1 线性表
1.2 单链表(Linked List)
顺序表在内存中是连续的进行存储,可以随机获取某个元素,但是在插入和删除元素的时候就非常不方便,需要移动很多相关的元素,链表就可以解决这个问题。
链表就是每个节点(Node)除了存储数据(书中称作数据域),还存储下一个节点的指针(书中称作指针域),此外还有一个头指向首元节点(第一个节点)。因为每个元素只有一个指针域,所以称为单链表(或者线性链表)。
赵钱孙李周吴郑王 这些姓氏在内存中用单链表存储的形式如下:
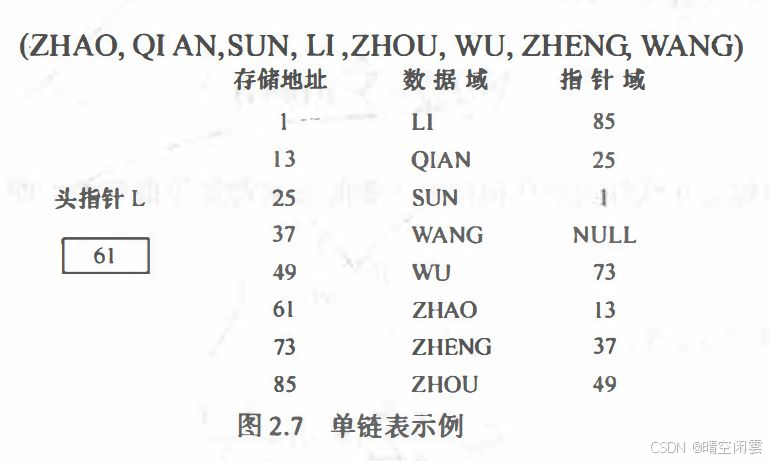
逻辑结构:
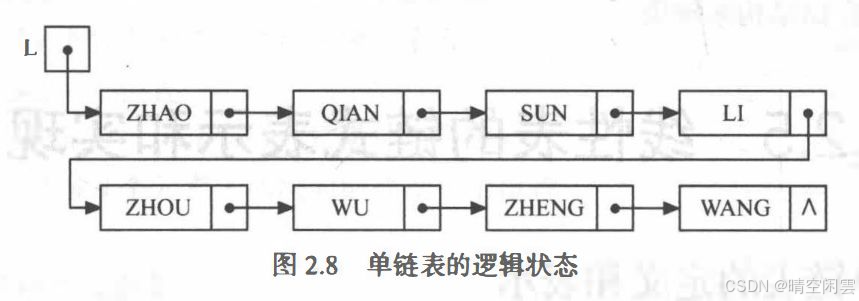
单链表的基本操作在王卓老师教程和书籍的基础上进行了增加了,另外因为在实际实现过程中,为了方便调试,顺序有做了一些修改,比如初始化单链表后,一般是要先插入一些结点,然后可以计算链表长度等,最后才进行销毁。这里实现的算法如下:
InitList(&L) // 初始化单链表
CreateListHead(&L, n) // 头插法创建单链表
CreateListTail(&L, n) // 尾插法创建单链表
GetElem(&L, i, &e) // 获取第i个结点,并用e返回
LocateELem(&L, &e) // 按值查找结点并返回位置,或者返回结点
ListInsert(&L, i, &e) // 插入结点,在 i-1 和 i 之间插入一个结点,新结点的位置就是 i
ListDelete(&L, i) // 删除结点,删除第 i 个结点
ListLength(&L) // 计算单链表表长度
ListEmpty(&L) // 判断单链表是否为空
ClearList(&L) // 清空单链表
DestroyList(&L) // 销毁单链表
在实现每个方法之前需要先定义单链表的节点:
// 声明 ElemType 的结构,链表中的每个结点存储的数据都是这个类型的。
// 这里为了简单方便,存储一个整数。在实际应用中,这里可以存储需要的数据。
typedef struct
{int x;
} ElemType;// 单链表的结点结构
typedef struct LNode
{ElemType data; // 结点数据,ElemType类型struct LNode *next; // 指向下一个结点的指针
} LNode, *LinkList; // LinkList 是指向 LNode 结构的指针类型,表示单链表的头结点指针
此外一些常量和顺序表类似:
// 声明一些常量
#define OK 1
#define ERROR 0
#define OVERFLOW -2
#define TRUE 1
#define FALSE 0// Status 是函数返回值类型, 其值是函数结果状态代码。
typedef int Status;
// Boolean 定义布尔型,值就是 TRUE 和 FALSE。
typedef int Boolean;
1.2.1 初始化
单链表的初始化操作就是构造一个空的单链表。
【算法步骤】
- 生成新结点作为头结点,用头指针
L指向头结点。 - 头结点的指针域置空。
【代码实现】
// 初始化链表
Status InitList(LinkList *L)
{*L = (LinkList)malloc(sizeof(LNode)); // 创建头节点if (*L == NULL){return OVERFLOW;}(*L)->next = NULL; // 初始化头节点的next指针为NULLreturn OK;
}
【算法分析】
非常容易看出,初始化算法的时间复杂度为 O(1) 。
1.2.2 头插法创建单链表
在初始化链表后,可以创建一些新结点插入到链表中,一种方法就是头插法,每次插入结点的时候,都放在头部,另外一种就是尾插法,每次插入的时候放在尾部。这节演示头插法,后面一节演示尾插法。
【算法步骤】
- 先初始化一个空链表。
- 根据要插入的结点数
n,重复执行n次(这里为了方便,每个结点的数据域为循环i的值)。 - 生成新结点,将
i值存入新结点的数据域中。 - 新结点的指针域指向头节点的指针域指向的结点。
- 头结点的指针域指向新结点。
【代码实现】
// 头插法创建单链表
Status CreateListHead(LinkList *L, int n)
{*L = (LinkList)malloc(sizeof(LNode)); // 初始化链表if (*L == NULL){return OVERFLOW;}(*L)->next = NULL; // 初始化头结点的next指针为NULLLNode *newNode; // 新结点指针for (int i = n; i > 0; i--){newNode = (LNode *)malloc(sizeof(LNode)); // 创建新结点if (newNode == NULL){return OVERFLOW;}newNode->data.x = i; // 设置新结点的数据newNode->next = (*L)->next; // 将新结点的next指针指向当前头结点的下一个结点(*L)->next = newNode; // 将头结点的next指针指向新结点}return OK;
}
因为是使用头插法,所以最后插入的元素在前面,因此这里使用 n ~ 1 的循环方式,保证链表存储的数据依次是 1 ~ n。
【算法分析】
创建多少个结点就要执行多少次创建新结点、插入到头部的操作,所以时间复杂度是 O(n) 。
[!NOTE]
其实这个方法可以结合初始化和插入结点的算法来做,这样代码会更加简洁,但是在视频教程中有提到这个,所以单独实现出来以供参考。
1.2.3 尾插法创建单链表
和头插法不同的地方就是新结点是插入在尾部。
【算法步骤】
- 先初始化一个空链表。
- 创建尾结点指针,一开始尾结点指向头节点。
- 根据要插入的结点数
n,重复执行n次(这里为了方便,每个结点的数据域为循环变量i的值)。 - 生成新结点,将
i值存入新结点的数据域中。 - 新结点的指针域设置为NULL,表示是最后一个结点。
- 尾结点的指针域指向新结点(就是将新结点接在尾结点之后)。
- 将新结点设置为尾结点,继续下一轮循环。
【代码实现】
// 尾插法创建单链表
Status CreateListTail(LinkList *L, int n)
{*L = (LinkList)malloc(sizeof(LNode)); // 创建头结点if (*L == NULL){return OVERFLOW;}(*L)->next = NULL; // 初始化头结点的next指针为NULL// 创建尾结点指针,一开始尾结点指向头节点。LNode *tailNode;tailNode = *L;LNode *newNode; // 新结点指针for (int i = 1; i <= n; i++){newNode = (LNode *)malloc(sizeof(LNode)); // 创建新结点if (newNode == NULL){return OVERFLOW;}newNode->data.x = i; // 设置新结点的数据newNode->next = NULL; // 将新结点的next指针设置为NULLtailNode->next = newNode; // 将当前尾结点的next指针指向新结点tailNode = newNode; // 更新尾结点为新结点}return OK;
}
【算法分析】
和头插法类似,时间复杂度是 O(n) 。
[!NOTE]
和头插法不太一样的一个点,就是要声明一个临时变量尾结点来记录每次插入的新结点。
1.2.4 获取第i个元素
和顺序表的随机存储方式,需要获取第i个元素,需要从头结点开始进行遍历,直到第 i 个元素。
【算法步骤】
- 通过头结点的
next可以获取到首元结点,从首元结点开始遍历。 - 定义循环,计数变量
j从1开始到i,每次循环获取当前结点的下一个结点(next)。 - 如果当前结点(
current)为NULL,则可以退出,表明链表并没有第i个元素。 - 验证当前结点(
current)是否为NULL,为空表示链表没有第i个元素,不为空则可以取到对应的元素(data)。
【代码实现】
// 获取第 i 个结点
Status GetElem(LinkList *L, int i, ElemType *e)
{if (i < 1) // i 值不合法return ERROR;LNode *current = (*L)->next; // 从头结点的下一个结点开始遍历int j = 1; // 计数器,从1开始while (current != NULL && j < i) // 遍历到第i个结点 并且 当前结点不为空{current = current->next; // 移动到下一个结点j++;}if (current == NULL || j > i)return ERROR;*e = current->data; // 获取第 i 个结点的数据return OK;
}
【算法分析】
该算法的基本操作是比较 j 和 i 并后移指针 current, while 循环体中的语句频度与位置 i 有关。若 1≤i≤n 则频度为 i - 1, 一定能取值成功;若 i>n 则频度为 n, 取值失败。 因此最坏时间复杂度为 O(n)。
为什么若 i>n 频率为 n ?这里可以具体分析循环体内执行的次数,假设 n = 2,i = 4:
j = 1:while循环条件都满足,循环体代码执行,执行后current指向第2个结点,j=2。j = 2:while循环条件都满足,循环体代码执行,执行后current指向第3个结点,j=3。j = 3:while循环条件不满足(current为NULL了),所以退出循环。
总计执行2次。
假设每个位置上元素的取值概率相等, 即:
P i = 1 n P_i=\frac{1}{n} Pi=n1
则:
A S L = 1 n ∑ i = 1 n ( i − 1 ) = n − 1 2 ASL = \frac{1}{n}\sum_{i=1}^{n}(i-1) = \frac{n-1}{2} ASL=n1i=1∑n(i−1)=2n−1
由此可见, 单链表取值算法的平均时间复杂度为 O(n) 。
1.2.5 按值查找
按值查找有两种实现方法:按值查找结点并返回位置 和 按值查找结点并返回结点指针。书籍上只实现了后一种,视频教程两种都实现了。
【算法步骤】
按值查找结点并返回位置:
current指向头结点的next,即首元结点,从首元结点开始遍历,并定义计数器i,即最后返回的位置。- 开始循环,循环条件为
current不为NULL。 - 如果循环条件满足,即
current不为NULL,则检验元素值是否和要查找的值相等,如果相等则返回i值,否则current置为下一个结点,并且将计数器i加1,继续下一轮循环。 - 如果
current为NULL,则可以退出,表明没有找到,最后返回0。
按值查找结点并返回结点指针 这个算法思路和上面类似,就是返回的找到的结点指针,而不是位置。
【代码实现】
// 按值查找结点并返回位置
int LocateELem(LinkList *L, ElemType *e)
{LNode *current = (*L)->next; // 从头结点的下一个结点(首元结点)开始遍历int i = 1; // 计数器,从1开始while (current != NULL) // 遍历到链表末尾{if (current->data.x == e->x) // 找到匹配的结点return i;current = current->next; // 移动到下一个结点i++;}return 0; // 没有找到匹配的结点
}// 按值查找结点并返回结点指针
LNode *LocateELem2(LinkList *L, ElemType *e)
{LNode *current = (*L)->next; // 从头结点的下一个结点(首元结点)开始遍历while (current != NULL) // 遍历到链表末尾{if (current->data.x == e->x) // 找到匹配的结点return current;current = current->next; // 移动到下一个结点}return NULL; // 没有找到匹配的结点
}
【算法分析】
该算法的执行时间与待查找的值 e 相关, 其平均时间复杂度分析类似 获取第i个元素 的算法,也是 O(n) 。
1.2.6 插入节点
将值为 e 的新结点插人到表的第 i 个结点的位置上, 单链表插入结点:
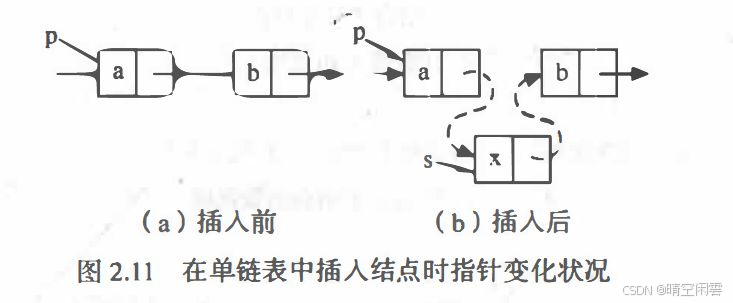
【算法步骤】
- 查找第
i - 1个结点并由指针current指向该结点。 - 生成一个新结点
*newNode。 - 将新结点
*newNode的数据域置为e。 - 将新结点
*newNode的指针域指向第i个结点。 - 将
current的指针域指向新结点*newNode。
【代码实现】
// 插入结点,在 i-1 和 i 之间插入一个结点,新结点的位置就是 i
Status ListInsert(LinkList *L, int i, ElemType e)
{if (i < 1) // i 值不合法return ERROR;LNode *current = *L; // 从头结点开始遍历int j = 0; // 计数器,从0开始,0其实就是表示头结点while (current != NULL && j < i - 1) // 遍历到第i-1个结点 并且 当前结点不为空{current = current->next; // 移动到下一个结点j++;}if (current == NULL || j > i - 1)return ERROR;LNode *newNode = (LNode *)malloc(sizeof(LNode)); // 创建新结点if (newNode == NULL)return OVERFLOW;newNode->data = e; // 设置新结点的数据newNode->next = current->next; // 将新结点的next指针指向当前结点的下一个结点current->next = newNode; // 将当前结点的next指针指向新结点return OK;
}
【算法分析】
单链表的插入操作虽然不需要像顺序表的插入操作那样需要移动元素,但平均时间复杂度仍为 O(n) 。这是因为为了在第 i 个结点之前插入一个新结点,必须首先找到第 i - 1 个结点, 其时间复杂度与 获取第i个元素算法 相同 ,为 O(n) 。
1.2.7 删除节点
删除单链表的第 i 个结点:
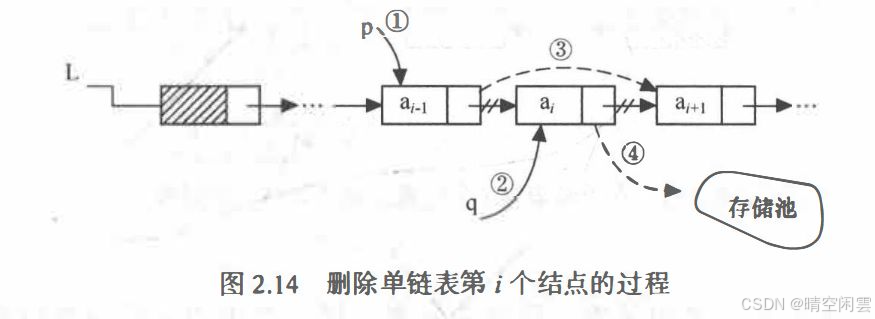
【算法步骤】
- 查找第
i - 1个结点,由指针current指向该结点。 - 临时保存待删除结点(第
i - 1个结点的后继结点就是待删除结点)在temp中,以备释放。 - 将结点
*current的指针域指向temp的直接后继结点。 - 释放结点
temp的空间。
【代码实现】
// 删除结点,删除第 i 个结点
Status ListDelete(LinkList *L, int i)
{if (i < 1) // i 值不合法return ERROR;LNode *current = *L; // 从头结点开始遍历int j = 0; // 计数器,从0开始,0其实就是表示头结点while (current != NULL && j < i - 1) // 遍历到第i-1个结点 并且 当前结点不为空{current = current->next; // 移动到下一个结点j++;}if (current == NULL || current->next == NULL || j > i - 1)return ERROR;LNode *temp = current->next; // 要删除的结点current->next = temp->next; // 将当前结点的next指针指向要删除结点的下一个结点free(temp); // 释放要删除的结点内存return OK;
}
【算法分析】
类似于插入算法,删除算法时间复杂度亦为 O(n) 主要就是要寻找到第 i - 1 个元素。
1.2.8 求链表的表长
【算法步骤】
- 用指针
current指向首元结点,初始化长度length为0。 - 开始循环,循环条件为:
current不为NULL。 - 如果
current不为NULL,则current指向current的后继结点,并将length加1。 - 如果
current为NULL,则退出循环,此时length就是单链表的长度,直接返回即可。
【代码实现】
// 计算单链表长度
int ListLength(LinkList *L)
{LNode *current = (*L)->next; // 从头结点的下一个结点开始遍历int length = 0; // 计数器,初始值为0while (current != NULL) // 遍历到链表末尾{current = current->next; // 移动到下一个结点length++;}return length;
}
【算法分析】
显然,因为要遍历一遍单链表,所以时间复杂度为 O(n) 。
1.2.9 判断空表
【算法步骤】
- 判断头节点指针域是否为空。
【代码实现】
// 判断单链表是否为空
Boolean ListEmpty(LinkList *L)
{if ((*L)->next == NULL)return TRUE;return FALSE;
}
【算法分析】
算法的时间复杂度为 O(1) 。
1.2.10 清空单链表
链表仍存在,但链表中无元素,成为空链表(头指针和头结点仍然在)。
【算法步骤】
- 用指针
current指向首元结点,指针temp用来临时指向后续不为空的结点。 - 开始循环,循环条件为:
current不为NULL。 - 如果
current不为NULL,则temp指向该结点,而后current指向current的后继结点,随后释放temp指向的结点内存。 - 如果
current为NULL,则退出循环,此时所有结点清理完毕,链表头指针的后继结点设置为NULL。
【代码实现】
// 清空单链表
Status ClearList(LinkList *L)
{LNode *current = (*L)->next; // 从头结点的下一个结点(首元结点)开始遍历LNode *temp; // 临时指针while (current != NULL) // 遍历到链表末尾{temp = current; // 保存当前结点current = current->next; // 移动到下一个结点free(temp); // 释放当前结点内存}(*L)->next = NULL; // 清空链表,头结点的next指针指向NULLreturn OK;
}
【算法分析】
因为要遍历一遍单链表,所以时间复杂度为 O(n) 。
1.2.11 销毁单链表
和清空单链表不同,除了清空所有结点,头指针和头结点也需要清理掉。
【算法步骤】
- 用指针
current指向头结点,指针temp用来临时指向后续不为空的结点。 - 开始循环,循环条件为:
current不为NULL。 - 如果
current不为NULL,则temp指向该结点,而后current指向current的后继结点,随后释放temp指向的结点内存。 - 如果
current为NULL,则退出循环,此时所有结点(包含头结点)清理完毕,将单链表*L设置为NULL。
【代码实现】
// 销毁单链表
Status DestroyList(LinkList *L)
{LNode *current = (*L); // 从头结点开始遍历LNode *temp; // 临时指针while (current != NULL) // 遍历到链表末尾{temp = current; // 保存当前结点current = current->next; // 移动到下一个结点free(temp); // 释放当前结点内存}*L = NULL; // 清空链表,头结点指针置为NULLreturn OK;
}
【算法分析】
因为要遍历一遍单链表,所以时间复杂度为 O(n) 。
另外因为前面有了清空算法,可以在清空单链表的基础上,继续清理掉头结点就可以了。
// 销毁单链表
Status DestroyList(LinkList *L)
{ClearList(L); // 清空链表free(*L); // 释放头结点内存*L = NULL; // 将头结点指针置为NULLreturn OK;
}






