1 .布隆过滤器提出
- 我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。
那新闻客户端推荐系统如何实现推送去重的?
- 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。
如何快速查找呢?
- .用哈希表存储用户记录,缺点:浪费空间
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了。
- 将哈希与位图结合,即布隆过滤器
2 .布隆过滤器概念
- 布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构。
- 特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,
- 它是用多个哈希函数,将一个数据映射到位图结构中。
- 此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
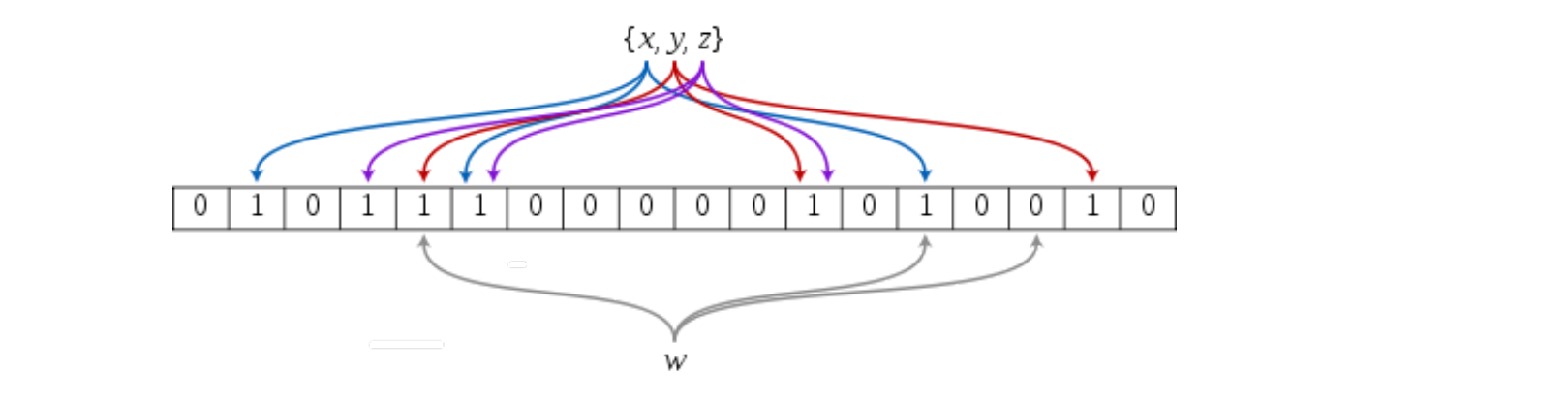
3 . 整体框架
- 整体还是使用了位图。其中这里可以放置多个哈希函数(这里我放3个),用了映射不同的概率。
哈希函数个数和布隆过滤器长度的关系:
m = -n*ln(p) / (ln(2)^2)
k = m/n * ln(2)
# k 为哈希函数个数
# m 为布隆过滤器长度
# n 为插入的元素个数
# p 为可接受该容器的误报率(0-1)- 当k=3时,m≈4.34n,所以这里我们选择m为5。
template<size_t N, size_t X = 5, class K = std::string, class hash1 = HashFuncBKDR, class hash2 = HashFuncAP, class hash3 = HashFuncDJB>
class BloomFilter
{ };这里找了3个优秀的字符串哈希函数:
struct HashFuncBKDR
{// @detail 本 算法由于在Brian Kernighan与Dennis Ritchie的《The CProgramming Language》// 一书被展示而得 名,是一种简单快捷的hash算法,也是Java目前采用的字符串的Hash算法累乘因子为31。size_t operator()(const std::string& s){size_t hash = 0;for (auto ch : s){hash *= 31;hash += ch;}return hash;}
};struct HashFuncAP
{// 由Arash Partow发明的一种hash算法。 size_t operator()(const std::string& s){size_t hash = 0;for (size_t i = 0; i < s.size(); i++){if ((i & 1) == 0) // 偶数位字符{hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));}else // 奇数位字符{hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));}}return hash;}
};struct HashFuncDJB
{// 由Daniel J. Bernstein教授发明的一种hash算法。 size_t operator()(const std::string& s){size_t hash = 5381;for (auto ch : s){hash = hash * 33 ^ ch;}return hash;}
};4 . 插入
与位图类似
- 先用不同的哈希函数计算出该数据分别要映射到位图的哪几个位置
- 然后把位图中的这几个位置设置为1
void set(const K& key)
{size_t a = hash1()(key) % M;size_t b = hash2()(key) % M;size_t c = hash3()(key) % M;_bf.set(a);_bf.set(b);_bf.set(c);
}5 .查找
- 布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。
步骤:
- 用不同的哈希函数分别计算出该数据分别要映射到位图的哪几个位置
- 判断位图中的这几个位置是否都为1,如果有一个不为1,说明该元素一定不在容器中,否则表示在容器中
bool test(const K& key){size_t a = hash1()(key) % M;size_t b = hash2()(key) % M;size_t c = hash3()(key) % M;return _bf.test(a) && _bf.test(b) && _bf.test(c);}- 布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
- 比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7 刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
6 .删除
- 布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
- 也就是说,要删除的元素映射的位置可能会是其它元素映射的位置。
- 所以直接删除元素会给后期查找某个元素带来极大的误判。
解决:
可以考虑给把比特位(根据需求选择用多少个比特位)扩展成为一个小的计数器,插入元素时,给计数器加1,删除元素时,给计数器减1。当然这个肯定会带来更大的空间开销,牺牲了布隆过滤器的优势。
- 无法确认元素是否真正在布隆过滤器中
- 存在计数回绕(次数过多,会溢出)
7 .布隆过滤器优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
8 .布隆过滤器缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
9 .海量数据处理问题
哈希切割:
- 给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
- 与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?
1. 先创建1000个小文件A0-A999,然后计算i = hash(IP)%1000,i是多少,IP就进入编号为i的文件中。这样相同的IP就都进入了同一个文件中。先将一个小文件加载到内存中,依次读取放入unordered_map<string, int> 中,同时用一个pair<string, int> max记录当前出现次数最多的IP,然后不断更新记录当前的max,这样就得到出现次数最多的IP地址
2. 和上面的方法一样,这里用一个大小为K的堆来存储topK的IP
100亿个整数大约占用40G的空间,如果直接加载到内存中,空间肯定是不够的,所以我们这里可以考虑用位图来处理。
方案一: 改进位图,用两个比特位表示整数,用其中的三种状态00(没出现)、01(出现一次)和10(出现两次及以上)。消耗内存为:2*4*(2^32-1)/32 byte≈1G
方案二: 用两个位图同时操作,对应比特位无数据时,两个位图此处设为0,有一个数据时,将两个位图中一个设为0,一个设为1,有两个及以上数据时,两个位图中对于比特位都设置为1。消耗空间和上面那种方法一样,也是1G
方案一: 将文件1的整数映射到一个位图中,然后读取文件2中的数据,判断是否在位图中,在就是交集,消耗内存500M
方案二: 将文件1的整数映射到一个位图中, 将文件2的整数映射到另一个位图中,然后将两个位图进行按位与,与之后位图中为1的位就是两个文件的交集
和第一题思路一致,找出状态为00、01和10的即可,其中状态为11代表的是出现3次及以上。消耗内存为1G
布隆过滤器:
1. 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
query是一个查询语句的意思,一个query语句的大小平均约为30-60字节100亿个query大约占用300-600G。
- 方案一(近似算法): 将文件1的query映射到布隆过滤器中,读取文件2中的query,判断是否在布隆过滤器中,在就是交集,是交集的一定在里面。(缺陷:交集中的数会不准确,因为有些数会误判,混到交集里面,判断在是不准确的,判断不在是准确的)
- 方案二(精确算法):1.把文件1和文件2分别切分成A0、A1…A999和B0、B1…B999,两个文件分别切分成1000个小文件,然后将A0加载到内存放到unordered_set中,再依次和B0、B1…B999这1001个文件进行比较,然后加载A1到内存中,以此类推。用unordered_set的效率还是很高的,基本上是常数次。
2. 优化:哈希切分
不再使用平均切分,使用哈希切分,用公式:i = Hash(query)%1000。i是多少就进入编号为i的文件中。不同的query可能会进入编号不同的文件中,但相同的query一定会进入编号相同的文件中。
先将文件Ai加载到内存中,放到unordered_set中,然后读取Bi中query,判断是否在,在就是交集。这里只需要比较1000次,比上面那种方式比较次数少很多。





