Transformer架构整体包含几个重要的板块,主要是为了处理序列数据,尤其在自然语言处理(NLP)领域。它的核心思想是“自注意力”(Self-Attention)机制,通过并行计算来提高效率。以下是Transformer架构的主要组成部分:
-
输入嵌入(Input Embeddings)
-
输入嵌入是将离散的词语转换为连续的向量表示。这通常是通过查找词向量表(Embedding Layer)来实现的。
-
-
位置编码(Positional Encoding)
-
由于Transformer没有像RNN那样的顺序信息,所以需要通过位置编码来引入序列中各个位置的顺序信息。常见的做法是使用正弦和余弦函数生成位置编码。
-
-
编码器(Encoder)
-
Transformer的编码器由多个相同的层堆叠而成,每层包含以下部分:
-
自注意力机制(Self-Attention Mechanism):使每个词能够关注输入序列中的其他词,从而捕捉词与词之间的关系。
-
前馈神经网络(Feed-Forward Neural Network):对自注意力的输出进行非线性变换,通常包括两个全连接层,中间有ReLU激活函数。
-
残差连接(Residual Connection):将输入与输出相加,通过Layer Normalization进行规范化,帮助避免梯度消失问题。
-
层归一化(Layer Normalization):每个子层(如自注意力、前馈网络)后进行归一化,确保网络稳定。
-
-
-
解码器(Decoder)
-
解码器的结构与编码器相似,但它有额外的自注意力机制,处理已经生成的输出序列。解码器由以下部分组成:
-
自注意力机制:与编码器中的自注意力机制相似,但对输入的目标序列进行自注意力计算。
-
编码器-解码器注意力(Encoder-Decoder Attention):解码器中的每个位置与编码器的输出进行交互,帮助解码器获取与输入序列相关的信息。
-
前馈神经网络:与编码器中的前馈网络相同。
-
残差连接和层归一化:与编码器中的结构一致。
-
-
-
输出层(Output Layer)
-
输出层通常是一个全连接层,将解码器的输出映射到词汇表的维度,从而得到每个位置的词预测概率。
-
-
多头注意力机制(Multi-Head Attention)
-
在每个自注意力层和编码器-解码器注意力层中,都使用了多头注意力机制。通过并行计算多个“头”,使得模型可以从不同的子空间中学习信息,从而增强表达能力。
-
-
位置-序列建模(Positional Sequence Modeling)
-
由于Transformer的计算不依赖于顺序,这使得其能够进行并行计算,但同时需要通过位置编码来保留词语的顺序信息。
-
整体流程大致如下:
-
输入数据经过嵌入和位置编码后,进入编码器。
-
编码器处理输入序列,生成一组上下文相关的表示。
-
解码器利用编码器输出的信息,通过自注意力和编码器-解码器注意力生成目标序列。
-
最终输出层生成每个词的概率分布,模型进行预测。
这个结构是Transformer架构的基础,之后的很多变体(如BERT、GPT等)都是在此基础上做了修改和优化。
🔍 一、什么是 Attention?
Attention(注意力机制)是模拟人类注意力分配的一种方法。在处理输入序列时,模型可以“关注”某些更相关的部分。
举个例子:
假设你在翻译句子:
“The cat sat on the mat.”(猫坐在垫子上)
当模型翻译 “sat” 时,它可能会特别关注前面的 “cat”,而不是所有词都看一眼,这种“关注某一部分输入”的机制,就是 Attention。
🧠 二、Attention 的核心思路
对于每个词,我们用三个向量来表示它的含义和相互关系:
-
Query(查询):我想知道什么?
-
Key(关键):我拥有什么信息?
-
Value(值):我能提供什么内容?
通俗解释:
想象你在问一个班级问题(Query),每个学生都说:“我知道这些”(Key),还可以提供答案(Value)。你根据 Query 和每个 Key 的相似度,来决定更信任哪个学生(即给出更高权重),最后用这个权重加权他们的 Value。
📐 三、公式形式(Scaled Dot-Product Attention)

步骤说明:
-
计算 Query 和每个 Key 的点积(衡量相关性)
-
除以 dk\sqrt{d_k}dk 避免数值过大
-
使用 softmax 将相关性变成概率(注意力权重)
-
用这些权重加权每个 Value,得出最终输出
🎯 四、Self-Attention(自注意力)
在 Transformer 中,输入序列自己和自己做 Attention:
每个词的 Query 会与整个句子的 Key 和 Value 进行匹配,从而得到与其他词的依赖关系。
优点:
-
不受序列长度限制
-
可以并行处理
-
更好建模长距离依赖
🧠 Attention 的具体过程(用你的句子举例)
句子:
"The animal that barked loudly was a dog."
假设我们已经将它分词为:
["The", "animal", "that", "barked", "loudly", "was", "a", "dog", "."]
共 9 个 token。
现在我们只关注第 6 个词 "was" 来说明 Attention 是怎么工作的。

结果会是一个 9 维向量,比如:
| Token | 点积分数 |
|---|---|
| The | 1.2 |
| animal | 2.1 |
| that | 0.5 |
| barked | -0.2 |
| loudly | -0.7 |
| was | 1.0 |
| a | 0.9 |
| dog | 3.5 |
| . | 0.0 |
Step 3️⃣:对这些分数做 Softmax → 得到“注意力权重”
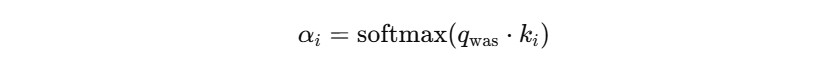
Softmax 会把这些变成 0~1 之间的权重,总和是 1:
| Token | Attention 权重 |
|---|---|
| The | 0.08 |
| animal | 0.12 |
| that | 0.05 |
| barked | 0.03 |
| loudly | 0.02 |
| was | 0.07 |
| a | 0.07 |
| dog | 0.55 ✅ |
| . | 0.01 |
Step 4️⃣:加权平均所有 Value 向量,得到 "was" 的新表示
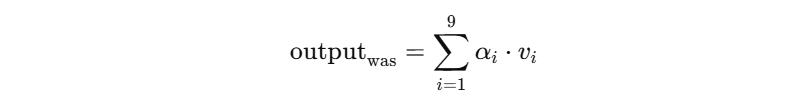
所以,最终 "was" 的表示是融合了所有词的信息,但重点融合了 "dog" 的语义,因为它的权重大(0.55)。
✅ 那 Attention 是不是“只关注一个最大的值”?
❌ 不是只关注最大的,而是加权所有的,只是有的权重大,有的小。
这种设计的好处是:
-
更稳定(不像 argmax 那样对噪声敏感)
-
可以同时关注多个有用的词(比如长句子中两个关键点)
📌 总结
| 你的理解点 | 纠正或补充 |
|---|---|
| 每个词会计算对别人的“值”吗? | ✅ 是的,Query 对所有 Key 做点积。 |
| 选出最大的那个? | ❌ 不选最大,是用 softmax 得到一组权重,对 Value 做加权求和。 |
| 用来干嘛的? | 得到每个词的新表示,融合了全局信息,能捕捉依赖关系。 |
🔑 V 向量的来源:
在 Transformer 的 Self-Attention 计算中,Value 向量 V 是从输入的词嵌入(词向量)中通过 线性变换 得到的。具体步骤是:
-
输入词向量(词嵌入):你有一个句子
"The animal that barked loudly was a dog.",每个词(例如"was")都会有一个原始的词向量(embedding),比如 512 或 768 维。 -
生成 Q、K、V 向量:
-
每个输入 token(词)的原始词向量都会通过 线性变换 来生成三个新的向量:Query (Q)、Key (K) 和 Value (V)。
-
这些变换是通过学习得到的权重矩阵(WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV)来完成的。
-
具体过程
-
输入:词嵌入矩阵 XXX
假设你已经把句子
X=[emb1emb2⋯emb9]X = \begin{bmatrix} \text{emb}_1 & \text{emb}_2 & \cdots & \text{emb}_9 \end{bmatrix}X=[emb1emb2⋯emb9]"The animal that barked loudly was a dog."转化为一个词嵌入矩阵 XXX,它的维度是:这里的 embi\text{emb}_iembi 是第 iii 个词的词向量,形状是 [1×768][1 \times 768][1×768],比如
The、animal等的词向量。 -
生成 Q、K、V 向量
通过三组权重矩阵 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV,每个词的词向量会被分别转换成 Query(Q)、Key(K)和 Value(V)向量:
Q=XWQQ = X W^QQ=XWQ K=XWKK = X W^KK=XWK V=XWVV = X W^VV=XWV这里的 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV 是可学习的权重矩阵,维度通常是:
WQ,WK,WV:R768×dW^Q, W^K, W^V: \mathbb{R}^{768 \times d}WQ,WK,WV:R768×d其中 ddd 是 Query、Key、Value 向量的维度,通常 d=64d = 64d=64 或 d=128d = 128d=128(这取决于你具体的 Transformer 模型和头数)。
-
具体的 Value 向量(V)
所以,Value 向量 VVV 就是通过上面的矩阵乘法得到的,它和原始的输入词向量在维度上是相同的,即每个词的 VVV 向量也是 768 维的(假设 hidden size = 768)。
🧩 举个小例子
假设我们只有一个句子 "dog barked",它被分词为:
-
["dog", "barked"]
每个词的原始词向量是:
ini
复制编辑
word_embedding_dog = [1.2, 0.3, 0.5, ..., 0.1] # 长度 768 word_embedding_barked = [0.4, 0.7, 0.1, ..., 0.2] # 长度 768
这两行分别是 dog 和 barked 的原始词向量(每个是 768 维)。
线性变换:
假设我们有一个简单的权重矩阵 WVW^VWV(维度:768 × 64),我们通过线性变换得到 Value 向量:
ini
复制编辑
V_dog = word_embedding_dog * W^V # 得到 [1 × 64] V_barked = word_embedding_barked * W^V # 得到 [1 × 64]
这两个向量分别表示 "dog" 和 "barked" 的 Value 向量,它们的维度是 64(通常 64 或其他较小的维度,因为在每个 attention head 中你通常会用较小的维度来计算注意力)。





