微服务和服务网格
微服务
微服务将大系统拆解成一个个独立的、小型的服务单元。每个服务可以独立部署、快速迭代,团队可以自主决策,大大降低了变更风险。当然,微服务不是万能药,它需要强大的自动化和DevOps实践作为支撑。而Istio这样的工具,正是在微服务环境下,帮助我们实现流量控制、服务间韧性、指标收集等关键能力,让快速迭代变得可行且安全。学习和进步,离不开反馈。
-
自动化测试就是我们获取反馈、加速迭代的利器。它能让我们在代码变更后,立刻知道是否引入了新的bug,或者功能是否按预期工作。虽然单元测试很重要,但更关键的是功能测试,它让我们从API的角度审视服务,确保客户期望的行为得到保障。而且,当我们的代码因为重构、还债等原因发生变化时,功能测试应该尽可能保持稳定,避免频繁修改。更重要的是,测试不能只停留在测试环境,生产环境才是最真实的战场。我们需要在生产环境中进行测试,甚至进行探索性测试,比如在可控条件下引入混沌,观察系统的真实反应。这比任何预设的测试场景都更接近真实情况。
-
容器化技术,特别是Docker,彻底改变了我们构建和运行应用的方式。它让我们可以把应用、它的依赖、配置打包成一个轻量级的镜像。相比虚拟机,容器共享底层内核,资源利用率更高,启动速度更快。最关键的是,容器提供了强大的环境隔离能力,解决了长期以来困扰我们的环境漂移问题。这意味着我们可以放心地将应用从开发环境迁移到测试环境,再到生产环境,而无需担心环境配置不一致导致的问题。有了统一的容器API,我们就可以构建通用的工具链来管理这些应用,无论它们是什么语言、什么框架。Kubernetes就是这方面的佼佼者,它将容器管理提升到了一个新的高度。
-
自动化构建和部署流程,也就是CI/CD。CI确保我们每天都能把代码集成起来,尽早发现并修复问题。CD则更进一步,它提供了一条自动化流水线,将代码从提交到最终部署到生产环境。容器化为构建这条流水线提供了天然的便利。但是,部署上线并非易事,尤其是新版本上线时,如果直接替换旧版本,很容易导致服务中断。我们需要一种方式来控制流量,逐步将流量从旧版本迁移到新版本,这就是Istio的用武之地。它能让我们精确控制流量,实现金丝雀发布、灰度发布等策略,从而在追求速度的同时,最大限度地降低风险。
如何隔离故障、如何应对环境变化、如何保证系统在部分故障时仍能运行、如何实时监控系统状态、如何控制运行时行为、如何实施安全策略、如何降低变更风险、如何执行访问控制……这些都是我们必须攻克的难关。为什么这些服务架构会变得如此脆弱?一个关键原因在于我们所依赖的基础设施并非坚不可摧。
云服务看似强大,但本质上是由无数的硬件和软件组件组成的。任何一个组件都可能出故障。过去,我们可能假设基础设施是可靠的,可以在上面构建稳定的应用。但在云环境中,这种假设是危险的。比如,一个服务调用另一个服务,中间可能因为网络拥塞、目标服务过载、甚至网络设备故障导致延迟飙升。面对这种不可靠的网络,我们的服务该如何自处?我们需要给服务赋予韧性。这就像给系统穿上盔甲,让它在面对冲击时不至于崩溃。有哪些常用的武器呢?
- 比如,请求失败了,可以尝试重试,但要小心,如果重试太多,反而会加重下游压力。
- 可以设置超时时间,如果等太久,就果断放弃。
- 如果发现某个服务一直有问题,可以暂时熔断,停止调用它,让它冷静一下。
- 还可以限制每次请求的资源消耗,防止一个服务拖垮整个系统。
- 客户端负载均衡和动态服务发现则帮助我们找到健康的、可用的服务实例。
这些技术,我们统称为应用网络,它们在应用层面上构建了网络的韧性,确保服务在复杂多变的环境中依然能够稳定运行。光有韧性还不够,我们还需要知道系统到底发生了什么。我们需要实时了解系统状态:**服务之间是怎么通信的?负载情况如何?哪里出了故障?服务健康状况如何?**这些信息对于评估变更的影响、判断系统是否健康至关重要。
每一次部署新代码,都可能引入新的风险。我们需要强大的监控系统,通过指标、日志、追踪等手段,实时掌握系统的脉搏,确保我们能够及时发现问题,保障系统稳定可靠运行。为了解决这些问题,早期的互联网巨头们尝试了另一种方式:在应用层面引入各种库。比如Netflix的Hystrix、Ribbon、Eureka,Twitter的Finagle等等。这些库确实解决了不少问题,但它们也带来了新的挑战。
- 如果我想用一个新的语言或框架来构建服务,就必须找到对应的库,或者干脆放弃这个库。这限制了我们的技术选择。
- 不同语言的库,它们的实现方式可能完全不同,甚至基于不同的假设。这导致了系统行为的不一致,增加了排查故障的难度。
- 维护这么多不同语言的库,确保它们的版本一致、功能一致,本身就是一项巨大的工程。这就像给每个应用都装上了一套不同的工具,虽然功能强大,但管理和维护成本极高。
既然这些应用网络的功能,比如重试、超时、负载均衡、熔断,是通用的,不依赖于具体的应用语言或框架,那么我们能不能把这些关注点从应用中剥离出来,交给基础设施来处理呢?这正是我们接下来要探讨的。
Kubernetes这样的容器平台,已经帮我们把一些简单的网络服务,比如服务发现和负载均衡,从应用中解放出来了。但是,对于更复杂的、更高级的应用网络功能,比如精细化的熔断、重试策略、安全策略执行,Kubernetes本身还不够。我们需要一种更通用、更强大的解决方案。而代理,特别是应用感知代理,就是我们寻找的方向。它需要理解应用层的协议,比如HTTP请求、gRPC消息,而不仅仅是传统的网络连接和数据包。
服务网格
服务网格,就是这样一个解决方案。它是一个分布式的应用基础设施,它默默地站在应用的背后,处理所有进出应用的网络流量,而且对应用本身是透明的。它主要由两部分组成:数据平面和控制平面。
- 数据平面由像Envoy这样的应用代理构成,它们是网络流量的执行者,负责处理请求、建立连接、实施安全策略和控制。
- 控制平面则是大脑,负责管理数据平面的行为,它通过API接收操作人员的指令,然后配置数据平面。
服务网格的核心价值在于,它能提供强大的服务韧性、可观测性、流量控制、安全性和策略执行能力。这一切,都是在应用无需改动的情况下实现的。现在,让我们聚焦到一个具体的实现:Istio。
Istio是由Google、IBM、Lyft等巨头共同发起的开源项目,它是一个成熟的服务网格解决方案。Istio的目标就是让服务网格变得透明,应用开发者几乎不需要关心底层的网络细节。Istio的默认数据平面是Envoy,它负责具体的流量处理和代理功能。而控制平面则由一系列组件构成,
- Pilot负责配置管理
- Mixer负责监控和策略
- Auth负责身份认证
- Tracing负责追踪
这张图展示了Istio的典型架构
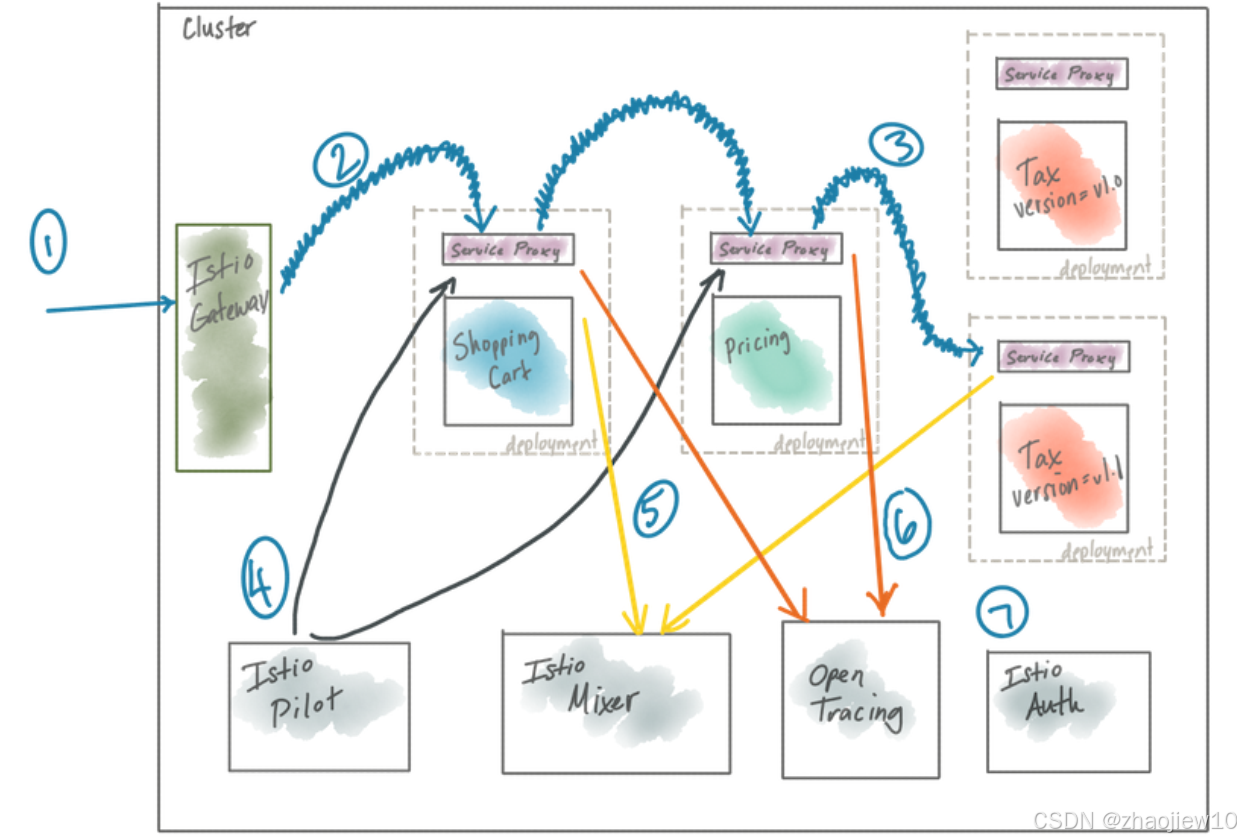
外部流量通过Gateway进入,然后通过Envoy代理路由到服务,整个过程受到Istio控制平面的管理和监控。
Istio的设计理念是平台无关的,它可以在Kubernetes上运行,也可以在其他平台上运行,甚至可以跨云环境Istio的核心优势在于它带来的透明性和一致性。应用开发者几乎不需要关心底层的网络细节,就能享受到服务网格带来的强大功能,比如韧性、可观测性、安全等等。这意味着,无论你的应用是用Java、Python还是Go写的,无论你用什么框架,Istio都能提供一致的、高质量的网络服务。这大大简化了运维工作,降低了运维复杂度。更重要的是,Istio默认启用mTLS,实现了端到端的加密通信,这对于保护微服务之间的通信至关重要。
此外,Istio还提供了强大的策略控制能力,可以实现精细的流量控制、访问控制、配额管理等等。这对于构建混合云、多云环境下的服务治理非常有帮助。可以说,Istio是构建云原生应用的基石之一。
服务网格的概念,可能让大家联想到以前的ESB(企业服务总线)。它们确实有相似之处,比如都希望简化服务调用。但ESB和ESB有着本质的区别。ESB往往是集中式的,存在单点故障的风险。而且,ESB常常把应用网络和业务逻辑混在一起,职责不清,还常常是昂贵的商业软件。而服务网格,它采用的是分布式架构,每个服务旁边都有一个代理,没有中心化的瓶颈。它的职责非常明确,就是专注于应用网络的连接、安全和控制。它通常是开源的,更加灵活和可扩展。所以,服务网格是ESB的升级版,解决了ESB的许多问题。
另一个容易混淆的概念是API网关。API网关通常用于暴露给外部的API,提供安全、限流、监控等能力。但传统的API网关,往往也是集中式的,所有服务都通过它访问,这会带来额外的网络延迟和潜在的瓶颈。而且,API网关通常只关注入口流量,对于服务内部的通信,它可能鞭长莫及。相比之下,服务网格的代理是分布式的,与服务同部署,减少了网络跳数,降低了延迟。更重要的是,服务网格的代理本身就具备强大的韧性、安全和可观测性能力,而API网关通常需要额外的插件来实现这些功能。
因此,服务网格正在成为一种更强大的API管理基础设施,甚至可能取代传统的API网关。Istio这么强大,是不是只能用在微服务架构上?答案是不一定。虽然Istio在微服务架构下能发挥最大的威力,尤其是在服务数量众多、交互复杂、跨越多个云环境的场景下,但它同样可以为非微服务架构,比如传统的单体应用,带来价值。
比如,你可以把Istio的代理部署在单体应用旁边,让它来处理单体应用的网络流量,这样就能获得指标监控、策略执行等能力,这对于理解单体应用的性能瓶颈、进行跨云访问控制都非常有帮助。对于已经使用了Netflix OSS等库的微服务,Istio也能提供额外的保障,比如统一的策略执行、更精细的流量控制,甚至可以发现和解决不同库之间可能存在的冲突。
当然,服务网格也不是万能的。它专注于解决应用网络层面的问题,比如连接、安全、流量控制、可观测性。它不会帮你做业务逻辑处理,比如业务流程编排、数据转换、内容路由等等。这些事情还是应该由应用本身来负责。理想的状态是,我们把应用架构分成不同的层次,每个层次负责不同的关注点。
- 部署平台负责实例的部署、调度、伸缩;
- 服务网格负责网络的连接、安全、控制和可观测;
- 应用本身负责业务逻辑。
Istio的角色就是服务网格层,它连接着应用层和部署平台层,让应用可以专注于业务逻辑,而无需关心底层复杂的网络细节。
istio理论概况
控制平面
现在我们来看看 Istio 的控制平面到底负责什么。它就像服务网格的中央大脑,负责管理、控制、观察和配置整个网格。它的核心功能非常丰富,包括提供API给运维人员配置路由和容错,向数据平面代理下发配置,抽象服务发现,定义策略,管理证书和身份认证,收集遥测数据,注入服务代理,以及定义网络边界。可以说,控制平面掌控着整个服务网格的运作。
在控制平面组件中,istiod 是核心中的核心。它承担着将用户或运维人员配置的高级意图,比如路由规则、重试策略,转换成具体的代理配置,比如 Envoy Proxy 的配置。istiod 通过暴露给用户和数据平面的 API 来实现这一点。它还具有平台无关性,通过适配器来对接不同的底层平台,比如 Kubernetes。我们之前看到的配置资源,最终都会通过 istiod 转化为 Envoy 可以理解的 xDS 配置。
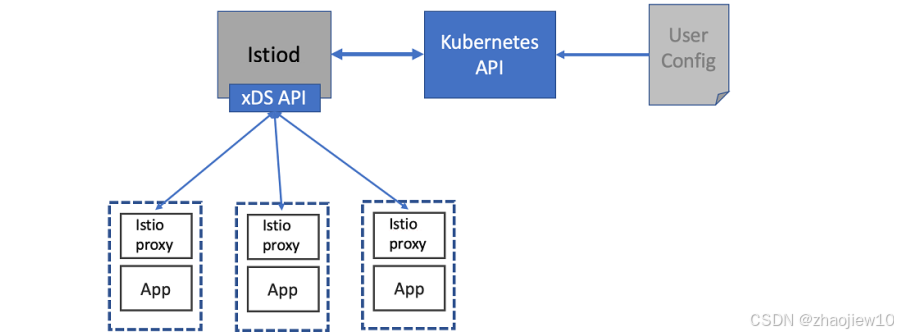
这张图清晰地展示了 Istiod 的工作流程。用户通过 Kubernetes API 提交配置,比如定义一个 VirtualService。Istiod 接收这些配置,然后通过 xDS API 将翻译后的配置下发给 Istio 代理。这些代理部署在每个服务旁边,负责实际的流量转发和处理。这样,用户只需要关心业务逻辑,而 Istiod 和代理则负责底层的网络配置和管理。
配置流量路由
我们来看一个具体的例子:配置流量路由。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:name: catalog-service
spec:hosts:- catalog.prod.svc.cluster.localhttp:- match: # Request matching- headers:x-dark-launch:exact: "v2" # Exact match of headerroute: # Where to route on match- destination:host: catalog.prod.svc.cluster.localsubset: v2- route: # All other traffic- destination:host: catalog.prod.svc.cluster.localsubset: v1
假设我们想根据请求头 x-dark-launch 的值来决定请求是发送到 catalog 服务的 v1 版本还是 v2 版本。
我们可以用 Istio 的 VirtualService 资源来定义这个规则。这个配置文件定义了 hosts 是 catalog,然后在 http 下面,match 匹配请求头 x-dark-launch 等于 v2,然后 route 指定目标是 catalog 服务的 v2 版本。如果没有匹配到这个头,就默认路由到 v1 版本。
这就是 Istio 控制流量的典型方式。Istio 如何将这些配置应用到 Kubernetes 集群中呢?它巧妙地利用了 Kubernetes 的自定义资源 CRD 机制。Istio 的配置资源,比如我们刚才看到的 VirtualService,实际上是 Kubernetes 的 Custom Resource。这些 CR 由 CRD 定义,扩展了 Kubernetes 的原生 API。这意味着我们可以像操作 Kubernetes 原生资源一样,使用 kubectl apply -f 来创建、修改和删除 Istio 的配置。Istio 的控制器会监听这些 CR 的变化,并自动将它们翻译成 Envoy 的配置。Istiod 如何将我们写的 YAML 配置文件,比如 VirtualService,转换成 Envoy 能够理解的 JSON 配置呢?这里展示了 Istiod 生成的 Envoy 配置示例。
"domains": ["catalog.prod.svc.cluster.local"],"name": "catalog.prod.svc.cluster.local:80","routes": [{"match": {"headers": [{"name": "x-dark-lauch","value": "v2"}],"prefix": "/"},"route": {"cluster": "outbound|80|v2|catalog.prod.svc.cluster.local","use_websocket": false}},{"match": {"prefix": "/"},"route": {"cluster": "outbound|80|v1|catalog.prod.svc.cluster.local","use_websocket": false}}]
可以看到,它包含了 domains、name、routes 等字段,这些字段描述了 Envoy 应该如何监听端口、如何匹配路由规则。Istiod 会将 Istio 特定的配置逻辑,比如 match 和 route 的规则,翻译成 Envoy 的原生配置,然后通过 xDS API 推送给代理。
xDS API
刚才提到的 xDS API 是什么?它是 Envoy Proxy 的核心机制,xDS API用于动态发现和更新配置。它包括了监听器发现、端点发现、路由规则发现等服务。通过 xDS API,Istio 控制平面可以实时地将配置推送给数据平面的代理,而代理无需重启就能感知到这些变化。这种动态配置能力极大地提升了系统的灵活性和响应速度。更重要的是,只要代理支持 xDS API,Istio 就可以与之集成,这为 Istio 的扩展性奠定了基础。
除了路由控制,Istio 的另一个核心能力是安全。它通过为每个服务实例分配身份,并使用 X.509 证书来加密服务间的通信。这背后是 SPIFFE 标准,它允许 Istio 实现强双向认证,也就是 mTLS。这意味着服务之间互相验证身份,确保通信的机密性和完整性。Istiod 在其中扮演着证书颁发机构的角色,负责证书的签发、部署和轮换,整个过程对应用是透明的。
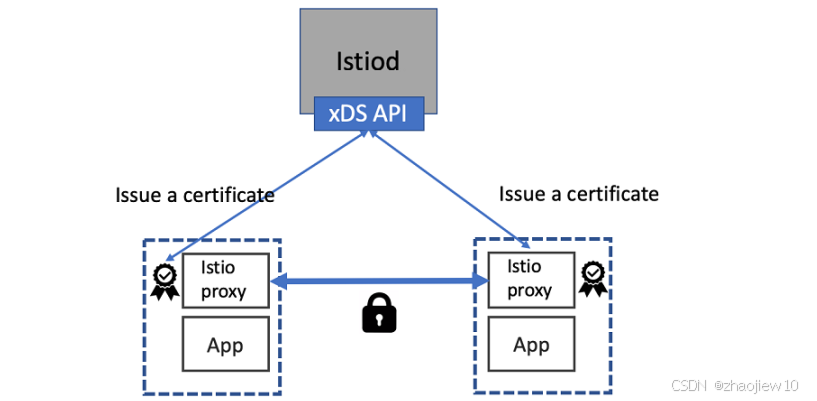
这张图展示了 Istiod 如何管理证书。可以看到,两个服务实例都通过 Istio 代理与 Istiod 进行通信。Istiod 负责签发证书,然后将证书下发给代理。代理之间通过这些证书进行加密通信,实现了服务间的安全认证。这大大提高了微服务架构的安全性,尤其是在复杂的网络环境中。
Gateway
服务网格需要与外部世界交互。Istio 提供了 Ingress 和 Egress Gateway 组件来管理进出集群的流量。
- istio-ingressgateway 是一个入口网关,负责将外部流量导向集群内部的服务。
- istio-egressgateway 则是出口网关,控制集群内部服务访问外部资源。
通过明确配置这些 Gateway,我们可以更好地管理网络边界,提高安全性和可审计性。
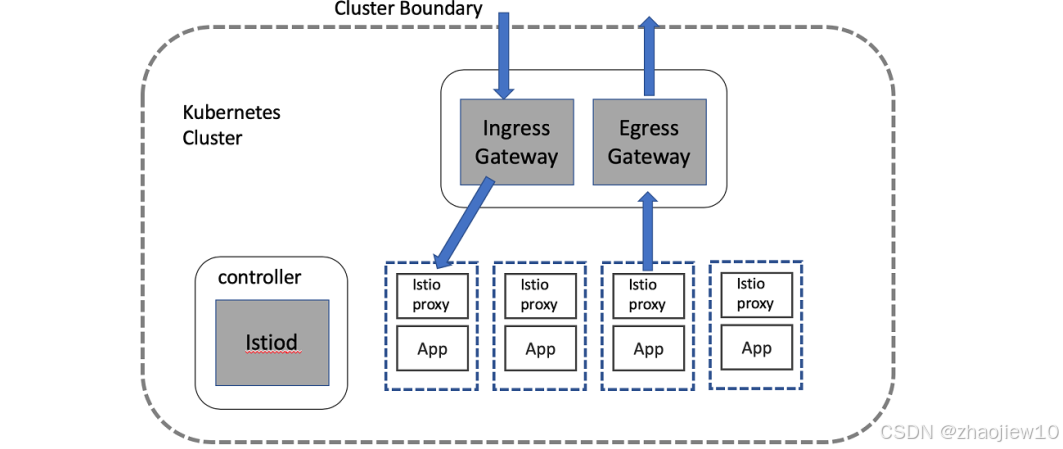
这张图展示了 Gateway 组件的角色。左侧是 Kubernetes 集群,右侧是 Istio 的控制平面。Ingress Gateway 和 Egress Gateway 作为数据平面组件,位于集群的边缘,负责处理进出集群的流量。它们接收来自外部的请求,或者允许集群内部的服务访问外部资源。通过 Istio Gateway,我们可以集中管理集群的网络访问策略,实现精细化的流量控制。
理论讲了不少,现在我们来部署一个实际的应用,看看 Istio 在实际场景中的应用。我们模拟一个会议用品供应商的在线商店,它采用了典型的微服务架构
- 前端有 AngularJS 和 NodeJS
- 中间有一个 API Gateway
- 后端则有目录服务和库存服务
示例服务
今天我们先聚焦于部署 API Gateway 和 Catalog Service 这两个核心服务。这就是我们应用的简化架构图。
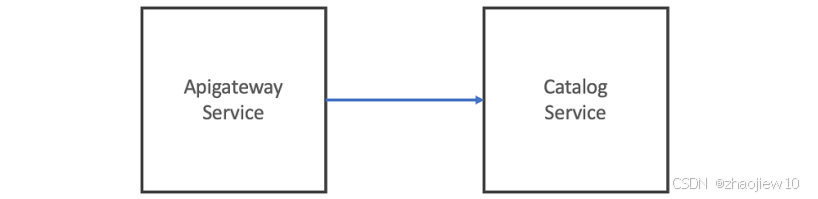
左边是 API Gateway,它作为统一入口,接收来自外部的请求,然后根据请求转发到右边的 Catalog Service 或者其他的后端服务。这种架构模式在微服务中非常常见,API Gateway 承担了路由、安全、监控等职责,后端服务则专注于业务逻辑。
我们先从部署这两个服务开始。在部署应用之前,我们需要在 Kubernetes 中创建一个新的命名空间,叫做 istioinaction。现在我们来部署 Catalog Service
关键步骤是使用 istioctl kube-inject 命令(手动注入)。
$ istioctl kube-inject -f services/catalog/kubernetes/catalog.yaml
这个命令会读取原始的 YAML 文件,并自动添加一个 istio-proxy 的容器到 Pod 的定义中
- args:- proxy- sidecar- --domain=$(POD_NAMESPACE).svc.cluster.local- --serviceCluster=catalog.$(POD_NAMESPACE)- --proxyLogLevel=warning- --proxyComponentLogLevel=misc:error- --trust-domain=cluster.local- --concurrency=2
env:- name: JWT_POLICYvalue: first-party-jwt- name: PILOT_CERT_PROVIDERvalue: istiod- name: CA_ADDRvalue: istiod.istio-system.svc:15012- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name
...
image: docker.io/istio/proxyv2:1.7.0
imagePullPolicy: Always
name: istio-proxy
这个 istio-proxy 代理就是我们之前说的 Sidecar。最后,我们把增强后的 YAML 文件应用到 Kubernetes 集群中。
$ istioctl kube-inject -f services/catalog/kubernetes/catalog.yaml \
| kubectl apply -f -
serviceaccount/catalog created
service/catalog created
deployment.extensions/catalog created
部署完成后,Pod 里有两个容器都运行正常,一个是我们的 Catalog 应用容器,另一个就是 Istio 的代理容器。为了验证服务是否真的工作,我们用一个临时的 Pod 运行 curl 命令,调用 catalog 服务的 /items 接口。如果能看到 JSON 响应,就说明服务部署成功,并且 Istio 代理已经正常工作了。
kubectl run -i --rm --restart=Never dummy --image=dockerqa/curl:ubuntu-trusty --command -- sh -c 'curl -s catalog/items'
部署 API Gateway 的步骤和 Catalog Service 一样。同样地,验证 Pod 状态和用 curl 命令测试服务是否正常工作。
$ istioctl kube-inject -f services/apigateway/kubernetes/apigateway.yaml | kubectl apply -f -
这个过程展示了如何将 Istio 代理注入到不同的服务中,为后续的流量控制和可观测性打下基础。
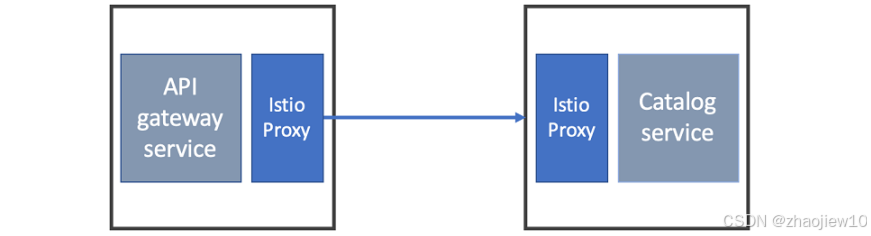
现在我们有两个服务,每个服务都配了 Istio 代理。当 API Gateway 调用 Catalog Service 时,实际上请求是先经过 API Gateway 的 Istio 代理,然后由它转发给 Catalog Service 的 Istio 代理,再由后者传递给 Catalog 服务本身。Istio 代理在服务间通信的两侧都扮演了角色,负责流量控制、路由、安全检查等关键功能。
目前我们的服务只能在集群内部访问。为了让外部也能访问 API Gateway,我们需要配置 Istio Gateway。这个 Gateway 会监听特定端口,比如 80 端口,并将流量转发到 API Gateway 服务。
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:name: outfitters-gatewaynamespace: istioinaction
spec:selector:istio: ingressgateway # use istio default controllerservers:- port:number: 80name: httpprotocol: HTTPhosts:- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:name: webapp-virtualservicenamespace: istioinaction
spec:hosts:- "*"gateways:- outfitters-gatewayhttp:- route:- destination:host: webappport:number: 80
我们配置了 coolstore-gateway 和 apigateway-virtualservice,前者定义了 Gateway 的监听,后者定义了路由规则。配置好后,我们就可以用 curl http://localhost:80/api/catalog 访问到 API Gateway 服务了。
Istio 的一个巨大优势是其强大的可观察性。由于 Istio 代理部署在服务调用链路的两侧,它可以收集到非常丰富的遥测数据,包括请求量、响应时间、错误率等。更重要的是,这种观察是黑盒式的,不需要修改应用代码。Istio 提供了两种主要的观测手段:
- 一是全局指标,提供宏观的性能概览;
- 二是分布式追踪,可以深入分析单个请求在服务链路中的详细路径。
要查看全局指标,Istio 提供了 Prometheus 和 Grafana 这两个工具。我们可以通过 Istio 的 Addons 功能快速安装它们。安装后,使用 istioctl dashboard grafana 命令可以将 Grafana 的仪表板访问端口映射到本地。打开 Grafana,你会看到 Istio 提供的默认仪表板,比如 Istio Service Dashboard。这个仪表板会显示集群中所有服务的总体指标。在 Grafana 中,我们选择 Istio Service Dashboard,然后在服务下拉列表中选择 apigateway。这时,你会看到一些指标,比如客户端请求量、成功率、请求持续时间等。这些指标目前都是空的。我们可以在另一个终端启动一个简单的流量生成器,不断向 apigateway/api/catalog 发送请求。
$ while true; do curl http://localhost/api/catalog; sleep .5; done
回到 Grafana,你会看到仪表盘上的图表开始更新,显示了请求量、成功率、响应时间等指标。
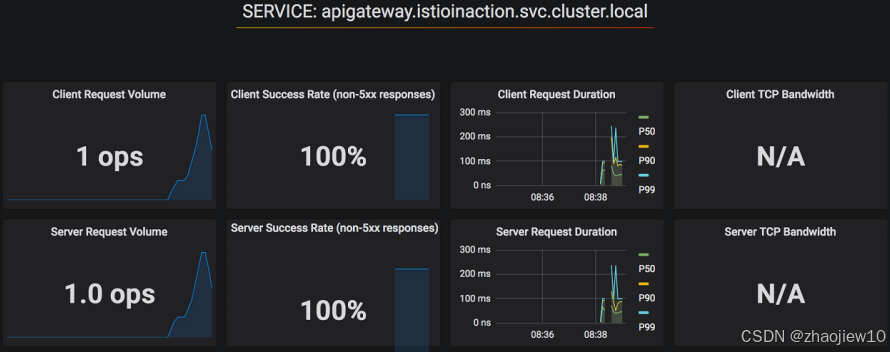
除了全局指标,Istio 还能提供分布式追踪。通过 Istio 的 Addons,我们可以轻松安装 Jaeger。
kubectl apply -f ./samples/addons/jaeger.yaml
Jaeger 是一个流行的分布式追踪系统。安装好后,使用 istioctl dashboard jaeger 命令访问 Jaeger 的 Web 界面。同样,我们需要先生成一些流量,然后在 Jaeger 的界面中查看追踪信息。
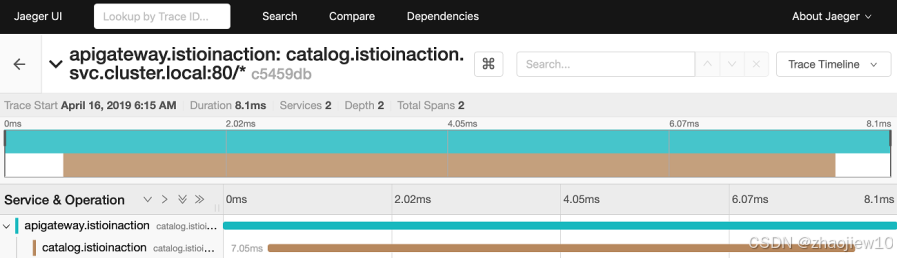
在 Jaeger 界面,我们可以看到追踪条目,每个条目代表一个完整的请求。点击一个条目,可以看到它包含的各个 Span,也就是请求的子操作。通过 Jaeger,我们可以清晰地看到一个请求是如何从 Istio Gateway 传递到 API Gateway,再到 Catalog Service 的整个过程。这有助于我们理解系统内部的调用链路和性能瓶颈。
分布式系统的一个核心问题是网络不可靠。过去,开发者需要在应用代码中手动实现重试、超时、熔断等机制。Istio 可以将这些容错能力下沉到服务网格层面,为所有应用提供一致的、默认的容错能力。我们可以通过一个简单的 chaos.sh 脚本,模拟 Catalog 服务偶尔出现故障的情况。
$ ./bin/chaos.sh 500 100 # 注入100%的500 code故障
这时,客户端调用 API Gateway 就会看到间歇性的失败。现在,我们用 Istio 的 VirtualService 来配置重试。我们定义一个规则,针对 catalog 服务,允许重试最多 3 次,每次重试的超时时间是 2 秒。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:name: catalog
spec:hosts:- cataloghttp:- route:- destination:host: catalogretries:attempts: 3retryOn: 5xxperTryTimeout: 2s
应用这个配置后,我们再次运行测试脚本。你会发现,即使 Catalog 服务仍然在模拟故障,客户端的响应却不再出现失败了。这是因为 Istio 的代理自动进行了重试,而无需修改应用代码。
$ ./bin/chaos.sh 500 delete # 删除500异常
Istio 的另一个重要能力是精细化的流量控制。假设我们发布了 Catalog Service 的新版本 v2,它增加了 imageUrl 字段。我们希望在正式上线前,先让一部分用户尝试新版本,比如内部员工。这时,我们需要 Istio 来控制流量,只将特定用户的请求路由到 v2 版本,而其他用户的请求仍然路由到稳定的 v1 版本。
要实现流量控制,首先要让 Istio 了解服务的不同版本。我们使用 DestinationRule 资源来定义这个。DestinationRule 可以基于 Kubernetes Pod 的标签,比如 version: v1 和 version: v2,来区分不同的服务版本。我们定义了两个版本:version-v1 和 version-v2。然后,我们需要部署 Catalog Service 的 v2 版本,并确保它的 Pod 标签是 version: v2。最后,应用这个 DestinationRule。有了版本定义,我们就可以使用 VirtualService 来控制流量了。
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:name: catalog
spec:host: catalogsubsets:- name: version-v1labels:version: v1- name: version-v2labels:version: v2
我们定义一个规则,将所有请求都路由到 catalog 服务的 version-v1 版本。应用这个配置后,无论客户端发送什么请求,都会被路由到 v1 版本。这时,我们再次访问服务,应该只看到 v1 版本的响应。
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:name: catalog
spec:host: catalogsubsets:- name: version-v1labels:version: v1- name: version-v2labels:version: v2
更进一步,我们可以根据请求的特征来动态路由。比如,我们定义一个规则,如果请求头包含 x-dark-launch: v2,就将请求路由到 v2 版本,否则路由到 v1 版本。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:name: catalog
spec:hosts:- cataloghttp:- match:- headers:x-dark-launch:exact: "v2"route:- destination:host: catalogsubset: version-v2- route:- destination:host: catalogsubset: version-v1
应用这个配置后,我们再次访问服务,发现默认情况下还是返回 v1 的响应。但是,如果我们发送一个带有 x-dark-launch: v2 头的请求,就能看到 v2 版本的响应了。这展示了 Istio 如何实现基于特定条件的精细化流量控制。





