- 元组
- 可迭代对象
- os模块
作业:对自己电脑的不同文件夹利用今天学到的知识操作下,理解下os路径
1.元组
在day3的打卡内容中就介绍了元组,跟列表比起来就是用了圆括号,有序可以重复,这一点和列表一样,但元组中的元素不能修改,是四种数据结构中唯一不可变的,这一点非常重要,深度学习场景中很多参数、形状定义好了确保后续不能被修改(其实括号都无所谓,逗号才是元组的真正标记)
这里提一下元组,主要是昨天pipeline()的定义中,接受的类是包含多个小元组的列表,元组用于将每个步骤的名称和处理对象捆绑在一起,列表定义执行步骤的先后,之后可以对列表进行修改,再强调一下
# 管道按顺序执行以下步骤:
# - StandardScaler(): 标准化数据(移除均值并缩放到单位方差)
# - LogisticRegression(): 逻辑回归分类器
pipeline = Pipeline([('scaler', StandardScaler()),('logreg', LogisticRegression())
])2.可迭代对象
简单来说,一个可迭代对象就是指那些能够一次返回其成员(元素)的对象,让你可以在一个循环(比如 for 循环)中遍历它们
Python 中有很多内置的可迭代对象,目前我们见过的类型包括:
序列类型 (Sequence Types):
- `list` (列表)
- `tuple` (元组)
- `str` (字符串)
- `range` (范围)
集合类型 (Set Types):
- `set` (集合) - 集合是无序的,每次遍历迭代返回的顺序可能不同
字典类型 (Mapping Types):
- `dict` (字典) - 迭代时返回键,想返回值要写成dict.values(),想返回键对值要写成dict.items()
文件对象 (File objects)
生成器 (Generators)
迭代器 (Iterators) 本身
3.OS模块
Python内置的操作系统交互工具包,管理文件、目录、路径,以及进行一些基本的操作系统交互
在简单的入门级项目中,你可能只需要使用 pd.read_csv() 加载数据,而不需要直接操作文件路径。但是,开始处理图像数据集、自定义数据加载流程、保存和加载复杂的模型结构时,os 模块就会变得非常有用,好的代码组织和有效的文件管理是大型深度学习项目的基石。os 模块是实现这些目标的重要组成部分
import os # os是系统内置模块,无需安装,直接导入获取当前工作目录路径:
os.getcwd() # get current working directory 获取当前工作目录的绝对路径获取当前工作目录下的文件列表:
os.listdr() # list directory 获取当前工作目录下的文件列表文件路径拼接:
path_a = r'C:\Users\YourUsername\Documents'
path_b = 'MyProjectData'
file = 'results.csv'# 使用 os.path.join 将它们安全地拼接起来,os.path.join 会自动使用 Windows 的反斜杠 '\' 作为分隔符
file_path = os.path.join(path_a , path_b, file)# 现在路径为'C:\\Users\\YourUsername\\Documents\\MyProjectData\\results.csv'获取所有环境变量:(注意一下,os.environ是字典,是可迭代对象)
os.environ # os.environ 表现得像一个字典,包含所有的环境变量for variable_name, value in os.environ.items():# 直接打印出变量名和对应的值print(f"{variable_name}={value}")
# 你也可以选择性地打印总数
print(f"\n--- 总共检测到 {len(os.environ)} 个环境变量 ---")遍历一个目录树:
os.walk(top, topdown=True, οnerrοr=None, followlinks=False) 会为一个目录树生成文件名。对于树中的每个目录(包括 top 目录本身),它会产生一个包含三个元素的元组:
(dirpath, dirnames, filenames)
- dirpath: 一个字符串,表示当前正在访问的目录的路径
- dirnames: 一个列表,包含了 dirpath 目录下所有子目录的名称(不包括 . 和 ..)
- filenames: 一个列表,包含了 dirpath 目录下所有非目录文件的名称
举个例子,假如当前工作目录是`my_project`,`os.walk` 会首先访问起始目录 (`my_project`),然后它会选择第一个子目录 (`data`) 并深入进去,访问 `data` 目录本身,然后继续深入它的子目录 (`processed` -> `raw`)。只有当 `data` 分支下的所有内容都被访问完毕后,它才会回到 `my_project` 这一层,去访问下一个子目录 (`src`),并对 `src` 分支重复深度优先的探索
它不是按层级(先访问所有第一层,再访问所有第二层)进行的,而是按分支深度进行的。这种策略被称之为深度优先
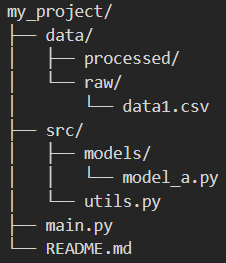
--- 开始遍历目录: my_project ---当前访问目录 (dirpath): my_project子目录列表 (dirnames): ['data', 'src'] # <--- 列出第一层子目录文件列表 (filenames): ['main.py', 'README.md']当前访问目录 (dirpath): my_project/data # <--- 深入到 data子目录列表 (dirnames): ['processed', 'raw'] # <--- 列出 data 下的子目录文件列表 (filenames): []当前访问目录 (dirpath): my_project/data/processed # <--- 深入到 processed子目录列表 (dirnames): []文件列表 (filenames): []当前访问目录 (dirpath): my_project/data/raw # <--- 回溯到 data,然后深入到 raw子目录列表 (dirnames): []文件列表 (filenames): ['data1.csv']当前访问目录 (dirpath): my_project/src # <--- 回溯到 my_project,然后深入到 src子目录列表 (dirnames): ['models']文件列表 (filenames): ['utils.py']当前访问目录 (dirpath): my_project/src/models # <--- 深入到 models子目录列表 (dirnames): []文件列表 (filenames): ['model_a.py']import osstart_directory = os.getcwd() # 假设这个目录在当前工作目录下print(f"--- 开始遍历目录: {start_directory} ---")for dirpath, dirnames, filenames in os.walk(start_directory):print(f" 当前访问目录 (dirpath): {dirpath}")print(f" 子目录列表 (dirnames): {dirnames}")print(f" 文件列表 (filenames): {filenames}")# # 你可以在这里对文件进行操作,比如打印完整路径# print(" 文件完整路径:")# for filename in filenames:# full_path = os.path.join(dirpath, filename)# print(f" - {full_path}")




