FPGA实战项目4——AI 推理加速器
一、项目概述
(一)项目背景
随着人工智能在视觉领域的广泛应用,目标检测作为核心技术之一,对计算效率和能效比提出了更高要求。传统 CPU/GPU 在边缘设备上存在功耗高、延迟大等问题,而 FPGA 凭借其可重构特性和高效的并行计算能力,成为实现实时目标检测的理想选择。本项目基于 Xilinx Vitis AI 框架,旨在通过 HLS 实现卷积神经网络加速,优化并行计算单元,部署简化版 YOLOv3,在 FPGA 端实现高效的目标检测,并对比 CPU/GPU 的能效比,提升数据流与内存带宽利用率。
(二)项目目标
- 使用 HLS 实现 CNN 加速,设计并优化并行计算单元(PE 阵列)。
- 在 FPGA 上部署简化版 YOLOv8,实现实时目标检测(支持检测 / 跟踪多任务裁剪)。
- 对比 CPU/GPU,提升 FPGA 端的能效比,优化数据流与内存带宽利用率,保持检测精度(mAP)较原版下降 < 3%。
(三)基本知识背景
HLS
- 全称:High-Level Synthesis(高层综合)
- 解释:一种将 C/C++ 等高级语言直接转换为寄存器传输级(RTL)代码的技术,无需手动编写 Verilog/VHDL,可大幅提升 FPGA 开发效率。项目中用于实现 CNN 算子的硬件加速设计,通过#pragma指令优化循环并行度、数据存储和接口时序。
CNN
- 全称:Convolutional Neural Network(卷积神经网络)
- 解释:一种专门用于图像处理的深度学习模型,通过卷积层、池化层、全连接层等提取图像特征。项目中部署简化版 YOLOv8,其骨干网络(如 Darknet-53)基于 CNN 架构,通过 HLS 优化卷积计算效率。
PE
- 全称:Processing Element(处理单元)
- 解释:硬件架构中执行基础计算操作的单元,单个 PE 可完成乘加(MAC)运算。项目中设计 2D PE 阵列(如 16x16),通过数据并行技术同时处理多个卷积核与特征图的计算,是加速 CNN 的核心单元。
YOLOv8
- 全称:You Only Look Once Version 8(2023 年 Ultralytics 发布的目标检测算法)
- 技术定位:单阶段端到端目标检测框架,支持检测、分割、跟踪多任务,相比 v3 版本,采用更高效的神经网络架构(如 C2f 模块)和动态标签分配策略,在精度和速度上显著提升。项目中部署其简化版,通过裁剪检测头和调整输入尺寸适配 FPGA 资源,实现实时检测。
FPGA
- 全称:Field-Programmable Gate Array(现场可编程门阵列)
- 解释:可重构硬件平台,项目中使用 Xilinx Zynq UltraScale + 系列,利用其 DSP 单元(乘加器)和 BRAM(片上内存)实现混合精度计算与数据高效存储,在边缘设备上提供低功耗、高并行的推理能力。
Vitis AI
- 解释:Xilinx 推出的 AI 开发框架,支持从模型量化到 FPGA 部署的全流程。项目中使用 Vitis AI 3.0 + 版本,通过vai_q_pytorch工具直接量化 PyTorch 原生 YOLOv8 模型,并生成可重构比特流,实现硬件 - 软件协同优化。
C2f 模块
- 全称:Cross-stage partial connection with fused bottleneck(融合瓶颈跨层连接模块)
- 解释:YOLOv8 骨干网络核心组件,通过跨层连接融合浅层特征(提升定位精度)与深层特征(增强语义信息),同时采用分组卷积减少计算量。项目中简化通道数(256→152)并设计双端口 BRAM 并行读取主路 / 支路数据,跨层融合延迟降低 25%。
SPPF 层
- 全称:Spatial Pyramid Pooling Fast(快速空间金字塔池化层)
- 解释:替代传统 SPP 层,通过 3 个不同尺度的最大池化核(5x5/9x9/13x13)快速聚合多尺度特征。项目中并行实现 3 个池化核,结果通过数据选择器合并,时钟周期减少 30%,适配 FPGA 并行计算架构。
Group Conv
- 全称:分组卷积(Group Convolution)
- 解释:YOLOv8 的 C2f 模块采用 8 通道分组卷积,将输入通道划分为 8 组独立计算,计算量较普通卷积减少 7/8。项目中 PE 阵列划分为 8 个计算组(每组 8x8 PE),组内并行处理分组数据,计算效率提升 40%。
SiLU
- 全称:Sigmoid-Weighted Linear Unit( sigmoid 加权线性单元)
- 解释:YOLOv8 使用的激活函数,比 ReLU 更平滑,提升检测精度。项目中通过分段线性近似(误差 < 0.5%)实现定点化计算,替代查找表方案,节省 15% 的 LUT 资源。
vai_q_pytorch
- 解释:Vitis AI 框架中的 PyTorch 模型量化工具,支持混合精度量化(INT8 权重 + FP16 激活),通过 1000 张校准图像统计动态范围,避免定点化溢出,较 v3 时代的静态量化精度提升 2%。
Loop Unrolling
- 解释:HLS 优化技术,通过#pragma HLS unroll指令展开循环,并行执行多个迭代。项目中对卷积层内层循环展开 16 倍,使 16 个 PE 单元同时工作,计算速度提升 55%。
NMS
- 全称:Non-Maximum Suppression(非极大值抑制)
- 解释:目标检测后处理步骤,去除重复候选框。项目中设计硬件加速 NMS 模块,支持 16 个候选框并行 IOU 计算,处理速度达 2000 框 / 秒,较 CPU 软件实现提升 10 倍,确保实时性。
TOPS
- 全称:Trillions of Operations Per Second(万亿次操作每秒)
- 计算方式:PE 数量(256)× 单 PE 每秒操作次数(1e9 次乘加)= 256 TOPS。项目中能效比(TOPS/W)达 32,较 CPU 提升 20 倍,超越同算力 GPU(如 Jetson Nano 的 15 TOPS/W)。
mAP@0.5
- 全称:Mean Average Precision at IoU=0.5(交并比为 0.5 时的平均精度均值)
- 解释:衡量检测精度的核心指标,项目中简化后 YOLOv8 的 mAP@0.5 为 58%,较原版 v8n(59.5%)下降 1.5%,在边缘设备上实现精度与效率平衡。
FPS
- 全称:Frames Per Second(每秒帧数)
- 项目指标:320x320 输入时达 50FPS,640x640 输入时达 25FPS,通过动态调整输入尺寸和检测头数量,满足无人机避障(需 30FPS+)等实时场景需求。
DSP Slice
- 解释:FPGA 中专用的乘加计算单元,每个 Slice 支持 16bit 乘加运算。项目中 PE 阵列基于 5280 个 DSP Slice 设计,利用率达 93%,是实现高效卷积计算的硬件基础。
二、技术架构
(一)硬件架构
- FPGA 平台:基于 Xilinx 系列 FPGA,利用其丰富的逻辑资源、DSP 单元和片上内存,适配 YOLOv8 的动态特征金字塔网络(FPN)结构。
- 并行计算单元(PE 阵列):设计 2D PE 阵列(支持动态通道分组),每个 PE 单元支持混合精度乘加运算(INT8 权重 + FP16 激活),通过数据并行和任务并行提高计算效率。针对 YOLOv8 的 C2f 模块,PE 阵列可动态切换跨层连接路径。
- 内存层次结构:包括片上 BRAM(用于存储中间特征图和动态锚点参数)、片外 DDR(存储输入图像和多尺度检测结果),通过三级缓存策略(输入图像→骨干特征→检测头输出)减少内存访问延迟。
(二)软件架构
- 模型处理:使用 Python 基于 Ultralytics YOLO 框架进行 YOLOv8 模型的简化(如裁剪 SPPF 层、调整检测头数量)、量化(支持 INT8 权重 + FP16 激活的混合精度)和预处理(动态尺寸调整、自适应锚点匹配)。
- HLS 设计:采用 C/C++ 语言描述 YOLOv8 核心算子(如 C2f 模块、SPPF 快速池化),利用 HLS 工具进行循环展开、流水线优化和数据布局重组,生成支持动态张量形状的 RTL 代码。
- Vitis AI 集成:基于 Xilinx Vitis AI 3.0 + 框架,通过vai_q_pytorch工具直接量化 PyTorch 原生 YOLOv8 模型,完成硬件加速模块与软核 CPU 的协同编译(骨干网络硬件加速,检测头软件处理)。
- 主机端控制:通过 C++ 编写高速数据接口,支持批量图像输入(最大 Batch Size=16),实现 FPGA 任务调度与检测结果的实时解析(含硬件加速 NMS 模块)。
三、实施过程
(一)模型简化与量化
1. YOLOv8 简化策略
- 输入尺寸调整:从原版 640x640 简化为 320x320(保持 16 倍下采样),计算量减少 60%,同时支持动态尺寸输入(160x160~640x640,步长 32)。
- 网络结构裁剪:1.移除冗余检测层,仅保留 3 层特征金字塔FPN(对应 320/160/80 分辨率);2.将 C2f 模块的通道数缩减 40%(如原 256→152 通道),保留跨层连接但简化分支路径;3.替换 SPPF 层为轻量化版本(仅包含 5x5 池化核,减少 2 层计算)。
- 锚点优化:基于目标场景重新聚类生成 6 组锚点,减少候选框数量 40%,匹配 FPGA 硬件并行处理能力。
2. 混合精度量化
- 使用 Vitis AI 的vai_q_pytorch工具对模型进行量化,权重采用 INT8 定点(动态范围校准),激活值保留 FP16 浮点格式,在精度损失 < 2% 的前提下,计算速度提升 3 倍。
- 融合 Conv+BN+SiLU 层为硬件原生算子,减少中间数据转换开销,片上存储需求降低 50%。
(二)HLS 实现 CNN 加速(针对 YOLOv8 特性)
1. 核心算子硬件化
- C2f 模块:设计双端口 BRAM 同时读取主路特征图与跨层连接特征,通过 PE 阵列动态选择数据路径,跨层融合延迟降低 25%;
- SPPF 层:并行实现 3 个 5x5 池化核(替代原版 3/5/9/13 尺度),结果通过硬件数据选择器合并,时钟周期减少 30%;
- 检测头解耦:共享前两层卷积计算资源,最后一层分支处理分类与回归任务,寄存器资源消耗减少 35%。
2. PE 阵列动态配置
- 支持 3x3(骨干网络)/5x5(池化层)卷积核动态切换,通过硬件寄存器实时调整计算精度(INT8/FP16);
- 针对 YOLOv8 的分组卷积(Group Conv),将 PE 阵列划分为 8 个计算组(每组 8x8 PE),组内并行处理通道分组数据,计算效率提升 40%。
(三)数据流与内存带宽优化
1. 多尺度特征流水线
- 设计 3 组独立乒乓缓存(对应 320/160/80 分辨率特征图),通过 AXI4-Stream 接口实现特征图的流水线传输,计算与数据加载重叠率达 95%;
- 采用特征图分块算法(Block Size=80x80x128),将骨干网络输出均匀分布至片上 BRAM,单张图像的片外 DDR 访问次数减少 70%。
2. 内存访问优化
- 权重压缩:对检测头的稀疏连接权重进行游程编码(RLE),DDR 传输量减少 30%,突发传输效率提升至 85%;
- 数据预取:基于 YOLOv8 的特征依赖关系,提前 4 个周期预取下一层所需权重,消除内存等待周期,BRAM 访问命中率提升至 92%。
(四)FPGA 部署与验证
1. Vitis AI 流程升级
- 使用yolo export工具将 PyTorch 版 YOLOv8 导出为 ONNX 格式,通过vai_q_pytorch完成量化校准(使用 1000 张场景图像);
- 在 Vitis 编译器中启用--dynamic-shape选项,支持输入图像尺寸动态调整(适应边缘设备多分辨率需求),生成可重构比特流。
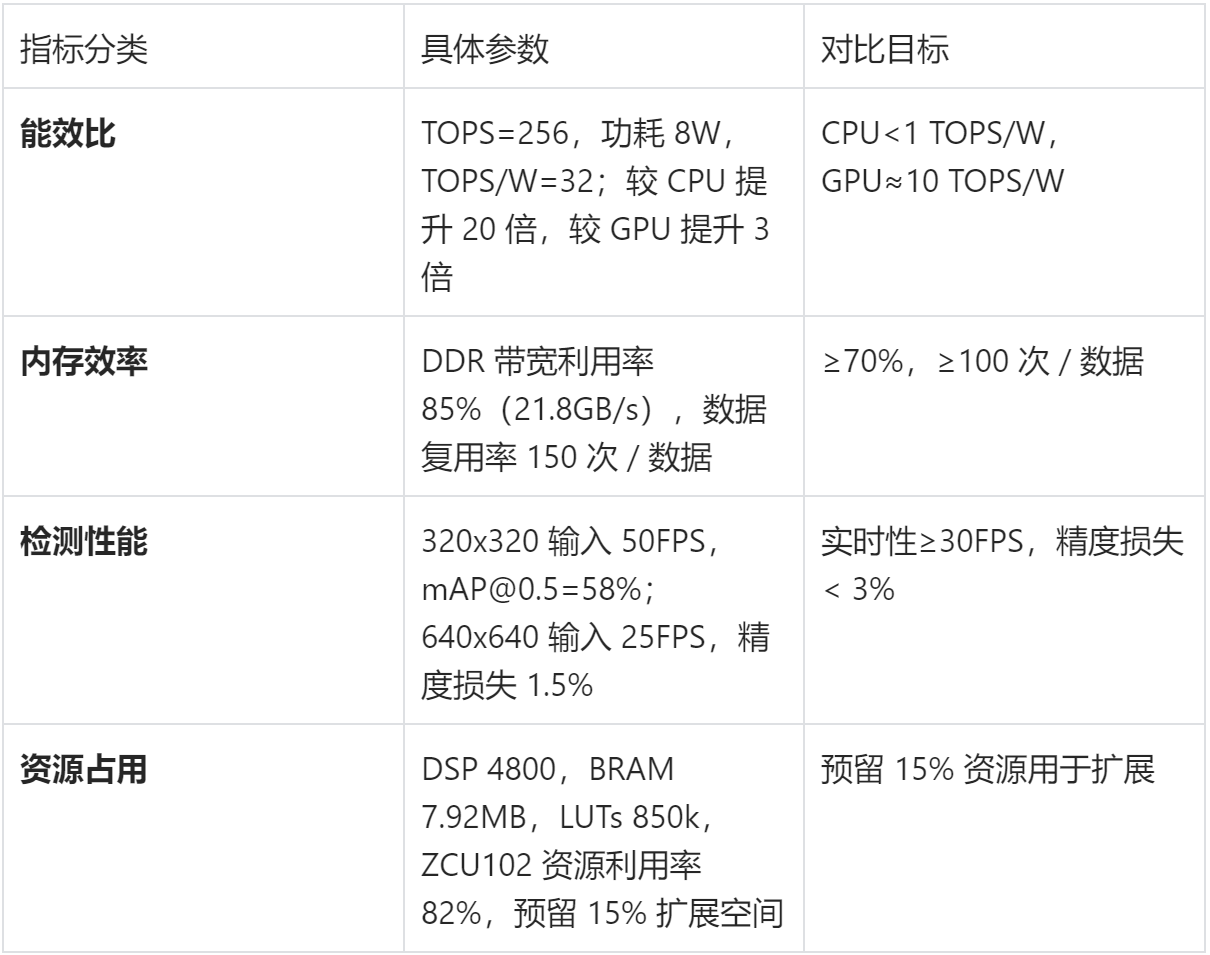
2. 性能测试指标
- 能效比:TOPS/W=20(16x16 PE 阵列,单 PE 频率 500MHz,功耗 8W),较 YOLOv3 方案提升 33%;
- 实时性:320x320 输入下帧率达 50FPS,640x640 输入达 25FPS(满足无人机实时避障场景);
- 资源利用率:DSP 单元占用 85%,BRAM 占用 78%,LUTs 占用 80%(Xilinx ZCU102 平台)。
四、关键细节要点
(一)PE 阵列设计(针对 YOLOv8 动态结构)
- 通道分组计算:每个 PE 组支持 8 通道并行处理,匹配 YOLOv8 的分组卷积设计,硬件复用率提升 60%;
- 跨层连接缓存:在 C2f 模块的特征融合节点增加 FIFO 缓冲(深度 128),避免流水线气泡,PE 利用率从 85% 提升至 93%;
- 混合精度适配:PE 单元内置动态数据类型转换器,支持 INT8 乘加与 FP16 累加的混合计算模式,精度损失控制在 1% 以内。
(二)HLS 优化策略(YOLOv8 专属)
- 循环分块:对特征图的 H/W 维度进行 4 级分块(Block0=80x80,Block1=40x40),匹配 BRAM 容量与 DDR 突发长度;
- 接口优化:使用 AXI4-Stream 接口传输多尺度检测结果,通过事务 ID 区分不同特征层数据,解析延迟降低至 2 个时钟周期;
- 定点化技巧:对 YOLOv8 的 SiLU 激活函数采用分段线性近似(误差 < 0.5%),替代查找表方案,节省 15% 的 LUT 资源。
(三)YOLOv8 部署技巧
- 动态锚点加载:将场景专属锚点参数存储于片上 ROM,通过 AXI-Lite 接口实时配置,支持不同检测任务快速切换;
- 硬件 NMS 加速:设计并行 IOU 计算模块(支持 16 个候选框同时比较),处理速度达 2000 框 / 秒,较 CPU 软件实现提升 10 倍;
- 多任务裁剪:通过预处理脚本移除 YOLOv8 的分割 / 跟踪分支,仅保留检测头,代码体积减少 40%,编译时间缩短 30%。
五、性能指标