ABC大脑架构:连接大模型与物理世界的具身智能新范式
在具身智能和类人机器人技术快速发展的背景下,如何高效整合“大模型的认知理解能力”与“对真实物理世界的精准控制”,成为当前智能体系统设计中最具挑战性也是最关键的问题之一。尽管大语言模型(LLM)在理解自然语言、推理任务目标等方面取得显著进展,但要让智能体“听得懂人话”之后还能“做出正确动作”,仍需要对感知、认知、规划与控制各个环节进行系统化设计与协同优化。
为应对这一挑战,“ABC大脑架构”应运而生。 “ABC大脑架构”作为一种从认知、规划到执行层级耦合与协同的设计理念,其核心思路是将系统划分为三个功能层级:
A(认知与感知层),负责信息获取与理解;
B(规划与决策层),进行语义解析、路径规划与动作生成;
C(控制与执行层),负责将抽象指令转化为可执行的物理动作。
本篇将聚焦于ABC大脑的整体设计理念,并深入解析其中的A(认知)与B(决策)模块。从大模型如何解析语言和多模态信息,到智能体如何基于这些理解生成动作计划,我们将逐步揭开“智能机器人如何理解世界并做出决策”的核心逻辑。
图片来源互联网
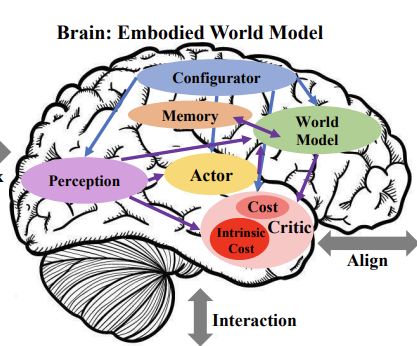
什么是ABC大脑?
它是构建具身智能系统的一种三层智能架构模型。
ABC大脑结构从“感知-认知”到“规划-决策”再到“控制-执行”,明确划分了机器智能从接收信息到行动反应的任务链条,是许多机器人系统(如LoCoBot、OpenLoong等)背后的系统设计基石。
🔹A:认知大脑(Cognitive Brain) 负责自然语言理解、多模态感知、语义解析与任务意图识别。它是机器人“理解世界”的入口,通常由大语言模型(LLM)、视觉语言大模型(VLM)等构建。
🔹 B:决策大脑(Decision Brain) 负责策略生成、动作规划与中间表示构建。它将认知输出转化为逻辑动作序列,常结合行为树(BT)、状态机、强化学习等实现,是智能体的“思维与计划”模块。
🔹 C:控制大脑(Control Brain) 负责具体执行与力反馈闭环控制,直接驱动电机、关节、机械臂等执行器完成动作任务,是机器人“实现行动”的末端神经网络。
图片来源互联网
ABC架构的系统分工与实现路径
A - 认知大脑(Cognitive Brain)
在具身智能系统中,A模块——“感知与认知层”承担着至关重要的任务:它不仅要理解用户输入的信息(包括自然语言、语音、图像等多模态数据),还需将这些输入进行结构化解析,提取关键意图并转化为机器人可执行的任务目标。这一环节是“听得懂人话”与“能正确执行”的桥梁。
在具体实现路径中,常见方案包括使用 Prompt Engineering 将输入引导为明确的任务目标,然后映射为中间表示(如 DSL、PDDL、Skill Tree 等动作语义结构),为后续的决策与控制提供语义基础。Google提出的 SayCan 框架 提供了一个经典案例:通过语言模型将自然语言映射为行为树(Behavior Tree),结合强化学习模块完成执行评估。
随着多模态大模型的持续发展与标准化中间语义层的推进,A模块正成为连接人类意图与机器执行之间最关键的桥梁,为具身智能从“能听懂”迈向“能听会动”奠定坚实基础。未来,这一层也将成为强化人机协作、提升自然交互体验的关键抓手。

图片来源互联网
B - 决策大脑(Decision Brain)
在具身智能系统的ABC大脑架构中,B模块,即“决策大脑”(Decision Brain),处于承上启下的核心地位。它接收来自A模块的结构化语义或用户意图,进一步将这些高层信息转化为低层可执行的动作计划。具体来说,B模块负责任务拆解、行为生成、动作组合与动态调整,是机器人“该怎么做”的关键中枢。

图片来源互联网
技术路径上,B模块的决策策略主要依赖两类方法:
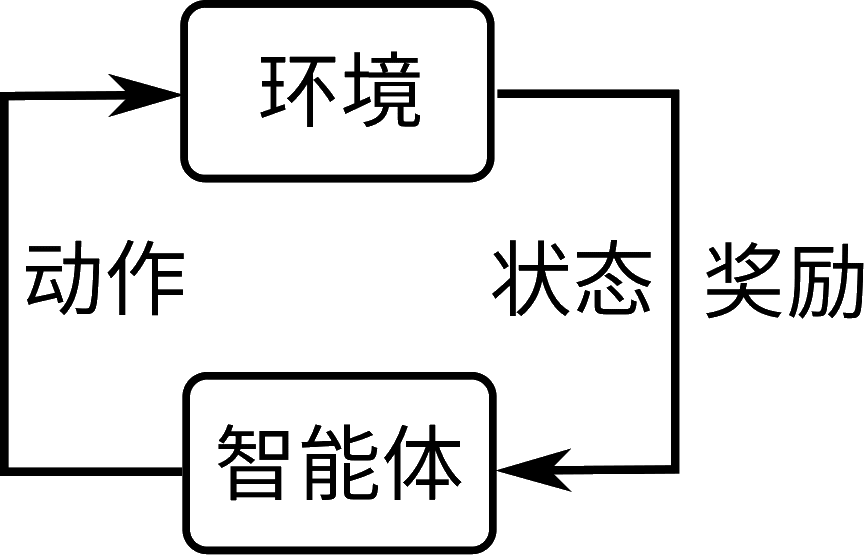
强化学习(Reinforcement Learning)
特别是离线强化学习(Offline RL)结合在线微调(Online Fine-tuning)的混合训练范式
模仿学习(Imitation Learning)
通过专家演示学习复杂任务结构
此外,还可以结合行为克隆、逆强化学习等技术强化泛化能力。
图片来源互联网
还可以使用行为规划器,目前主流方案包括:
行为树(Behavior Tree, BT)
层级清晰、可复用、适合复杂任务;
有限状态机(FSM)
状态驱动、适用于规则明确的系统;
潜在运动计划(Latent Motor Plans, LMP)
结合深度学习表示,适合在高维任务中进行压缩建模与泛化。
动作生成往往还需要中间语义表示的支持,例如“技能图谱(Skill Graph)”或“动作原语组合(Motion Primitives)”。

图片来源互联网
这些表示结构不仅便于任务复用,还利于将语言、图像等模态信息桥接到控制层。例如,开源具身智能套件 RoboSet 与 RoboHive 中就设计了模块化技能树,支持机器人在多任务环境下动态组合动作能力。另一个极具代表性的项目是 Google DeepMind 提出的 “Code as Policies” 框架。该方案将策略函数编码为结构化代码(如 Python 脚本或技能调用树),并通过语言模型生成或修正动作计划,从而实现了自然语言到机器人行为的高效转译和可控执行。这种做法为B模块提供了一种灵活、可解释、跨任务泛化的新范式。
总体来看,决策大脑的核心挑战在于如何在高维、多模态、延迟反馈的环境中做出稳定、可泛化的决策。随着强化学习、动作建模和行为规划器不断进化,B模块正从“离线可控”走向“在线自适应”,让机器人不只“看得懂”,也“做得对”,真正成为智能体的核心“思想者”。
通过对认知大脑(A)与决策大脑(B)的系统剖析,我们可以看到:一个机器人是否“聪明”,不仅取决于其语言理解和思维逻辑,更依赖于信息在感知与规划之间的顺畅流动。然而,能“听懂”和“会想”还远远不够——真正让机器人动起来、适应现实世界复杂动态的,是最底层的控制大脑(C)。
下篇内容将聚焦于“控制大脑”,探讨机器人如何将抽象动作计划转化为具体、稳定、实时的物理动作,并介绍最新的控制技术范式与端到端架构落地案例,欢迎继续关注《ABC大脑架构深度解析》的下篇内容!

"OpenLoong" 是全球领先的人形机器人开源社区,秉承技术驱动与开放透明的价值观,致力于汇聚全球开发者推动人形机器人产业发展。由国家地方共建人形机器人创新中心发起的 OpenLoong 项目,是业内首个全栈、全尺寸的开源人形机器人项目,有着人人都可以打造属于自己的机器人的美好愿景,旨在推动人形机器人全场景应用、助力具身智能时代的到来。
欢迎 加入 OpenLoong 开源社区,社区内将随时更新活动信息,上传技术文档。在这里,我们一起探索人形机器人技术,共享创新成果;在这里,我们一起见证开源的力量!





