目录
引言
模型架构
Encoder:
Decoder:
Multi-Head Attention(多头注意力机制)
Feed Forward (实质为MLP)
Input Emdedding(词Emdedding+位置Emdedding)
总结优点缺点
代码实现
参考鸣谢
Transformer是Google在2017年的论文《Attention Is All You Need》中提出的。这是一个简单的架构,仅仅依赖于注意力机制,不依赖循环和卷积。主要用在机器翻译任务(序列转录模型)中,也就是自然语言处理(NLP)模型,英文翻译为德文或者法语,如下图所示。不仅如此,后期transformer也可以用在图像、视频等其他不是时序的数据上,成为了一种十分通用的模型。
这是《袋鼠书》作者Jay Alammar在他的transformer博客中的原图,博客中还有相关讲解视频(YouTube)。
引言
RNN 依赖时序信息(循环神经网络),transformer可以实现并行。卷积的局限性在于,每次卷积只能‘看到’一个小的窗口,两个相隔很远的元素需要多层卷积才能融合。
模型架构
序列转录模型通常包括一个encoder和decoder,下图左边为整体模型架构:
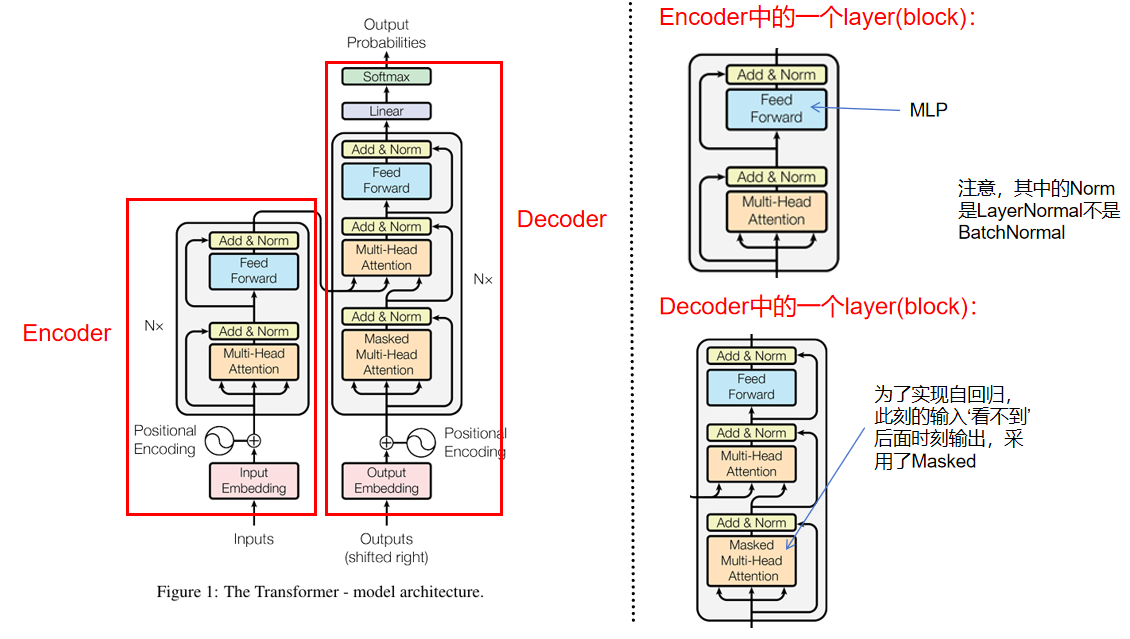
Encoder:
Encoder中的一个layer为右上所示,在transformer中重复N次(N=6),并不共享参数,里面有两个子层,第一个子层为Multi-Head Attention,第二个子层为前馈全连接层(MLP)。在两个子层都使用残差连接防止网络退化,后进行LayerNormal。每层逻辑公式为:。为了方便残差连接,模型中的所有子层的输出为
,(
=512)。
注:LN(LayerNormal)是在同一个样本中不同神经元之间进行归一化,而BN(BatchNormal)是在同一个batch中不同样本之间的同一位置的神经元之间进行归一化。
编码器中Multi-Head Attention的实际作用:
输入的向量(假设a个单词)首先经过一个Multi-Head Attention,自注意力层,可以实现对每个向量(单词)编码的时候关注一下其他向量(单词)。
Decoder:
Decoder中的一个layer为右下所示,在transform中重复N次(N=6),除了与编码器相同的两个子层外,还有一个Masked Multi-Head Attention,用于实现自回归模式(定义:过去时刻的输出作为当前时刻的输入)。同样每个子层都使用残差连接,后进行LayerNormal。
解码器中Multi-Head Attention的实际作用:
计算编码器输出的向量与已经解码的单词(解码器输入)之间的相关程度,以便找到更合适的翻译单词。
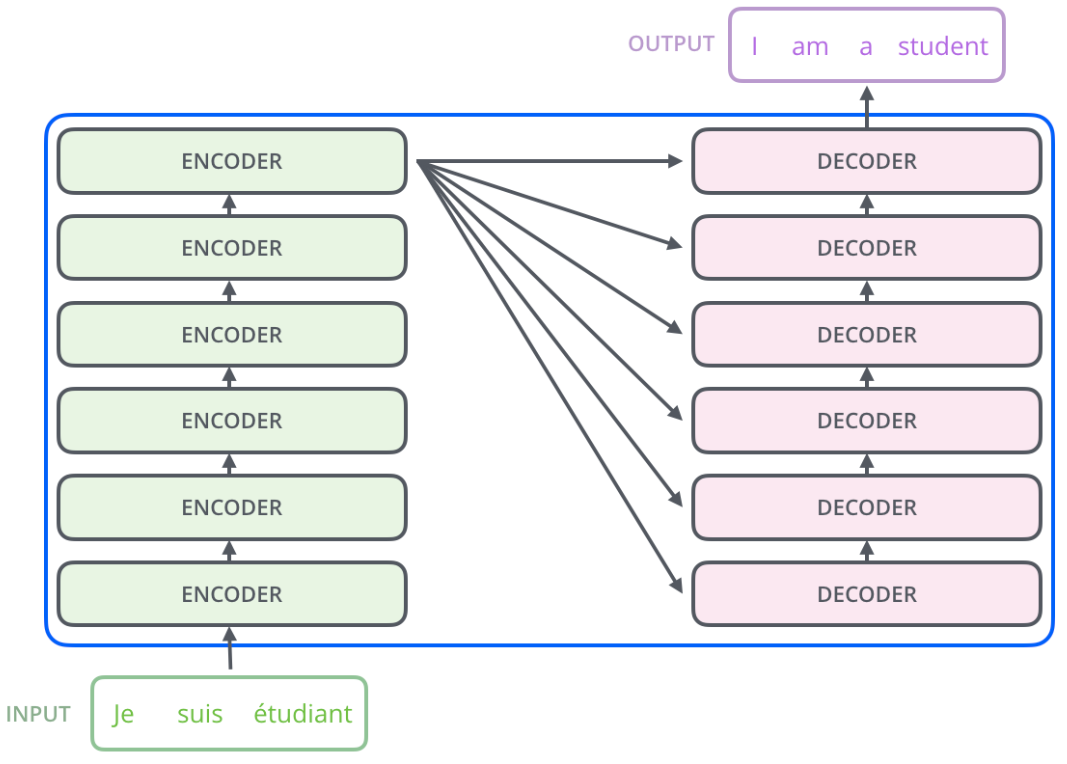
借用Jay Alammar的一张图来解释Encoder和Decoder之间的连接,最后一个Encoder block的输出都会进入每一个Decoder block作为一部分输入。Encoder block堆叠6层,你也可以尝试其他层数:
Multi-Head Attention(多头注意力机制)
在总体架构中,Encoder和Decoder都有一个Multi-Head Attention模块,Multi-Head Attention的模块内部如下图右边所示,类似卷积的多通道输出,这里的Multi-Head Attention输出h个通道。每个通道的计算都基于单个Scaled Dot-Product Attention模块,也就是Self-Attention(自注意力)模块。
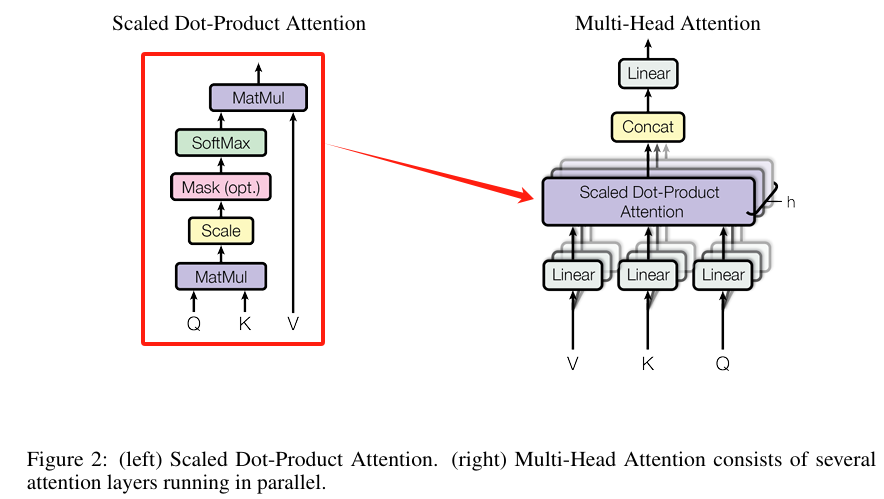
下面介绍下Self-Attention的内部逻辑,上图左边。输入是 (Query)、
(Key)、
(Value),都是向量,
和
的维度为
,
的维度为
。在实际中,可以计算多组,
为矩阵形式,整体计算公式为:
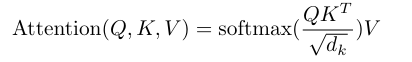
和
先计算内积后除以
(比例因子)后进入softmax作为权重,最后乘以
。其中除以
的目的在于如果
很大的话,一般内积也会很大,除以可以缩小值,避免过多值在softmax后,都落入为1和0的区域。
那为什么需要Multi-Head Attention呢?因为Self-Attention的计算过程并没有参数能进行学习。所以设计了Multi-Head Attention。先将经过线性映射(Linear层)h次(h=8),也就是学习h种模式,投影后为维度还是
(
=
=
=64)。这里就是我们经常听到的注意力头,也就是8个注意力头。再分别经过Self-Attention之后concat连接起来,最后进行一次投影。整体计算公式为:

其中,线性投影的参数矩阵为![]()
![]() 整个计算流程:
整个计算流程:
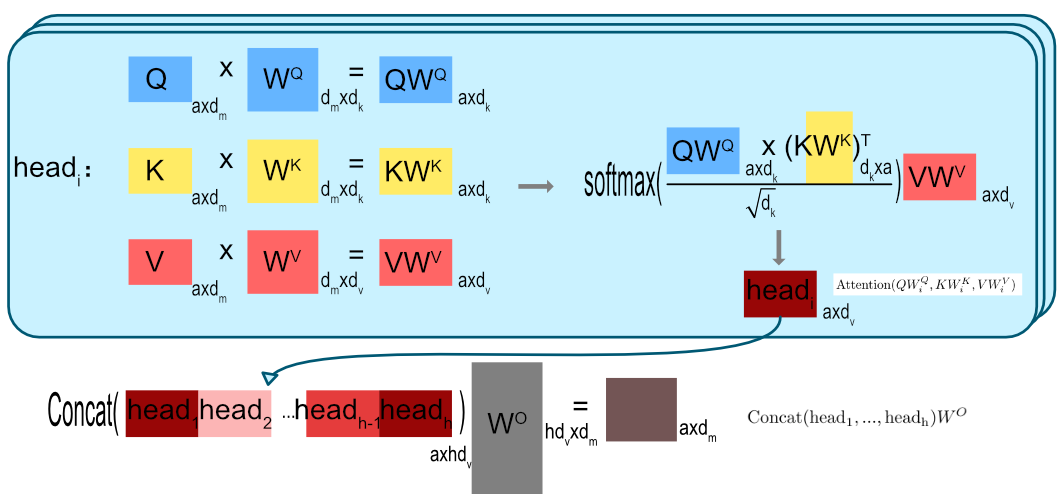
现在再看整体架构,Encoder中的Multi-Head Attention是基于Self-Attention,Decoder中的第二个Multi-Head Attention就只是基于Attention,它的输入Q来自于Masked Multi-Head Attention的输出,K和V来自于Encoder中最后一层的输出。
怎么实现Decoder中的Masked Multi-Head Attention,从而实现自回归呢?对于一个序列,在 t 时刻,解码器应该只能依赖于 t 之前时刻的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。做法:产生一个上三角全为0的矩阵,把这个矩阵作用在每一个序列上,就可以达到我们的目的。这在训练的时候有效,因为训练的时候每次我们是将target数据完整输入进decoder中地,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。
Feed Forward (实质为MLP)
Encoder和Decoder中都有Feed Forward层,其中包含两个带Relu激活的线性变换,具体公式为:
![]()
输入输出维度(=512),内层维度
(=2048)。
Input Emdedding(词Emdedding+位置Emdedding)
transform作为序列转录模型,输入由单词Emdedding和位置Emdedding(Positional Encoding)相加得到。单词的Embedding可以通过Word2vec(学习嵌入模型)预训练得到,将输入词元(token)和输出词元(token)转化为维度为的向量。Transformer 中除了单词的Embedding,还需要使用位置Embedding 表示单词出现在句子中的位置。这是因为transform没有递归和卷积,只看全局信息,如果将词的顺序打乱,输出的向量是一样的,这显然不对。位置Embedding用PE 表示,PE的维度与单词Embedding相同。可以通过训练得到,也可以使用某种公式计算得到。在Transformer中采用了后者,计算公式如下(可以理解为用维度为
的向量表示一个位置信息):
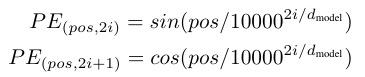
其中,pos表示单词在句子中的位置。设句子长度为 L ,则 pos=0,1,...,L−1;i 为向量的某一维度,例如 dmodel=512 时, i=0,1,...,512 。
为什么采用加,而不是concat?因为concat会造成维度升高。
总结优点缺点
缺点:
完全基于self-attention,对于词语位置之间的信息有一定的丢失,虽然加入了positional encoding来解决这个问题,但这导致需要大量的数据训练获得与RNN同样的效果。
代码实现
此为文章给出的代码链接,已经封装在Tensor2Tensor库里。“Tensor2Tensor是谷歌基于TensorFlow开发的一个非常好用的深度学习库,该深度学习库包含了很多方面的功能,适用于很多模型,包括图片分类、图片生成、问答系统、情感分析、语言模型等。”
tensorflow/tensor2tensor: Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.![]() https://github.com/tensorflow/tensor2tensor但是,我参考学习的是pytorch实现的版本:
https://github.com/tensorflow/tensor2tensor但是,我参考学习的是pytorch实现的版本:
Pytorch Transformer-CSDN博客![]() https://blog.csdn.net/qq_39906884/article/details/125275542
https://blog.csdn.net/qq_39906884/article/details/125275542
参考鸣谢
袋鼠书作者Jay Alammar对于Transformer的讲解![]() https://jalammar.github.io/illustrated-transformer/
https://jalammar.github.io/illustrated-transformer/






