目录
一、MinerU概述
获取MinerU
二、核心功能与技术亮点
1. 多模态解析能力
2. 高效预处理能力
3. 多场景适配性
4. API服务
三、技术架构解析
3.1 概述
1. 模块化处理流程
2. 关键模型与技术
3.2 核心组件技术原理
3.2.1 布局检测(Layout Detection)
3.2.2 公式检测(Formula Detection)
3.2.3 公式识别(Formula Recognition)
3.2.4 OCR能力
3.2.5 表格识别(Table Recognition)
四、部署与使用指南
1. 本地部署(开发者模式)
1.1 本地部署 MinerU
1.2 硬件要求
1.3 容器安装运行
2. 客户端使用(非编程用户)
3. API服务(企业级)
五、应用场景与案例
1. 学术研究
2. 企业文档处理
3. 多语言内容管理
六、性能优化与社区生态
1. 版本迭代
2. 社区协作
七、横向对比与选型建议
7.1 三种类型解析工具
7.1.1 开源文档解析库
7.1.2 云端 API
7.2 MinerU vs Deepdoc
7.2.1 MinerU
7.2.2 Deepdoc
7.2.3 孰优孰劣
八、未来展望
资源汇总
参考资料
一、MinerU概述

在AI技术快速发展的今天,大量非结构化数据的处理成为亟待解决的问题。尤其是PDF文档,作为最常见的文件格式之一,如何高效准确地提取其中的信息,成为了许多企业和研究机构的痛点。上海人工智能实验室(上海AI实验室)大模型数据基座OpenDataLab团队开源了全新的智能数据提取工具——MinerU,旨在解决这一问题。
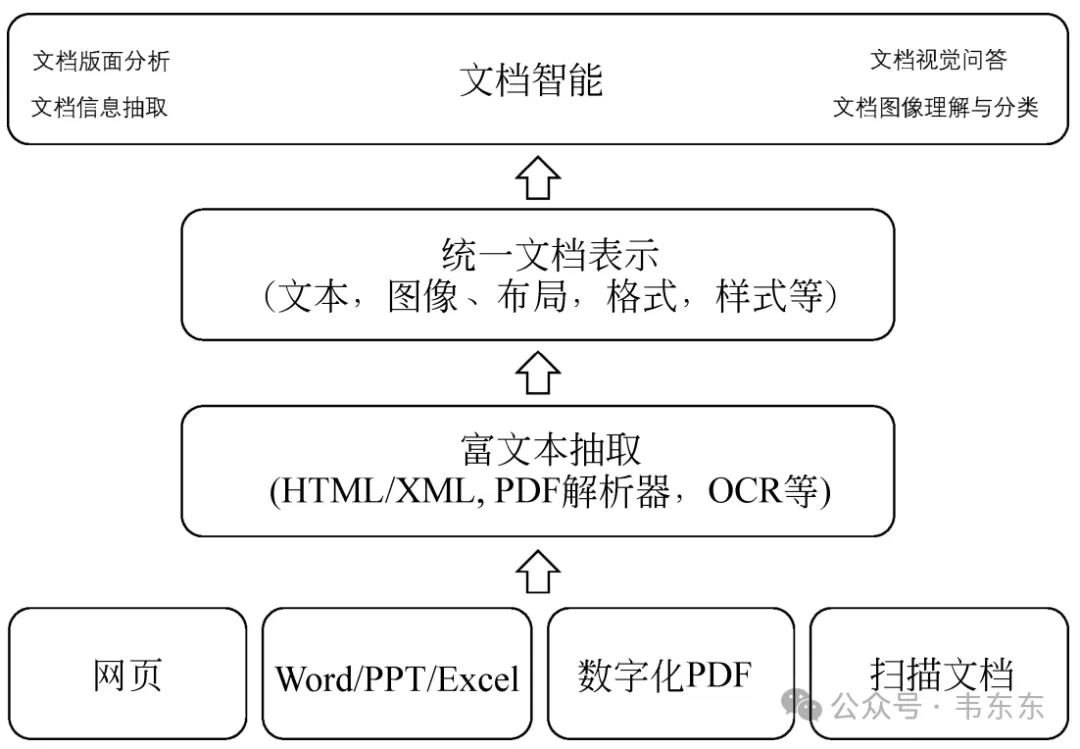
MinerU能够将混合了图片、公式、表格、脚注等复杂元素的PDF文档转化为Markdown和JSON格式,大幅提升了AI语料的准备效率。凭借快速准确、开源易用的能力特性,MinerU受到广大用户及大模型开发者青睐,上线八个月,GitHub星标数已接近3万,被开发者誉为"大模型时代的文档提取、转换神器"。
MinerU是由上海人工智能实验室OpenDataLab团队开发的开源文档解析工具,致力于解决大模型(LLM)训练和RAG(检索增强生成)应用中高质量结构化数据的提取难题。自2024年7月开源以来,GitHub星标数迅速突破2.5万,成为开发者社区的热门选择。其核心价值在于将复杂文档(如PDF、网页、电子书)转换为机器可读的Markdown、JSON格式,同时保留原始文档的语义逻辑与多模态元素。
获取MinerU
官方PPT:PDF 解析神器 MinerU.pdf
MinerU官网:MinerU
MinerU代码地址:GitHub - opendatalab/MinerU: A high-quality tool for convert PDF to Markdown and JSON.一站式开源高质量数据提取工具,将PDF转换成Markdown和JSON格式。
MinerU 线上demo入口:MinerU
MinerU 项目列表:MinerU/projects/README_zh-CN.md at master · opendatalab/MinerU · GitHub
医疗AI助手:GitHub - PancrePal-xiaoyibao/MinerU-xyb
二、核心功能与技术亮点
1. 多模态解析能力
- 精准元素提取:
支持文本、表格、图片、数学公式(LaTeX)、化学方程式等多模态内容识别。表格可转换为HTML/LaTeX格式,图片自动保存并关联标题。 - 智能版面分析:
适应单栏、多栏及复杂布局(如学术论文、杂志),通过DocLayout-YOLO和LayoutLMv3模型确保阅读顺序符合人类习惯。 - 多语言OCR:
内置PaddleOCR引擎支持176种语言,涵盖中文、英文、日文、俄语等,自动检测扫描版PDF并启用OCR。
2. 高效预处理能力
- 噪声去除:
自动过滤页眉、页脚、页码、脚注等干扰信息,保留核心正文内容。 - 语义连贯性:
通过段落拼接算法处理跨页、跨列文本,生成自然段落结构。
3. 多场景适配性
- 跨平台支持:
兼容Windows、Linux、macOS系统,支持CPU/GPU/NPU加速(推荐NVIDIA GPU显存≥8GB)。 - 灵活输出格式:
提供Markdown、JSON终端格式及中间态文件(如layout.json),适配RAG、知识图谱构建等需求。
4. API服务
MinerU在线API服务也对齐了MinerU开源项目最新release的1.0版本,提供了url&本地文件的批量解析、解析结果查询和下载、模型相关参数配置等能力。填写问卷申请通过后即可免费试用。得益于算力调度策略的持续优化和文档批量处理能力的增强,MinerU在处理多并发的大量文档时更加高效,无论是批量处理还是单个大体积文件,都能快速响应,为用户提供更为流畅、可靠的使用体验。
三、技术架构解析
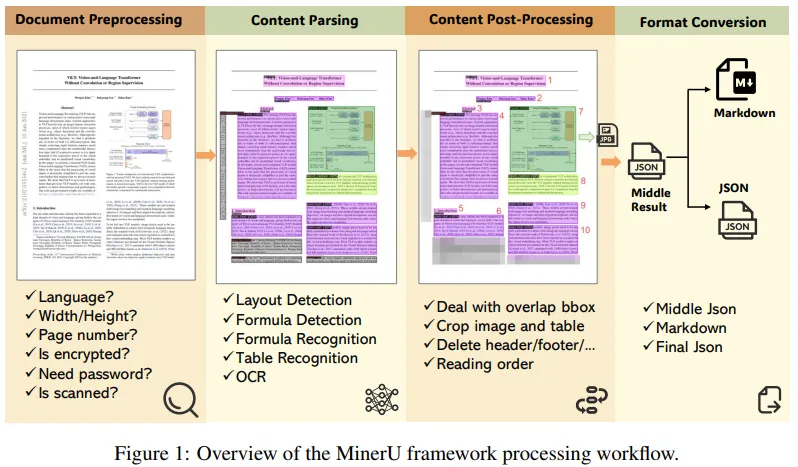
MinerU的技术架构整合了最先进的文档解析模型,涵盖了布局检测、公式检测、公式识别、OCR和表格识别等多个方面。以下是MinerU的核心技术组件:
3.1 概述
1. 模块化处理流程
- Layout Predict:识别文本块、图片、表格等区域。
- MFD/MFR Predict:检测并识别表格结构和公式内容。
- OCR-det/rec:文本行定位与OCR识别。
- 后处理:整合结果生成结构化输出。
2. 关键模型与技术
- 公式识别:基于UniMERNet模型,支持手写公式和复杂长公式。
- 表格识别:采用InternVL2-1B模型提升中文精度,支持HTML/LaTeX输出。
- OCR引擎:集成PaddleOCR,优化模糊、水印等复杂场景的识别鲁棒性。
3.2 核心组件技术原理
3.2.1 布局检测(Layout Detection)
MinerU使用微调过的DocLayout-YOLO和LayoutLMv3模型来定位文档中的不同元素,包括图像、表格、文本、标题和公式。这些模型经过多种PDF文档注释的微调,在论文、教科书、研究报告和财务报告等多样化PDF文档上实现了准确的提取结果,并在模糊和水印等挑战面前表现出高鲁棒性。

3.2.2 公式检测(Formula Detection)
MinerU使用微调的YOLOv8模型来定位文档中的公式,包括行内公式和块公式。这种高级的公式检测能力确保了数学内容能够被准确识别和提取。
3.2.3 公式识别(Formula Recognition)
MinerU使用UniMERNet模型进行公式识别,这是一种为现实世界场景中的各种公式识别而设计的算法。通过构建大规模的训练数据和精心设计的结果,它对复杂的长公式、手写公式和嘈杂的截图公式实现了出色的识别性能。

3.2.4 OCR能力
MinerU使用PaddleOCR进行文字识别。PaddleOCR是一个基于PaddlePaddle(百度开发的开源深度学习平台)的端到端光学字符识别(OCR)引擎,具有以下特点:
- 提供了从文本检测、文本识别到文本识别结果后处理的完整OCR流程
- 优化了模型结构和推理速度,使得它在保持较高识别精度的同时,还能在各种硬件上快速运行
- 支持多种语言的文字识别,包括中文、英文、法文、德文、日文和韩文等
- 集成了多种先进的文本检测和识别模型,如DB用于文本检测,CRNN和STAR-Net用于文本识别
- 提供了一系列预训练模型,用户可以直接使用这些模型进行文本识别
- 提供了详细的文档和示例代码,使得用户可以轻松上手,快速集成OCR功能到自己的应用中
3.2.5 表格识别(Table Recognition)
MinerU提供了两种表格识别方式:
- StructEqTable:这是一个高效的工具包,可以将表格图像转换为LaTeX/HTML/MarkDown。最新版本采用InternVL2-1B基础模型,提高了中文识别精度,并扩展了多格式输出选项。
- PaddleOCR+TableMaster:PaddleOCR首先在文档图像中检测文本行的位置,TableMaster专注于表格结构的识别,在文档图像中检测表格的存在并定位表格的边界。
在表格识别过程中,PaddleOCR提供精确的文本识别,而TableMaster负责识别和重建表格的结构。结合这两者,系统能够从图像中提取出完整的表格信息,包括表格的结构和内容。
四、部署与使用指南
1. 本地部署(开发者模式)
1.1 本地部署 MinerU
MinerU 作为 OpenDataLab 团队开发的智能数据提取工具,凭借多格式解析、多语言支持及复杂元素提取能力,成为开发者处理文档数据的利器。本地部署相比网页版或 API 调用,具有三大核心优势:
- 数据隐私保护:敏感文档无需上传至云端,避免数据泄露风险;
- 离线使用能力:无需依赖网络环境,适合内网或无网络场景;
- 性能自主优化:可结合本地硬件(如 GPU/NPU)深度调优,提升解析效率。
1.2 硬件要求
- CPU:建议 4 核及以上,支持 AVX 指令集(主流 CPU 均满足);
- GPU(可选):显存≥8GB(如 NVIDIA RTX 2060/AMD RX 6600),支持 CUDA/CuDNN 或华为昇腾 NPU,可大幅加速解析;
- 内存:至少 16GB(处理大文件时建议 32GB+);
- 存储:预留 50GB 以上磁盘空间(模型文件约占 20GB)。
# clone 源码
git clone https://gitee.com/ergmax/MinerU.git
cd MinerU
# 安装py环境
conda create -n MinerU python=3.10
conda activate MinerU
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com -i https://pypi.tuna.tsinghua.edu.cn/simple
# 配置文件
cp magic-pdf.template.json ~/magic-pdf.json
# 修改配置文件。安装完模型之后,自动会配置
# 下载模型:
pip install modelscope
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/scripts/download_models.py -O download_models.py
python download_models.py# 部署API
cd projects/web_api/
docker build -t mineru-api .
docker run --rm -it --gpus=all -v ./paddleocr:/root/.paddleocr -p 8000:8000 mineru-api配置magic-pdf.json: 配置文件会自动生成在用户目录下,文件名为magic-pdf.json。你可以根据需要修改配置文件中的功能开关
{"bucket_info": {"bucket-name-1": ["ak","sk","endpoint"]},"models-dir": "{path}/models", # 这里的path默认会是模型下载下来的路径,也可以挪动模型,修改路径"layoutreader-model-dir": "{path}/layoutreader","device-mode": "cpu", # 配置服务运行的基础环境,如果是cpu环境就配置cpu,如果是gup cuda,这里就配置为cuda"layout-config": {"model": "layoutlmv3" // 使用layoutlmv3请修改为“layoutlmv3"},"formula-config": {"mfd_model": "yolo_v8_mfd","mfr_model": "unimernet_small","enable": true // 公式识别功能默认是开启的,如果需要关闭请修改此处的值为"false"},"table-config": {"model": "rapid_table", // 表格识别默认使用"rapid_table"这个速度最快,可以切换为"tablemaster"和"struct_eqtable""enable": false, // 表格识别功能默认是开启的,如果需要关闭请修改此处的值为"false""max_time": 400},"config_version": "1.0.0"
}1.3 容器安装运行
在Linux环境中,MinerU也可以通过容器方式安装和运行:
- CPU容器环境
-
- 构建镜像:
docker build -t magic-pdf-cpu-test . - 运行容器:
docker run -d magic-pdf-cpu-test - 进入容器中,运行magic-pdf相关的命令,就可以使用CPU执行PDF提取
- 构建镜像:
- GPU容器环境
-
- 需要在GPU CUDA驱动的机器上构建容器镜像
- 构建命令:
docker build -t magic-pdf-gpu-test . - 运行容器:
docker run --rm --device nvidia.com/gpu=all --security-opt=label=disable -it magic-pdf-gpu-test - 进入容器后,可以使用GPU执行PDF提取
注意事项
- 模型下载:download_models.py脚本会自动下载所需的模型文件,确保网络连接正常。
- 配置文件:magic-pdf.json文件中的配置项可以根据实际需求进行调整,例如关闭某些功能以节省资源。
- Docker部署:如果使用GPU,请确保主机上已安装NVIDIA驱动(大于12.1)和CUDA,并且Docker已配置为支持GPU。
2. 客户端使用(非编程用户)
- 从官网下载Win/Mac/Linux客户端,拖拽文件即可解析PDF/DOC/PPT等格式。
- 支持导出Markdown、中间JSON及图片资源。
3. API服务(企业级)
- 在线API:支持批量解析与高并发处理,需填写问卷申请试用。
- 本地API:通过Docker部署,自定义数据处理流程:
docker build -t mineru-api .
docker run --gpus=all -p 8000:8000 mineru-api五、应用场景与案例
1. 学术研究
- 解析论文中的公式、图表及参考文献,构建结构化数据集和知识图谱。
- 案例:某医学团队提取10万篇论文中的化学方程式,训练领域大模型。
2. 企业文档处理
- 自动提取财报财务表格、研报多语言数据,提升金融分析效率。
- 案例:某投行通过MinerU将3000份PDF年报转换为JSON,数据分析耗时减少70%。
3. 多语言内容管理
- 处理国际化企业的多语言合同、手册,输出统一语料库。
- 案例:跨国电商平台实现英/日/俄语产品手册自动化翻译。
六、性能优化与社区生态
1. 版本迭代
- 0.10.0版本(2024/11):引入混合OCR技术,解析速度提升10倍。
- 1.0.0版本(2025/01):推出客户端与在线API,降低使用门槛。
2. 社区协作
- 探索者计划:鼓励开发者贡献技术文档或衍生应用,共建AI数据工具生态。
- 热门项目:医疗AI助手PancrePal整合MinerU实现病理报告解析。
七、横向对比与选型建议
| 工具 | 优势 | 不足 | 适用场景 |
| MinerU | 多模态解析、公式识别、开源免费 | 处理速度较慢(CPU环境) | 学术文献、复杂版式文档 |
| PyMuPDF | 轻量高效、支持Markdown表格 | 无公式识别、依赖AGPL协议 | 基础PDF处理 |
| Marker | 处理速度快(4倍于同类) | 复杂布局解析能力有限 | 技术文档快速转换 |
| Mistral OCR | 云端高精度(94.89%准确率) | 依赖网络、商业授权费用高 | 企业级批量处理 |
选型建议:
- 优先MinerU:需处理公式/表格/多语言、注重数据隐私。
- 补充PyMuPDF:需快速处理简单PDF且无需复杂元素提取。
更多对比
| 工具名称 | 核心优势 | 主要劣势 | 适用场景 | 开源/商业 |
| MinerU | ✅ 多模态解析(公式/表格/图表) | ❌ GPU要求高(推荐≥8GB) | 学术论文/技术文档/多语言材料 | 开源 (Apache 2.0) |
| Marker | ✅ 处理速度4倍于同类工具 | ❌ 复杂布局解析弱 | 简单PDF/快速文献处理 | 开源 (MIT) |
| Docling | ✅ IBM生态兼容 | ❌ 需CUDA环境 | 企业合同/报告自动化 | 混合(部分商业) |
| Markitdown | ✅ 格式支持最全(含EPUB/PPTX) | ❌ 依赖OpenAI API | 多格式内容创作/跨平台发布 | 开源 (部分付费) |
| OmniParse | ✅ Web终端操作便捷 | ❌ PDF公式识别错误率高 | 简单文档转换/非技术用户 | 开源 (GPLv3) |
| Llamaparse | ✅ RAG专项优化 | ❌ 处理速度慢(≈MinerU 0.5x) | 法律文件/技术文档分析 | 商业(SaaS) |
关键结论:
- 学术首选:MinerU在公式/多语言/多模态处理上表现最佳,适合研究机构
- 企业场景:Docling的IBM生态兼容性更优,但需权衡商业授权成本
- 开发友好:Marker+Markitdown组合可实现快速开发部署
- RAG专项:Llamaparse提供垂直优化,但需考虑API调用成本
综合来看,MinerU在多模态内容处理、公式识别转换等方面表现突出,尤其适合需要处理含有大量数学公式的学术文献或技术文档。同时,它支持GPU加速,使得在处理大规模文档时效率更高。相比之下,Marker更适合处理简单的PDF文档,而Docling则更倾向于企业级应用,特别是在需要与AI框架集成的情况下。每种工具都有其特定的应用场景和目标用户群,选择合适的工具取决于具体需求和个人偏好。例如,如果需要一个能够快速处理大量文档的解决方案,那么可能需要考虑Marker;而对于那些要求高精度解析和专业功能的项目,MinerU可能是更好的选择。
7.1 三种类型解析工具
在 RAG 流程中,文档解析是第一步,主要任务是将各种格式的原始文档转化为一种统一的、易于处理的中间格式。文档解析这一步的输出格式应该尽可能地通用和灵活,使得后续的分块、向量化等步骤不需要高度依赖于特定的解析工具或其内部实现细节。
除了以 Deepdoc 为代表的集成解析器外,还有开源文档解析库(MinerU 属于这种,后文单独介绍)和云端 API 两种。
7.1.1 开源文档解析库
Unstructured.io:专注于简化各种数据格式(包括图像和文本文件,如 PDF、HTML、Word 文档等)的摄取和预处理,以便用于大型语言模型 。它提供模块化的功能和连接器,可以无缝地协同工作,将非结构化数据高效地转换为结构化格式,同时还具有适应各种平台和用例的灵活性。
PyMuPDF: 是一款轻量级且高效的库,用于处理 PDF 文档、XPS 文件和电子书。它提供了提取文本、图像和元数据的功能,使得开发人员能够轻松地操作和分析 PDF 文档。PyMuPDF 基于成熟的 MuPDF 库开发,支持多种文档格式,并提供文档页面渲染、文本提取(包括 Markdown 格式)、表格提取、向量图形提取等功能 [25]。
Marker: 旨在快速准确地将文档转换为 Markdown、JSON 和 HTML 格式。它支持包括 PDF、图像、PPTX、DOCX、XLSX、HTML 和 EPUB 在内的多种文件格式,能够处理各种语言,并格式化表格、公式、链接、参考文献和代码块,同时还可以提取和保存图像,移除页眉页脚等干扰元素。Marker 尤其在处理书籍和科学论文方面表现出色,并且可以通过 LLM 来提高准确性 。
与使用集成解析器相比,集成和配置这些库 需要更多的开发工作 。某些库可能具有外部依赖项(例如 Unstructured.io 中的 Tesseract 用于 OCR),这些依赖项需要单独管理 。
另外需要考虑许可证的问题,不同的开源许可证对软件的发布和修改有不同的要求,某些许可证(例如 PyMuPDF 的 AGPL)可能会对商业使用产生影响,在特定条件下需要开源衍生作品 。
7.1.2 云端 API
云服务商提供的文档智能 API 也是文档解析的重要选择,它们通常具有高精度的 OCR 能力和处理大规模文档的潜力。

图片来自于Mistral OCR官网
Mistral OCR 是其中的一个典型代表 ,其他知名的服务商还包括 Google Cloud Document AI 和 Azure AI Document Intelligence 。根据 Mistral AI 分享的基准测试,Mistral OCR 的总体准确率达到了 94.89%,超过了 Google 的 83.42% 和 Azure 的 89.52% 。
Mistral OCR我也在测试过程中,后续会专门写篇文章结合案例进行介绍。
7.2 MinerU vs Deepdoc
说实话,我最早也是在知识星球内有星友提问才知道 MinerU 这个开源项目,之前是花了比较多时间研究 Deepdoc 和 PyMuPDF 的一些优化技术。 后来在公众号、B 站也搜到很多介绍 MinerU 的文章和视频。
我在常逛的 Reddit 的 RAG sub reddit 上也看到有用户评论称,在使用过 llamaparse、docling、pymupdf4llm、unstructured 等工具后,发现 MinerU 是迄今为止最好的 。在 GitHub 上,有用户表示 MinerU 提供了最佳结果,甚至可以识别公式,并且其表格解析和布局检测也更好 。

7.2.1 MinerU
MinerU是一款由上海人工智能实验室的大模型数据基础团队(OpenDataLab)开发的开源数据提取工具,专门用于高效地从复杂的 PDF 文档、网页和电子书中提取内容 。其设计目标是提供高质量的内容提取,并对包括图片、表格、公式等在内的多模态文档具有强大的处理能力 。

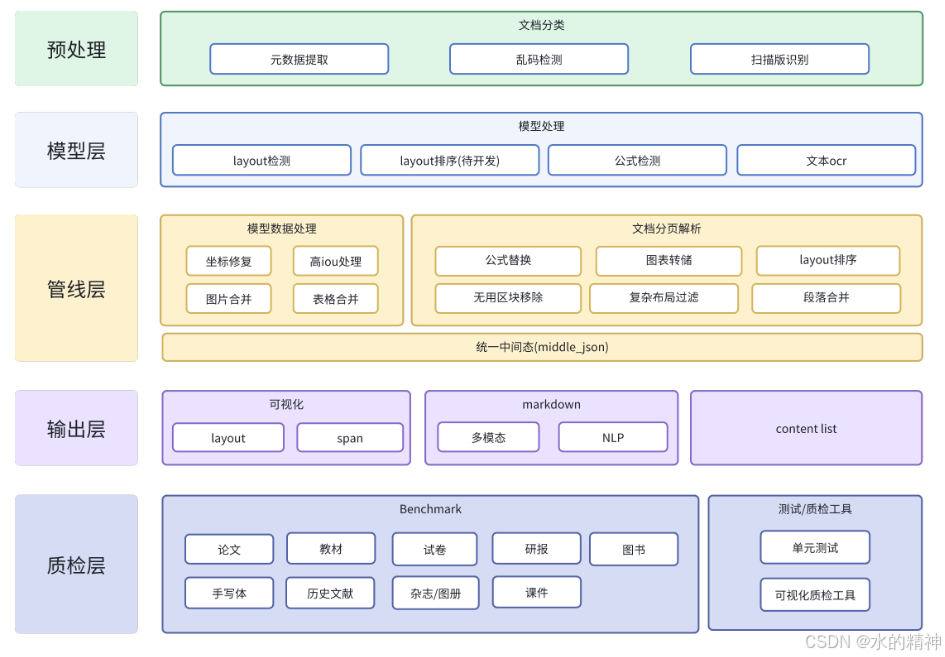
为了更好理解 MinerU 的工作原理,从上述命令行启动日志可以看到多个独立的“Predict”阶段,这表明 MinerU 的解析流程是分解成了多个步骤或模块。

图片来自于上海人工智能实验室的共享飞书文档,感兴趣的点击下方链接移步自取:https://aicarrier.feishu.cn/file/SknGbA2nqoYodbxNjYRcqeUsngf
Layout Predict (版面分析): 识别页面上的主要区域,如文本块、图片、表格、标题、页眉页脚等。这是后续处理的基础。

出处同上
MFD Predict (可能指 Master Feature Detection): 在版面分析的基础上,进一步检测特定对象,日志中紧随其后的是表格相关的步骤,因此这里很可能是专门的表格区域检测。
MFR Predict (可能指 Master Feature Recognition): 在检测到特定对象后,对对象内容进行识别或提取。紧随 MFD 之后,很可能是对检测到的表格区域进行结构和内容识别。
OCR-det Predict: 在文本块内,检测具体的文本行或单个字符的位置。
OCR-rec Predict: 对检测到的文本行或字符区域进行图像到文本的转换,即执行 OCR。
Table Predict (表格处理): 在 MFD 和 MFR 的基础上,进一步处理表格数据,可能包括结构化提取、单元格合并、跨页表格处理等。
Processing Pages (后处理): 整合所有步骤的结果,生成最终的结构化输出(如 Markdown, JSON 等)。
7.2.2 Deepdoc
RAGFlow 的文档解析核心组件被称为 DeepDoc。这并不是一个单一的黑箱,而是一个利用视觉信息和解析技术对文档进行深度理解的系统,其功能模块化地包含了多个部分,这与 MinerU 的模块化思路也是相似的,或者说是殊途同归。
DeepDoc 的主要解析逻辑和模块包括:
OCR: 将图片或扫描文档中的文字识别出来。支持多种语言和字体,并能处理复杂的布局和图像质量。这是基础步骤,将非文本内容转化为可处理的文本信息。
识别: 识别文档的整体布局和 结构,区分不同的内容区域,如标题、段落、表格、图像、页眉、页脚、公式等。这是理解文档结构的关键一步。日志中提到的 Layout Predict 在 DeepDoc 中也有对应的模块。

图片来自:https://github.com/infiniflow/ragflow/blob/main/deepdoc/README_zh.md
表格结构识别 : 专门针对检测到的表格区域,识别表格的行、列、单元格以及合并单元格等复杂结构,并将表格内容结构化提取(例如转换为 HTML 格式)。日志中的 MFD Predict 和 MFR Predict 对应 DeepDoc 的这一能力。
解析器: 针对不同类型的文档格式(如 PDF, DOCX, EXCEL, PPT, TXT, MD, JSON, EML, HTML, IMAGE 等),DeepDoc 提供了相应的解析器来处理。PDF 解析器通常需要结合上述的 OCR、版面分析和表格识别结果来还原文档内容和结构。

出处 同上
后处理: 在各个模块识别和提取信息后,需要进行后处理,例如合并段落、过滤分页信息、清理噪音内容(如页眉页脚、版权声明等),最终生成用于分块和向量化的文本及结构化数据。
对于 PDF 文档,DeepDoc的处理流程通常包括:文档转图片 -> 版面分析 -> 表格识别 -> 文字识别 -> 合并段落 -> 后处理。这个流程与从 MinerU 日志推断的步骤非常相似。此外,DeepDoc 还针对一些特殊文档类型提供了专门的处理逻辑,例如:
简历解析: 将简历这种非标准化文档解析为结构化数据字段(如姓名、工作经历等),而不是简单地分块。
特定格式分块: RAGFlow 提供了多种针对不同文档结构(如通用、问答、表格、论文、书籍、法律、演示文稿、图片、简历等)的模板化分块方法。这些方法会利用 DeepDoc 解析出的文档结构信息,按照更符合文档逻辑的方式进行切分,而不是简单的固定长度或标点符号分块。
7.2.3 孰优孰劣
DeepDoc 和 MinerU 在处理复杂文档时都采取了模块化、多步骤的策略,这是解决文档理解难题的一种常见且有效的方法。它们的主要差异可能在于各模块使用的具体算法、模型的训练数据、工程实现细节以及针对不同文档类型的优化侧重点。
关于优劣的具体对比,文档解析是一个复杂任务,不像图像分类有 ImageNet,文本识别有 ICDAR 等相对标准化的数据集。端到端的文档解析涉及到布局、文本、表格、公式等多种元素的识别和结构化,很难定义一个普适的评测指标和数据集来公平衡量所有系统。不同的文档类型(扫描、电子、复杂布局、多语言等)会导致评测结果差异巨大。
社区成员对解析效果的评价往往是基于他们在自己的文档集上的使用体验,而这些文档集往往具有特定行业的特点和固有的复杂性,某个系统在某个用户的特定文档集上表现更好,并不能代表它在所有文档集上都更好。

医学paper中的竖向表格识别的很好

医学领域的特殊符号也能正常解析

设备维保的PPT布局也能正常识别,而且自动去除了页眉和页脚
我在针对手头目前在做的两个设备维保场景和医学 paper 三个文档进行对比发现,MinerU 确实整体表现优异,但是也有些无法处理的情况。


从截图中可以明显看到表格中间部分的图片没有被MinerU正确识别。这是MinerU在处理某些特定情况下的一个局限性。这种情况可能有以下几个原因:
- 表格内嵌图片的识别挑战MinerU在处理嵌入在表格单元格内的图片时,有时会将其视为表格的一部分,而非独立的图像元素,这在复杂布局中是常见的挑战。
- 模型识别边界版面分析模型可能将表格整体作为一个单元处理,没有正确区分出表格中的图片区域与文本区域的边界。
- 图片质量和边界如果图片与表格边界融合得比较紧密,没有明显的分隔线或边框,模型可能难以正确区分。
不过我也检索了下MinerU的Github历史迭代记录, 他们确实提供了对这类问题的持续改进,但这个问题显然还没有解决的很彻底。

但是这个corner case实际通过PyMuPDF可以很好的被解决,具体请参考历史文章:RAGFlow框架优化经验分享(附代码):图文识别+动态分块 、API调优+源码修改


八、未来展望
随着多模态大模型需求增长,MinerU将在以下方向持续进化:
- 跨模态对齐:提升图文关联与语义理解能力。
- 低资源语言支持:扩展小语种OCR和布局模型。
- 实时协作:集成在线编辑与版本管理功能。
资源汇总
- GitHub仓库:https://github.com/opendatalab/mineru
- 在线体验:https://mineru.net/OpenSourceTools/Extractor
- 技术文档:https://aicarrier.feishu.cn/file/SknGbA2nqoYodbxNjYRcqeUsngf
通过本文,您已全面掌握MinerU的核心能力与应用场景。无论是学术研究、企业数字化转型,还是个人知识管理,MinerU都将成为您处理复杂文档的利器。
参考资料
MinerU
MinerU:大模型时代的高效文档解析与结构化工具
MinerU vs DeepDoc:集成方案+图片显示优化
【实用工具】MinerU 本地部署全攻略:手把手教你搭建专属文档解析平台
智能数据提取工具——MinerU详解及使用
趣软酷站|开源社区评价30.6K!从PDF到网页“大模型时代的文档提取、转换神器”- MinerU免费全能的文档解析神器
RAG项目必备!文档解析神器MinerU:2.5万星标!支持GPU加速,轻松应对复杂文档-CSDN博客
MinerU本地化部署教程——一款AI知识库建站的必备工具-CSDN博客
最新开源的解析效果非常好的PDF解析工具MinerU (pdf2md pdf2json)_windows_水的精神-AI Agent技术社区
PDF 解析神器 MinerU.pdf
MinerU × CAMEL-AI:一键PDF提取,助力多智能体跨文档协作与深度分析





