摘要: 本文深入探讨 PyTorch 框架的核心组件之一——Autograd 机制。我们将解析其内部工作原理,包括计算图的构建、梯度的计算与传播,并探讨其在神经网络训练、模型调试及可解释性等方面的广泛应用。
通过理解 Autograd 的实现细节,开发者可以更高效地利用 PyTorch 进行深度学习研究与开发。
关键词: PyTorch, Autograd, 自动微分, 计算图, 梯度下降, 神经网络

1. 引言
PyTorch 作为一个广受欢迎的开源深度学习框架,以其灵活性和动态计算图的特性著称。其中,Autograd 模块是 PyTorch 自动计算梯度的核心引擎,它使得开发者能够专注于模型架构的设计,而无需手动推导和实现复杂的梯度计算过程。理解 Autograd 的工作原理对于优化模型性能、进行高效调试以及开发自定义功能至关重要。
2. Autograd 核心概念
在深入 Autograd 的实现细节之前,我们首先需要理解几个核心概念:
- Tensor (张量): PyTorch 中的基本数据结构,类似于 NumPy 的 ndarray,但增加了在 GPU 上进行计算的能力以及自动求梯度的支持。当一个 Tensor 的
requires_grad属性被设置为True时,Autograd 会开始追踪在该 Tensor 上进行的所有操作。 - Function (函数对象): 在 PyTorch 中,对 Tensor 的每一个操作都被视为一个函数(
torch.autograd.Function的子类实例)。这些函数对象不仅执行前向计算,还负责在反向传播时计算梯度。 - Computational Graph (计算图): Autograd 通过追踪 Tensor 上的操作来构建一个有向无环图 (DAG),这个图被称为计算图。图中的节点代表 Tensor,边代表 Function。当执行前向传播时,这个图被动态地构建起来。叶子节点通常是输入数据或模型参数,根节点是最终的输出(例如损失函数)。
- Gradient (梯度): 梯度表示函数在某一点上变化最快的方向,是优化算法(如梯度下降)更新模型参数的依据。对于一个 Tensor
x,它的梯度x.grad是一个与x形状相同的 Tensor,包含了损失函数相对于x中每个元素的偏导数。
3. Autograd 实现细节解析
Autograd 的核心功能可以概括为两个主要阶段:前向传播构建计算图和反向传播计算梯度。
3.1. 前向传播与计算图的构建
当一个 Tensor 的 requires_grad 属性为 True 时,PyTorch 会记录下所有作用于该 Tensor 的操作。每个操作都会创建一个 Function 对象,该对象知道如何计算其输出以及如何在反向传播时计算其输入的梯度。
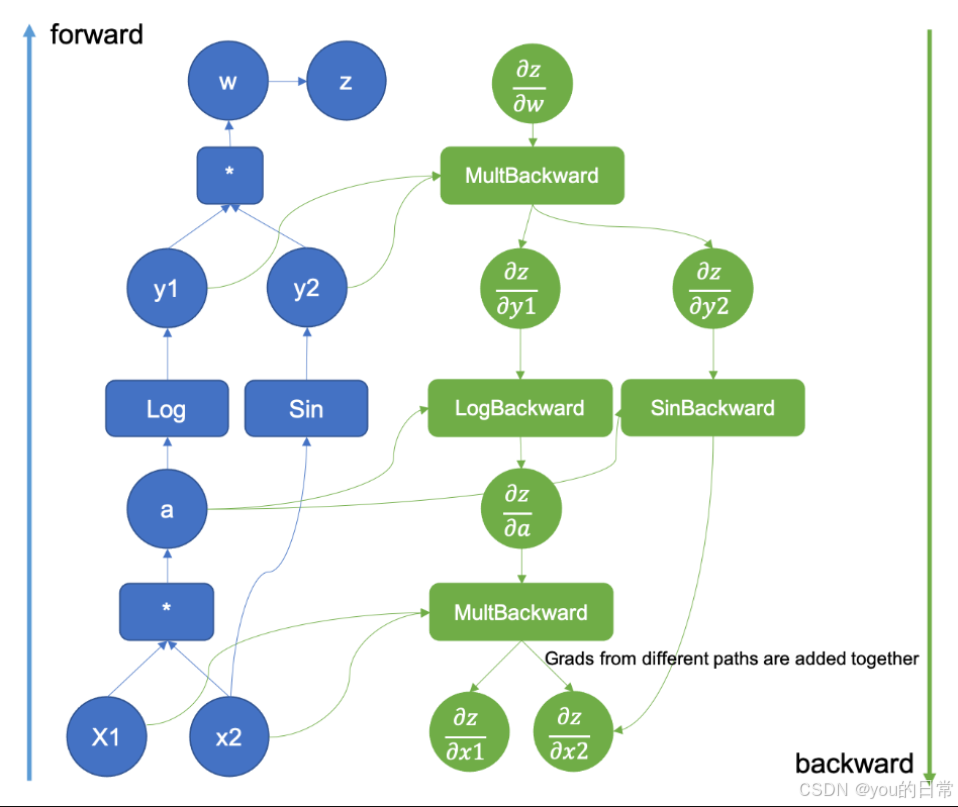
requires_grad属性: 这是 Tensor 的一个布尔型属性。如果一个 Tensor 的requires_grad为True,那么所有依赖于它的计算结果的 Tensor 的requires_grad也会默认为True(除非显式设置为False)。grad_fn属性: 每个由操作产生的非叶子节点的 Tensor 都有一个grad_fn属性,它指向创建该 Tensor 的Function对象。叶子节点的grad_fn为None。通过grad_fn,我们可以反向追溯整个计算图。- 动态图: PyTorch 的计算图是动态构建的。这意味着图的结构在每次前向传播时都可以发生改变。这为处理可变长度输入、循环神经网络等复杂模型提供了极大的灵活性。
示例:
import torch# 创建叶子节点 Tensor,并设置 requires_grad=True 以追踪计算
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
w = torch.tensor([0.5, 0.1, 0.2], requires_grad=True)
b = torch.tensor(0.1, requires_grad=True)# 定义一个简单的线性计算
z = torch.dot(x, w) + b # z = (x * w).sum() + b
loss = torch.sigmoid(z)# 查看 z 和 loss 的 grad_fn
print(f"z: {z}")
print(f"z.grad_fn: {z.grad_fn}") # <AddBackward0 object at 0x...>
print(f"loss: {loss}")
print(f"loss.grad_fn: {loss.grad_fn}") # <SigmoidBackward0 object at 0x...>
在上面的例子中,z 的 grad_fn 是 AddBackward0,表明 z 是通过一个加法操作得到的。类似地,loss 的 grad_fn 是 SigmoidBackward0。这些 grad_fn 对象连接起来构成了从 loss 回溯到 x, w, 和 b 的计算路径。
3.2. 反向传播与梯度计算
当我们在标量输出(通常是损失函数)上调用 .backward() 方法时,Autograd 开始进行反向传播,计算图中所有 requires_grad=True 的叶子节点的梯度。
-
.backward(gradient=None, retain_graph=None, create_graph=False)方法:gradient: 如果调用的 Tensor 不是标量,需要传入一个与该 Tensor 形状相同的梯度 Tensor 作为初始梯度。对于标量损失函数,此参数默认为torch.tensor(1.0)。retain_graph: 默认为False。在执行完反向传播后,计算图通常会被释放以节省内存。如果






