第一题
515. 在每个树行中找最大值
首先是遍历每层的节点,将每一层最大值的节点的值保留下来,最后将所有层的最大值的表返回;具体的遍历每层节点的过程如上一篇故事;
综上所述,代码如下:
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/ class Solution {public List<Integer> largestValues(TreeNode root) {List<Integer> ret = new ArrayList<>();if(root== null) return ret;Queue<TreeNode> q = new LinkedList<>();q.add(root);while(!q.isEmpty()){int size = q.size();int tmp = Integer.MIN_VALUE;for(int i = 0;i<size;i++){TreeNode t = q.poll();tmp = Math.max(tmp,t.val);if(t.left != null)q.add(t.left);if(t.right != null) q.add(t.right);}ret.add(tmp);}return ret;} }

第二题
1046. 最后一块石头的重量
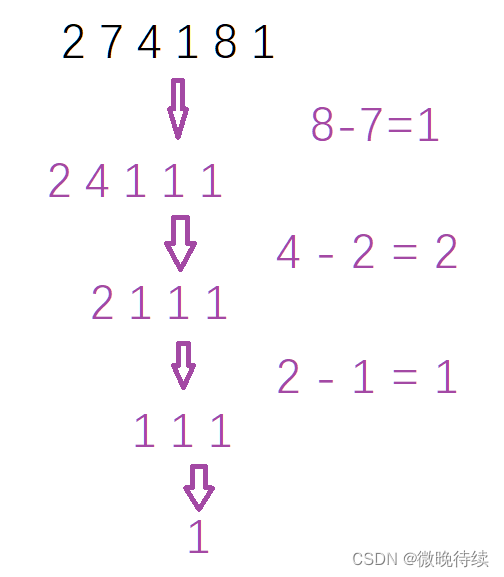
实例分析:
我们采用堆的解题方法;
创建一个大根堆,把所有的元素放入到大根堆里面;
每次返回堆顶的两个元素,得到两个数的差值在进入到大根堆里面;
最后只要大根堆的里面有元素就一直重复出堆相减的操作;
返回最后的数值即可;
综上所述,代码如下:
class Solution {public int lastStoneWeight(int[] stones) {//1、创建一个大根堆PriorityQueue<Integer> heap = new PriorityQueue<>((a,b) -> b-a);//2、把所有的石头放进堆里里面for(int x :stones){heap.offer(x);}//3、模拟while(heap.size()>1){int a = heap.poll();int b = heap.poll();if(a > b ){heap.offer(a-b);}}return heap.isEmpty()?0:heap.peek();} }


第三题
703. 数据流中的第 K 大元素
本题是top-k模型,解题思路如下所示:
创建一个长度为k的小根堆,然后开始往里面加入元素,一直等加入元素后小根堆的长度大于k值时,我们进行出堆操作,即将小根堆顶部的元素退出去,在进行入堆操作,就这样一直重复操作,直到所有的元素都进行过入堆操作,这时候返回的堆顶的元素即是我们所求;
综上所述,代码如下:
class KthLargest {PriorityQueue<Integer> heap;int k1;public KthLargest(int k, int[] nums) {k1 = k;heap = new PriorityQueue<>();for(int x : nums){heap.offer(x);if(heap.size() > k1){heap.poll();}}}public int add(int val) {heap.offer(val);if(heap.size() > k1){heap.poll();}return heap.peek();} }/*** Your KthLargest object will be instantiated and called as such:* KthLargest obj = new KthLargest(k, nums);* int param_1 = obj.add(val);*/
第四题
692. 前K个高频单词
解法:本题利用堆来解决top-k问题;
步骤:
步骤一:
预处理一下原始的字符串数组,即用一个hash表统计一下每一个单词出现的频次;
步骤二:
创建一个大小为k的堆:
频次不同:小根堆
频次相同时创建大根堆(字典序)
步骤三:
开始循环操作:
让元素依次进堆,判断条件,如果不满足条件的话就进行堆顶的元素出堆操作
步骤四:
根据实际情况对元素进行逆序操作
综上所述,代码如下:
class Solution {public List<String> topKFrequent(String[] words, int k) {//1、统计一下每一个单词出现的次数Map<String,Integer> hash = new HashMap<>();for(String s: words){hash.put(s,hash.getOrDefault(s,0)+1);}//2、创建一个大小为k的堆PriorityQueue<Pair<String,Integer>> heap = new PriorityQueue<>((a,b) -> {if(a.getValue().equals(b.getValue()))//出现频次相同的时候,字典按照大根堆的顺序排列{return b.getKey().compareTo(a.getKey());}return a.getValue() - b.getValue();});//3、top-k的主逻辑for(Map.Entry<String,Integer> e : hash.entrySet()){heap.offer(new Pair<>(e.getKey(),e.getValue()));if(heap.size() > k){heap.poll();}}//4、提取结果List<String> ret = new ArrayList<>();while(!heap.isEmpty()){ret.add(heap.poll().getKey());}//逆序数组Collections.reverse(ret);return ret;} }

ps:本次的内容就到这里了,如果对你有所帮助的话就请一键三连哦!!!






