差异;如果“工作年限”SHAP值低,说明它对聚类结果影响很小。
### 3. SHAP的优势(对比传统重要性)
相比随机森林自带的特征重要性(如基尼系数),SHAP的优势在于:
- 模型无关性 :支持任何模型(随机森林、神经网络等);
- 局部解释性 :不仅能给出全局重要性,还能解释单个样本的预测逻辑(例如“某个高收入样本被分到簇1,主要因为收入特征贡献了+0.8的SHAP值”);
- 一致性 :保证特征贡献的合理分配(避免传统方法中“相关特征重要性被稀释”的问题)。
### 总结
在你的代码中,SHAP的作用是**“翻译”K-means的聚类逻辑**:通过分析随机森林模型的特征贡献(SHAP值),找出K-means在分组时实际依赖的关键特征(如收入、信用评分等),进而结合业务知识推断每个簇的实际含义(例如“高收入稳定簇”“低收入波动簇”)。
此时判断一下这几个特征是离散型还是连续型
### 1. 背景需求:为什么要区分离散/连续型变量?
在数据分析和机器学习中,离散型与连续型变量的处理方式不同:
- 离散型变量 (如“是否破产”“贷款用途”):取值有限(如0/1,或几个固定类别),通常需要用计数、比例等统计方法分析;
- 连续型变量 (如“收入”“信用评分”):取值连续(如1000-10000元),通常需要用均值、标准差、分布直方图等方法分析。
区分类型后,可以更有针对性地选择分析工具(例如:离散型变量用柱状图,连续型用箱线图)。
# 此时判断一下这几个特征是离散型还是连续型
import pandas as pd
selected_features = ['Purpose_debt consolidation', 'Bankruptcies','Number of Credit Problems', 'Purpose_other']for feature in selected_features:unique_count = X[feature].nunique() # 唯一值指的是在某一列或某个特征中,不重复出现的值# 连续型变量通常有很多唯一值,而离散型变量的唯一值较少print(f'{feature} 的唯一值数量: {unique_count}')if unique_count < 10: # 这里 10 是一个经验阈值,可以根据实际情况调整print(f'{feature} 可能是离散型变量')else:print(f'{feature} 可能是连续型变量')- selected_features :需要分析的目标特征(例如这里选了“债务合并用途”“破产次数”等);
- nunique() :统计该特征有多少个不同的值(例如“破产次数”可能只有0、1、2次,唯一值数量少);
- 阈值判断( unique_count < 10 ) :通过经验设定阈值(如小于10个唯一值),认为是离散型变量(反之则是连续型)。
通过这段代码,你可以快速了解这些特征的取值分布,例如:
- 如果“Bankruptcies(破产次数)”的唯一值数量是3(如0、1、2),会被判断为离散型,说明它可能代表“未破产/破产1次/破产2次”等类别;
- 如果某个特征的唯一值数量是100,则可能是连续型(如“收入”有很多不同的数值)。
这些信息能帮助你更合理地选择后续分析方法(例如对离散型变量做交叉分析,对连续型变量做分布统计),最终辅助推断聚类簇的实际含义(例如“破产次数多的簇可能是高风险客户”)。
重要特征图
# X["Purpose_debt consolidation"].value_counts() # 统计每个唯一值的出现次数
import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()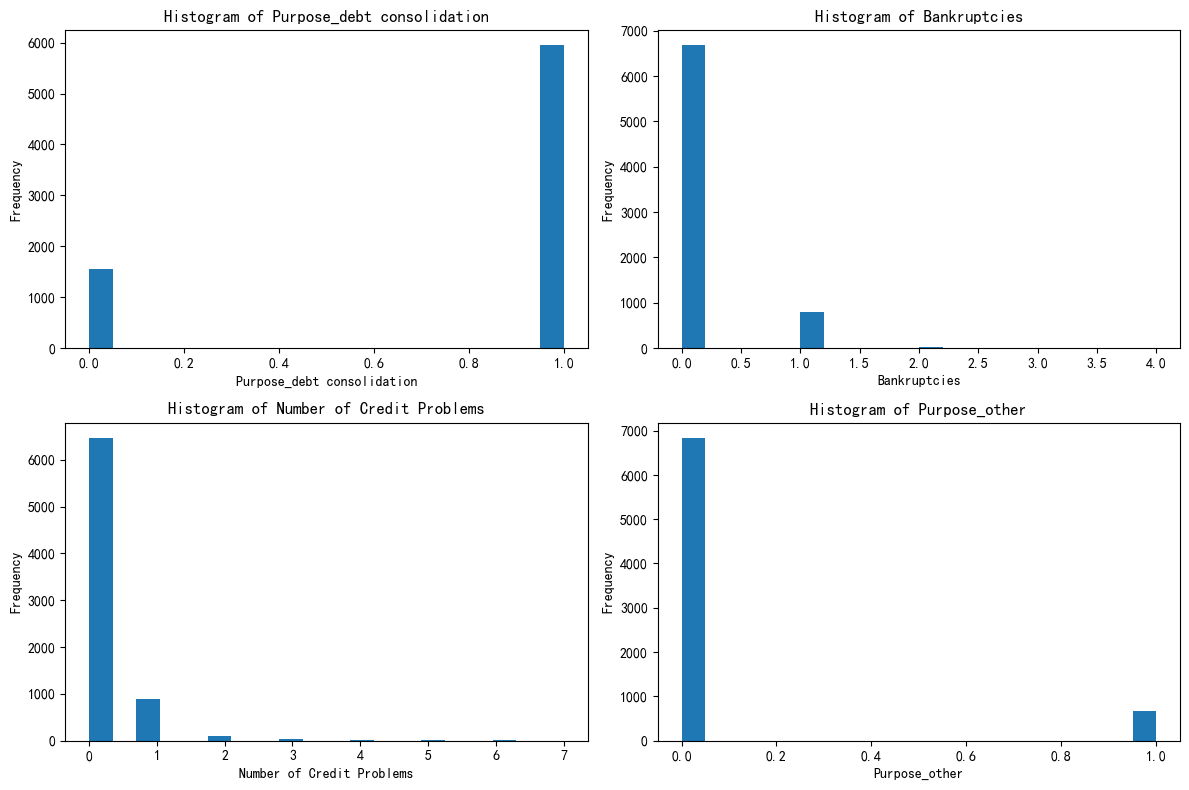
每个簇的特征图
后续会针对每个簇(如簇0、簇1、簇2),绘制选定的四个特征(可能是前面分析的关键特征)的分布图(例如箱线图、柱状图等),用于观察不同簇在这些特征上的差异。
这行代码的作用是 统计每个聚类簇包含的样本数量 。具体拆解:
- X[['KMeans_Cluster']] :从数据 X 中选取聚类标签列( KMeans_Cluster ),结果是一个仅包含该列的DataFrame(保留列名信息);
- .value_counts() :统计该列中每个值(即每个簇标签,如0、1、2)出现的次数,输出各簇的样本数量。
以簇0为例
# 先绘制簇0的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster0[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()
### 2. 导入绘图库:import matplotlib.pyplot as plt
引入 matplotlib 库的 pyplot 模块(常用缩写 plt ),用于绘制图表。
### 3. 创建子图布局:fig, axes = plt.subplots(2, 2, figsize=(12, 8))
- plt.subplots(2, 2) :创建一个2行2列的子图网格(共4个子图),对应4个关键特征的分布图;
- figsize=(12, 8) :设置整个图表的尺寸(宽12英寸,高8英寸),确保图形清晰。
### 4. 展平子图坐标轴:axes = axes.flatten()
将二维的 axes 数组(形状为(2,2))展平为一维数组(形状为(4,)),方便后续通过循环依次访问每个子图。
- selected_features :前面分析的关键特征列表(如“债务合并用途”“破产次数”等);
- X_cluster0 :从原始数据中筛选出的“簇0”样本子集(仅包含簇0的样本);
- hist() :绘制直方图,展示该特征在簇0中的取值分布(例如“破产次数”集中在0次,或“债务合并用途”集中在1);
- set_title / set_xlabel / set_ylabel :为每个子图添加标题和坐标轴标签,增强可读性。
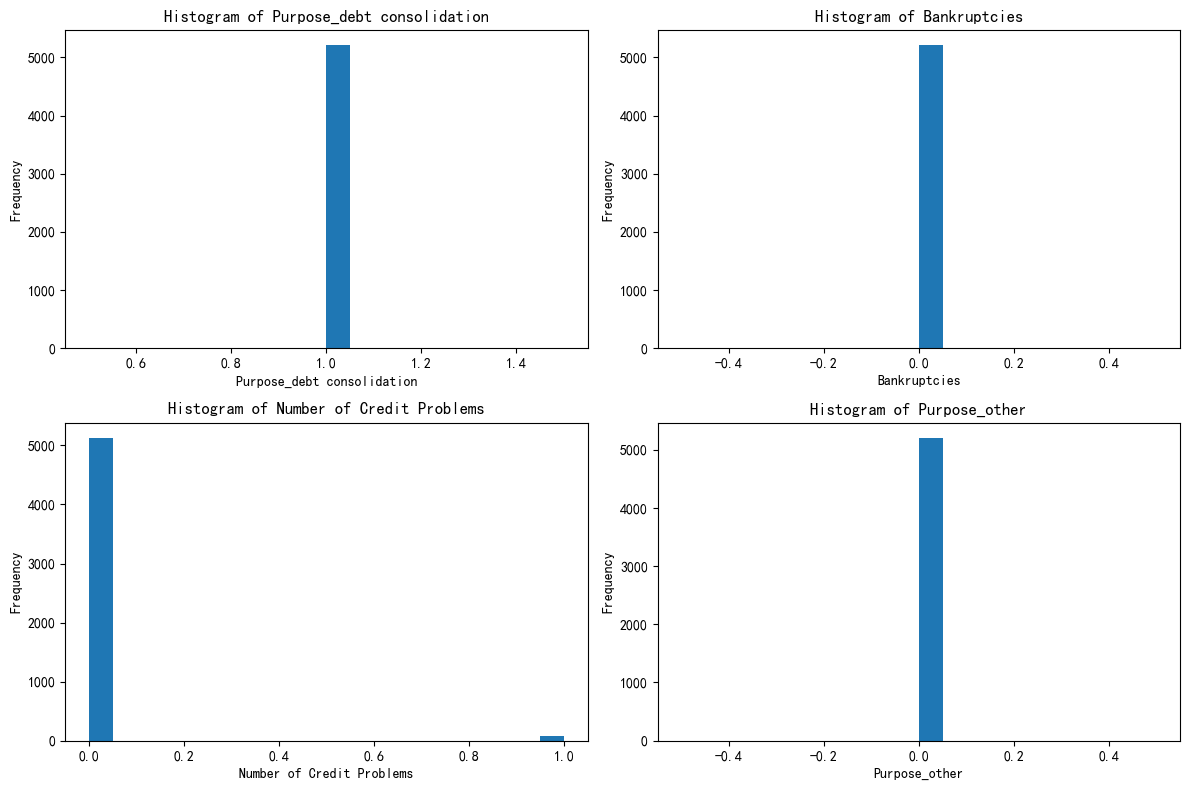
把这三个簇的图发给ai,让ai给你定义
现在你就得到了一个全新的特征,完成了你的特征工程
后续研究需要对这个特征独热编码,然后重新建模训练,如果加了这个特征后模型精度提高,说明这个特征是有用的。





