数据清洗中的利器:Tomek Link(邻域链接)详解与应用实战
一、引言
在处理机器学习中的分类问题时,我们经常会遇到数据不平衡或噪声数据过多的问题。尤其是在过采样(如SMOTE)或欠采样之前,如何对数据进行合理清洗,是影响模型性能的关键因素之一。
今天我们来聊一个处理类别边界噪声样本的经典方法——Tomek Link(邻域链接),并借助图解帮助大家轻松理解其原理和实际应用。
二、什么是 Tomek Link?
Tomek Link 是由 Ivan Tomek 提出的一个概念,用于清洗分类数据集中的边界样本。其核心目的是找出处于不同类别之间边界上的样本对,通常这些样本可能是:
-
噪声样本;
-
或对分类决策边界模糊不清。
图解理解
我们先来看一张经典的图示(来源:Chris Albon):
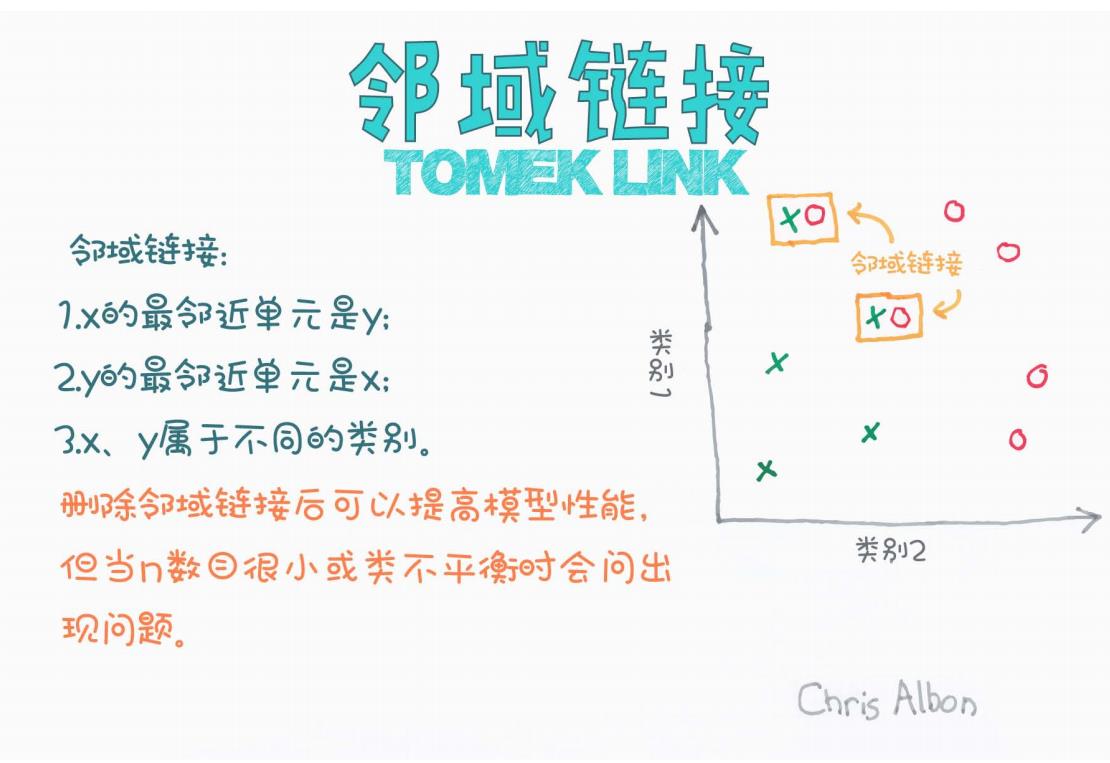
从图中可以看到:
-
类别1:绿色“×”;
-
类别2:红色“○”;
-
中间有一些“×”和“○”互为最近邻的点,构成了所谓的Tomek Link对。
三、Tomek Link 的定义
根据图中内容,Tomek Link 的定义有三个要点:
设有两个样本 x 和 y:
-
x 的最近邻是 y;
-
y 的最近邻是 x;
-
x 和 y 属于不同的类别。
满足以上三条规则的样本对就构成了一个 Tomek Link。
四、Tomek Link 的作用
Tomek Link 的主要作用是:
帮助识别边界样本或噪声数据,从而优化数据分布,提高模型的泛化能力。
常见操作:
-
删除 Tomek Link 中的“多数类”样本(常用于数据不平衡时);
-
或直接删除两个样本(如果数据量足够大,且边界噪声较多);
这样做的好处是:
-
消除类与类之间的模糊边界;
-
提高模型的判别清晰度;
-
降低过拟合风险。
五、Tomek Link 的局限性
虽然 Tomek Link 简单高效,但并不是在所有场景中都适用:
图中也提到:
-
当 数据量过小;
-
或 类别极度不平衡;
使用 Tomek Link 清洗可能会造成有价值样本的丢失,反而导致模型性能下降。
六、Tomek Link 实战(Python 示例)
借助 imbalanced-learn 库可以快速使用 Tomek Links:
from imblearn.under_sampling import TomekLinks
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt# 生成一个不平衡数据集
X, y = make_classification(n_samples=500, n_features=2, n_redundant=0,n_clusters_per_class=1, weights=[0.9, 0.1],flip_y=0, random_state=1)# 应用 Tomek Links
tl = TomekLinks(sampling_strategy='majority')
X_resampled, y_resampled = tl.fit_resample(X, y)# 可视化清洗前后
plt.scatter(X[y==0][:,0], X[y==0][:,1], label="Class 0", alpha=0.3)
plt.scatter(X[y==1][:,0], X[y==1][:,1], label="Class 1", alpha=0.3)
plt.title("Before Cleaning with Tomek Link")
plt.legend()
plt.show()
更多参数可参考 imbalanced-learn 官方文档。
七、Tomek Link 适用场景
| 场景 | 是否推荐 |
|---|---|
| 类别边界模糊 | ✅ 推荐 |
| 数据中包含噪声点 | ✅ 推荐 |
| 类别极不平衡 | ⚠️ 谨慎使用 |
| 样本总量很少 | ❌ 不推荐 |
八、总结
Tomek Link 是一个简单但实用的边界清洗方法,适合用于:
-
训练前的预处理阶段;
-
与 SMOTE 等采样方法联合使用;
-
分类任务中的边界优化。
在实际项目中,建议与模型调参、采样策略联合使用,以达到最优效果。
九、参考资料
-
Chris Albon 图解(原图作者)
-
imbalanced-learn 文档
-
《Imbalanced Learning: Foundations, Algorithms, and Applications》
你是否有在实际项目中用过 Tomek Link 或其他数据清洗技术?欢迎评论区一起讨论!





